 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Models Improve Visual Robustness in Robotic Learners
Apr 29, 2024



Visual control policies can encounter significant performance degradation when visual conditions like lighting or camera position differ from those seen during training -- often exhibiting sharp declines in capability even for minor differences. In this work, we examine robustness to a suite of these types of visual changes for RGB-D and point cloud based visual control policies. To perform these experiments on both model-free and model-based reinforcement learners, we introduce a novel Point Cloud World Model (PCWM) and point cloud based control policies. Our experiments show that policies that explicitly encode point clouds are significantly more robust than their RGB-D counterparts. Further, we find our proposed PCWM significantly outperforms prior works in terms of sample efficiency during training. Taken together, these results suggest reasoning about the 3D scene through point clouds can improve performance, reduce learning time, and increase robustness for robotic learners. Project Webpage: https://pvskand.github.io/projects/PCWM
Structured World Belief for Reinforcement Learning in POMDP
Jul 19, 2021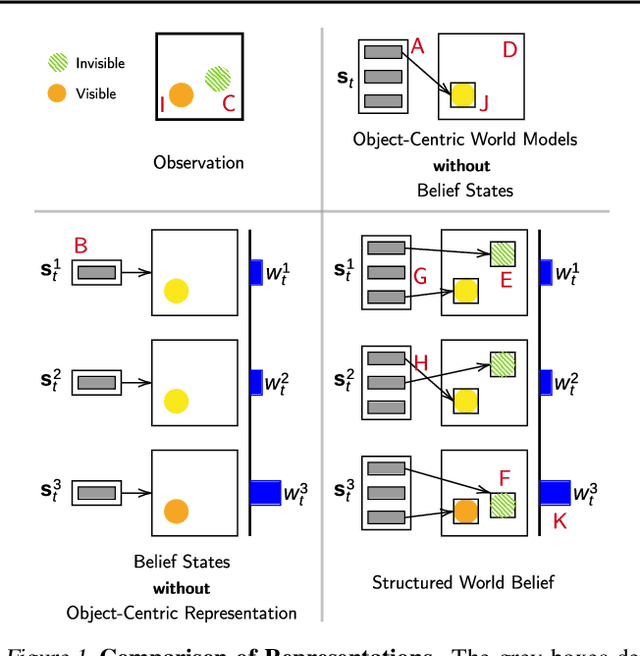
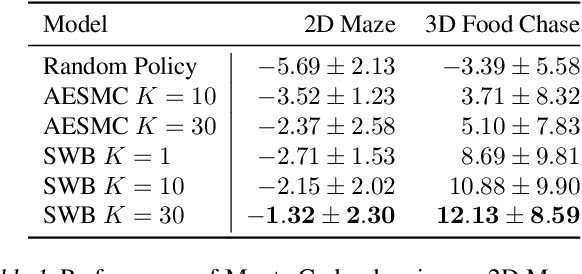
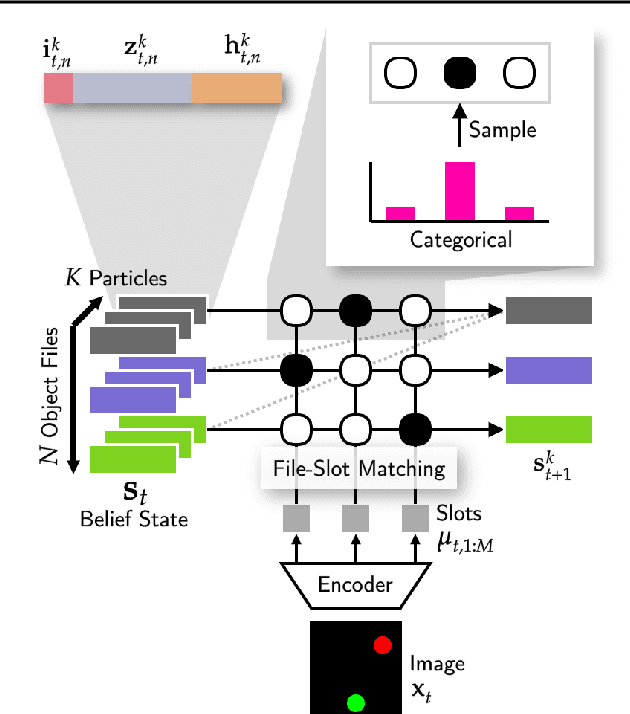

Object-centric world models provide structured representation of the scene and can be an important backbone in reinforcement learning and planning. However, existing approaches suffer in partially-observable environments due to the lack of belief states. In this paper, we propose Structured World Belief, a model for learning and inference of object-centric belief states. Inferred by Sequential Monte Carlo (SMC), our belief states provide multiple object-centric scene hypotheses. To synergize the benefits of SMC particles with object representations, we also propose a new object-centric dynamics model that