 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Posterior Networks for Approximately Bayesian Epistemic Uncertainty Estimation
Dec 29, 2023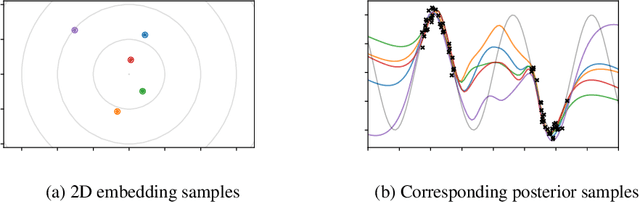
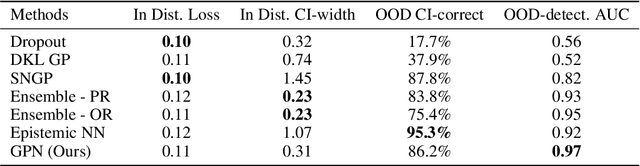
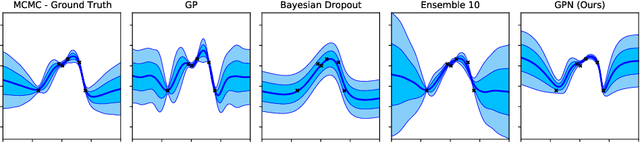
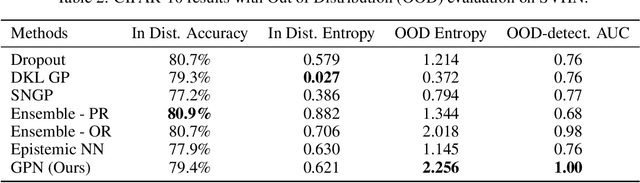
In many real-world problems, there is a limited set of training data, but an abundance of unlabeled data. We propose a new method, Generative Posterior Networks (GPNs), that uses unlabeled data to estimate epistemic uncertainty in high-dimensional problems. A GPN is a generative model that, given a prior distribution over functions, approximates the posterior distribution directly by regularizing the network towards samples from the prior. We prove theoretically that our method indeed approximates the Bayesian posterior and show empirically that it improves epistemic uncertainty estimation and scalability over competing methods.
Projected Off-Policy Q-Learning (POP-QL) for Stabilizing Offline Reinforcement Learning
Nov 25, 2023A key problem in off-policy Reinforcement Learning (RL) is the mismatch, or distribution shift, between the dataset and the distribution over states and actions visited by the learned policy. This problem is exacerbated in the fully offline setting. The main approach to correct this shift has been through importance sampling, which leads to high-variance gradients. Other approaches, such as conservatism or behavior-regularization, regularize the policy at the cost of performance. In this paper, we propose a new approach for stable off-policy Q-Learning. Our method, Projected Off-Policy Q-Learning (POP-QL), is a novel actor-critic algorithm that simultaneously reweights off-policy samples and constrains the policy to prevent divergence and reduce value-approximation error. In our experiments, POP-QL not only shows competitive performance on standard benchmarks, but also out-performs competing methods in tasks where the data-collection policy is significantly sub-optimal.
