 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph4Rec: A Universal Toolkit with Graph Neural Networks for Recommender Systems
Dec 08, 2021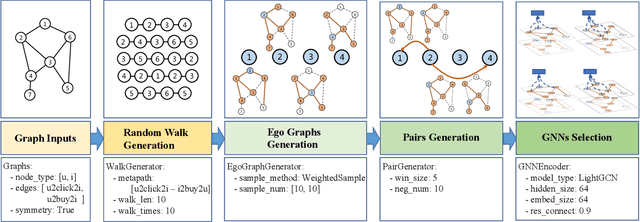

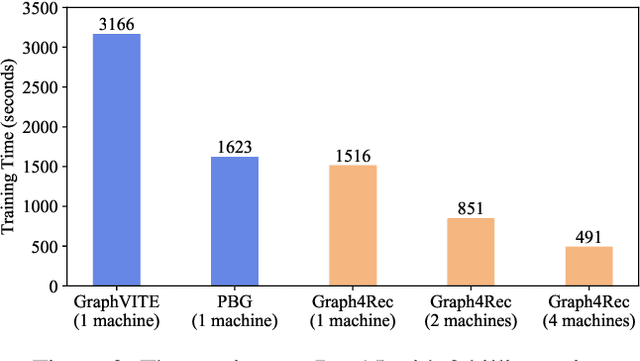

In recent years, owing to the outstanding performance in graph representation learning, graph neural network (GNN) techniques have gained considerable interests in many real-world scenarios, such as recommender systems and social networks. In recommender systems, the main challenge is to learn the effective user/item representations from their interactions. However, many recent publications using GNNs for recommender systems cannot be directly compared, due to their difference on datasets and evaluation metrics. Furthermore, many of them only provide a demo to conduct experiments on small datasets, which is far away to be applied in real-world recommender systems. To address this problem, we introduce Graph4Rec, a universal toolkit that unifies the paradigm to train GNN models into the following parts: graphs input, random walk generation, ego graphs generation, pairs generation and GNNs selection. From this training pipeline, one can easily establish his own GNN model with a few configurations. Besides, we develop a large-scale graph engine and a parameter server to support distributed GNN training. We conduct a systematic and comprehensive experiment to compare the performance of different GNN models on several scenarios in different scale. Extensive experiments are demonstrated to identify the key components of GNNs. We also try to figure out how the sparse and dense parameters affect the performance of GNNs. Finally, we investigate methods including negative sampling, ego graph construction order, and warm start strategy to find a more effective and efficient GNNs practice on recommender systems. Our toolkit is based on PGL https://github.com/PaddlePaddle/PGL and the code is opened source in https://github.com/PaddlePaddle/PGL/tree/main/apps/Graph4Rec.
Learning Approximate Stochastic Transition Models
Oct 26, 2017
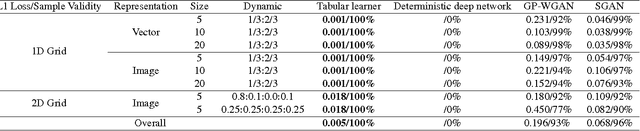


We examine the problem of learning mappings from state to state, suitable for use in a model-based reinforcement-learning setting, that simultaneously generalize to novel states and can capture stochastic transitions. We show that currently popular generative adversarial networks struggle to learn these stochastic transition models but a modification to their loss functions results in a powerful learning algorithm for this class of problems.