considers the inductive bias of object permanence. This enables tracking of object states even when they are invisible for a long time. To further facilitate object tracking in this regime, we allow our model to attend flexibly to any spatial location in the image which was restricted in previous models. In experiments, we show that object-centric belief provides a more accurate and robust performance for filtering and generation. Furthermore, we show the efficacy of structured world belief in improving the performance of reinforcement learning, planning and supervised reasoning.
Improving Generative Imagination in Object-Centric World Models
Oct 05, 2020
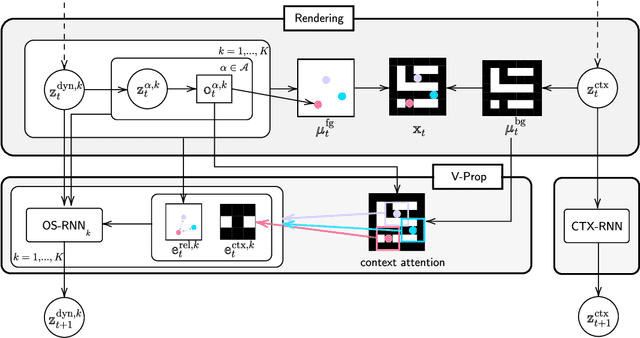
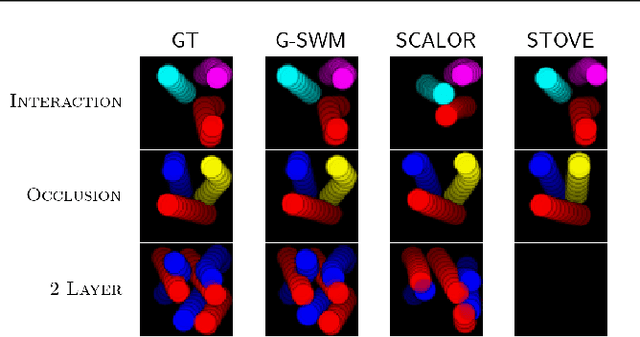
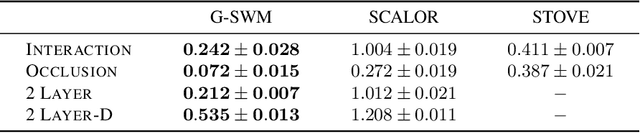
The remarkable recent advances in object-centric generative world models raise a few questions. First, while many of the recent achievements are indispensable for making a general and versatile world model, it is quite unclear how these ingredients can be integrated into a unified framework. Second, despite using generative objectives, abilities for object detection and tracking are mainly investigated, leaving the crucial ability of temporal imagination largely under question. Third, a few key abilities for more faithful temporal imagination such as multimodal uncertainty and situation-awareness are missing. In this paper, we introduce Generative Structured World Models (G-SWM). The G-SWM achieves the versatile world modeling not only by unifying the key properties of previous models in a principled framework but also by achieving two crucial new abilities, multimodal uncertainty and situation-awareness. Our thorough investigation on the temporal generation ability in comparison to the previous models demonstrates that G-SWM achieves the versatility with the best or comparable performance for all experiment settings including a few complex settings that have not been tested before.