Enforcing robust control guarantees within neural network policies
Nov 16, 2020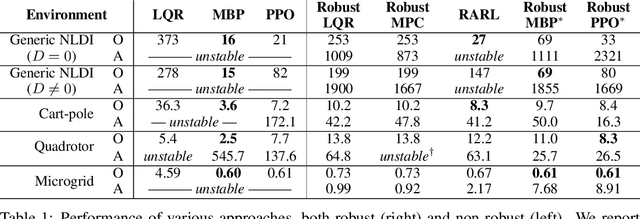
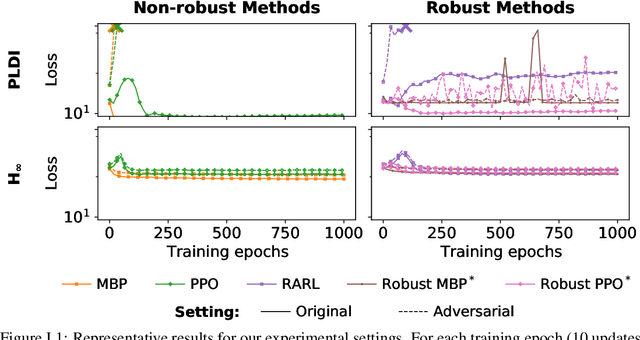
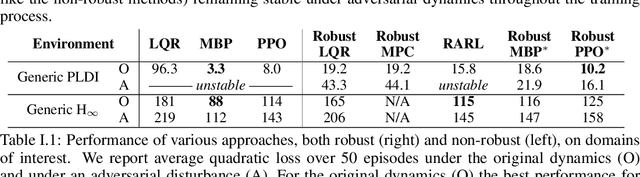
When designing controllers for safety-critical systems, practitioners often face a challenging tradeoff between robustness and performance. While robust control methods provide rigorous guarantees on system stability under certain worst-case disturbances, they often result in simple controllers that perform poorly in the average (non-worst) case. In contrast, nonlinear control methods trained using deep learning have achieved state-of-the-art performance on many control tasks, but often lack robustness guarantees. We propose a technique that combines the strengths of these two approaches: a generic nonlinear control policy class, parameterized by neural networks, that nonetheless enforces the same provable robustness criteria as robust control. Specifically, we show that by integrating custom convex-optimization-based projection layers into a nonlinear policy, we can construct a provably robust neural network policy class that outperforms robust control methods in the average (non-adversarial) setting. We demonstrate the power of this approach on several domains, improving in performance over existing robust control methods and in stability over (non-robust) RL methods.
Provably Safe PAC-MDP Exploration Using Analogies
Jul 07, 2020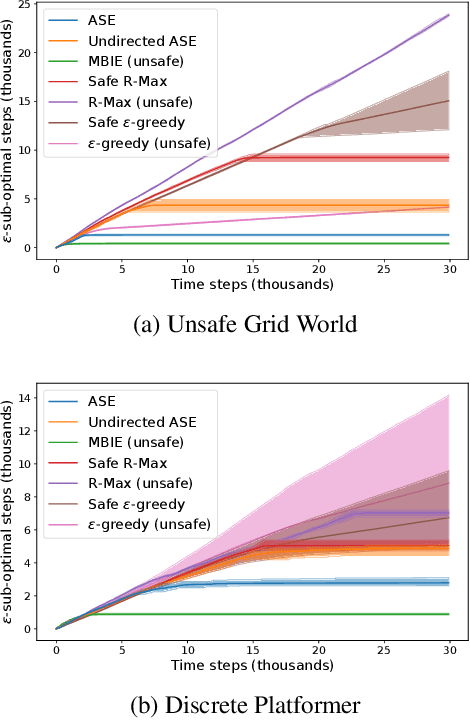
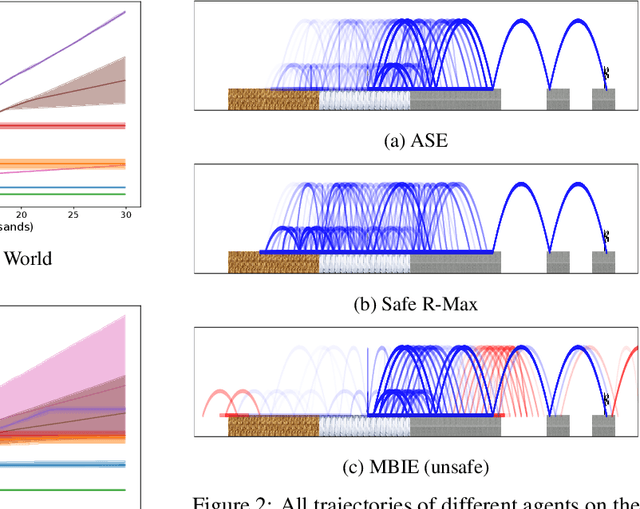
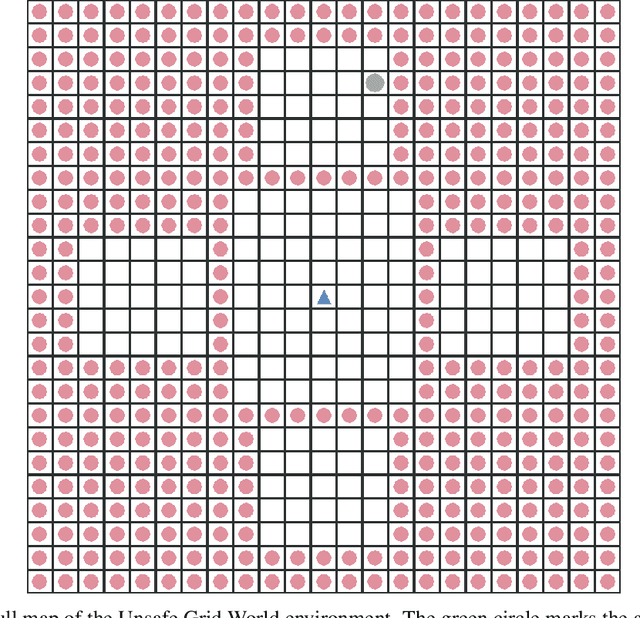
A key challenge in applying reinforcement learning to safety-critical domains is understanding how to balance exploration (needed to attain good performance on the task) with safety (needed to avoid catastrophic failure). Although a growing line of work in reinforcement learning has investigated this area of "safe exploration," most existing techniques either 1) do not guarantee safety during the actual exploration process; and/or 2) limit the problem to a priori known and/or deterministic transition dynamics with strong smoothness assumptions. Addressing this gap, we propose Analogous Safe-state Exploration (ASE), an algorithm for provably safe exploration in MDPs with unknown, stochastic dynamics. Our method exploits analogies between state-action pairs to safely learn a near-optimal policy in a PAC-MDP sense. Additionally, ASE also guides exploration towards the most task-relevant states, which empirically results in significant improvements in terms of sample efficiency, when compared to existing methods.
Deep Abstract Q-Networks
Aug 25, 2018
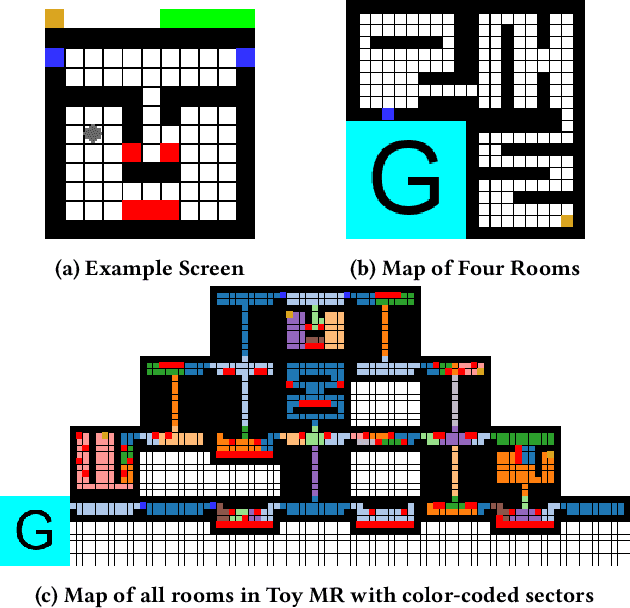
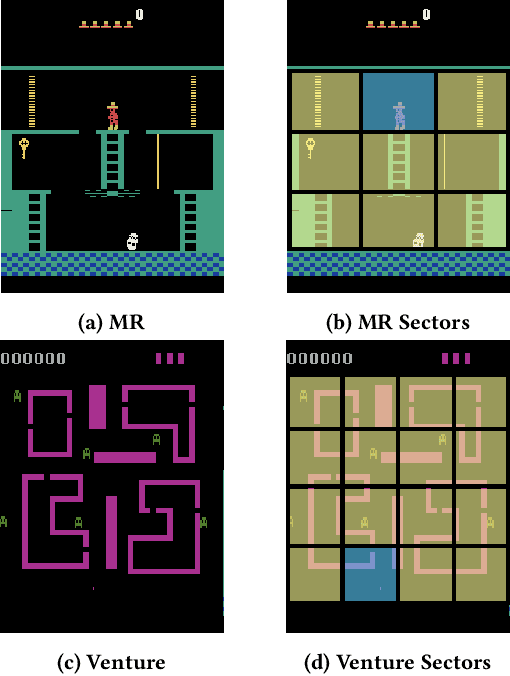
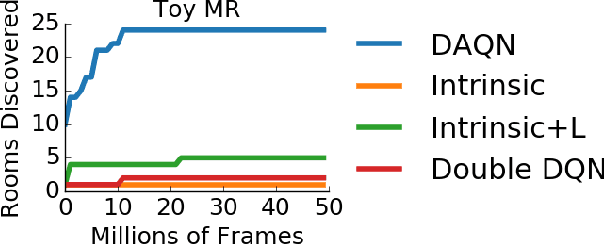
We examine the problem of learning and planning on high-dimensional domains with long horizons and sparse rewards. Recent approaches have shown great successes in many Atari 2600 domains. However, domains with long horizons and sparse rewards, such as Montezuma's Revenge and Venture, remain challenging for existing methods. Methods using abstraction (Dietterich 2000; Sutton, Precup, and Singh 1999) have shown to be useful in tackling long-horizon problems. We combine recent techniques of deep reinforcement learning with existing model-based approaches using an expert-provided state abstraction. We construct toy domains that elucidate the problem of long horizons, sparse rewards and high-dimensional inputs, and show that our algorithm significantly outperforms previous methods on these domains. Our abstraction-based approach outperforms Deep Q-Networks (Mnih et al. 2015) on Montezuma's Revenge and Venture, and exhibits backtracking behavior that is absent from previous methods.
Implementing the Deep Q-Network
Nov 20, 2017
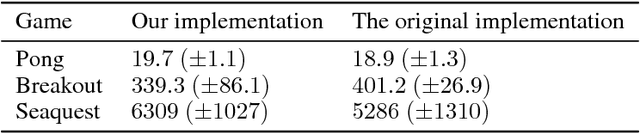
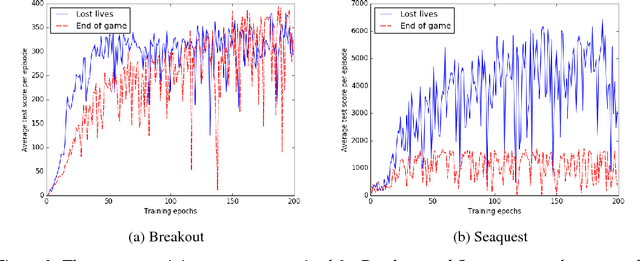
The Deep Q-Network proposed by Mnih et al. [2015] has become a benchmark and building point for much deep reinforcement learning research. However, replicating results for complex systems is often challenging since original scientific publications are not always able to describe in detail every important parameter setting and software engineering solution. In this paper, we present results from our work reproducing the results of the DQN paper. We highlight key areas in the implementation that were not covered in great detail in the original paper to make it easier for researchers to replicate these results, including termination conditions and gradient descent algorithms. Finally, we discuss methods for improving the computational performance and provide our own implementation that is designed to work with a range of domains, and not just the original Arcade Learning Environment [Bellemare et al., 2013].