 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-as-a-Judge: A Robust Alternative to Lexical Methods for Efficient Reference-Based LLM Evaluation
Apr 10, 2026Accurate evaluation is central to the large language model (LLM) ecosystem, guiding model selection and downstream adoption across diverse use cases. In practice, however, evaluating generative outputs typically relies on rigid lexical methods to extract and assess answers, which can conflate a model's true problem-solving ability with its compliance with predefined formatting guidelines. While recent LLM-as-a-Judge approaches mitigate this issue by assessing semantic correctness rather than strict structural conformity, they also introduce substantial computational overhead, making evaluation costly. In this work, we first systematically investigate the limitations of lexical evaluation through a large-scale empirical study spanning 36 models and 15 downstream tasks, demonstrating that such methods correlate poorly with human judgments. To address this limitation, we introduce BERT-as-a-Judge, an encoder-driven approach for assessing answer correctness in reference-based generative settings, robust to variations in output phrasing, and requiring only lightweight training on synthetically annotated question-candidate-reference triplets. We show that it consistently outperforms the lexical baseline while matching the performance of much larger LLM judges, providing a compelling tradeoff between the two and enabling reliable, scalable evaluation. Finally, through extensive experimentation, we provide detailed insights into BERT-as-a-Judge's performance to offer practical guidance for practitioners, and release all project artifacts to foster downstream adoption.
Identifying two piecewise linear additive value functions from anonymous preference information
Feb 24, 2026Eliciting a preference model involves asking a person, named decision-maker, a series of questions. We assume that these preferences can be represented by an additive value function. In this work, we query simultaneously two decision-makers in the aim to elicit their respective value functions. For each query we receive two answers, without noise, but without knowing which answer corresponds to which decision-maker.We propose an elicitation procedure that identifies the two preference models when the marginal value functions are piecewise linear with known breaking points.
Should We Still Pretrain Encoders with Masked Language Modeling?
Jul 01, 2025Learning high-quality text representations is fundamental to a wide range of NLP tasks. While encoder pretraining has traditionally relied on Masked Language Modeling (MLM), recent evidence suggests that decoder models pretrained with Causal Language Modeling (CLM) can be effectively repurposed as encoders, often surpassing traditional encoders on text representation benchmarks. However, it remains unclear whether these gains reflect an inherent advantage of the CLM objective or arise from confounding factors such as model and data scale. In this paper, we address this question through a series of large-scale, carefully controlled pretraining ablations, training a total of 30 models ranging from 210 million to 1 billion parameters, and conducting over 15,000 fine-tuning and evaluation runs. We find that while training with MLM generally yields better performance across text representation tasks, CLM-trained models are more data-efficient and demonstrate improved fine-tuning stability. Building on these findings, we experimentally show that a biphasic training strategy that sequentially applies CLM and then MLM, achieves optimal performance under a fixed computational training budget. Moreover, we demonstrate that this strategy becomes more appealing when initializing from readily available pretrained CLM models (from the existing LLM ecosystem), reducing the computational burden needed to train best-in-class encoder models. We release all project artifacts at https://hf.co/MLMvsCLM to foster further research.
EuroBERT: Scaling Multilingual Encoders for European Languages
Mar 07, 2025General-purpose multilingual vector representations, used in retrieval, regression and classification, are traditionally obtained from bidirectional encoder models. Despite their wide applicability, encoders have been recently overshadowed by advances in generative decoder-only models. However, many innovations driving this progress are not inherently tied to decoders. In this paper, we revisit the development of multilingual encoders through the lens of these advances, and introduce EuroBERT, a family of multilingual encoders covering European and widely spoken global languages. Our models outperform existing alternatives across a diverse range of tasks, spanning multilingual capabilities, mathematics, and coding, and natively supporting sequences of up to 8,192 tokens. We also examine the design decisions behind EuroBERT, offering insights into our dataset composition and training pipeline. We publicly release the EuroBERT models, including intermediate training checkpoints, together with our training framework.
Is Preference Alignment Always the Best Option to Enhance LLM-Based Translation? An Empirical Analysis
Sep 30, 2024Neural metrics for machine translation (MT) evaluation have become increasingly prominent due to their superior correlation with human judgments compared to traditional lexical metrics. Researchers have therefore utilized neural metrics through quality-informed decoding strategies, achieving better results than likelihood-based methods. With the rise of Large Language Models (LLMs), preference-based alignment techniques have gained attention for their potential to enhance translation quality by optimizing model weights directly on preferences induced by quality estimators. This study focuses on Contrastive Preference Optimization (CPO) and conducts extensive experiments to evaluate the impact of preference-based alignment on translation quality. Our findings indicate that while CPO consistently outperforms Supervised Fine-Tuning (SFT) on high-quality data with regard to the alignment metric, it may lead to instability across downstream evaluation metrics, particularly between neural and lexical ones. Additionally, we demonstrate that relying solely on the base model for generating candidate translations achieves performance comparable to using multiple external systems, while ensuring better consistency across downstream metrics.
Towards Trustworthy Reranking: A Simple yet Effective Abstention Mechanism
Feb 22, 2024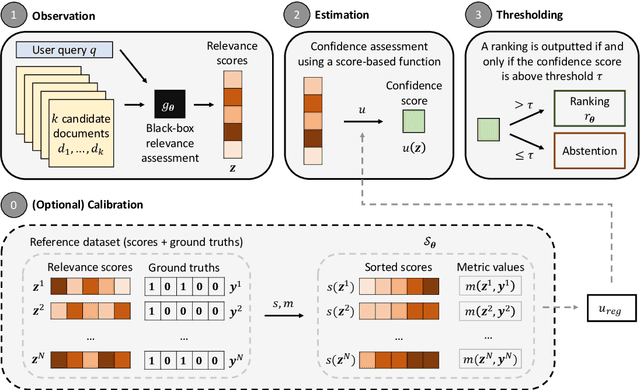
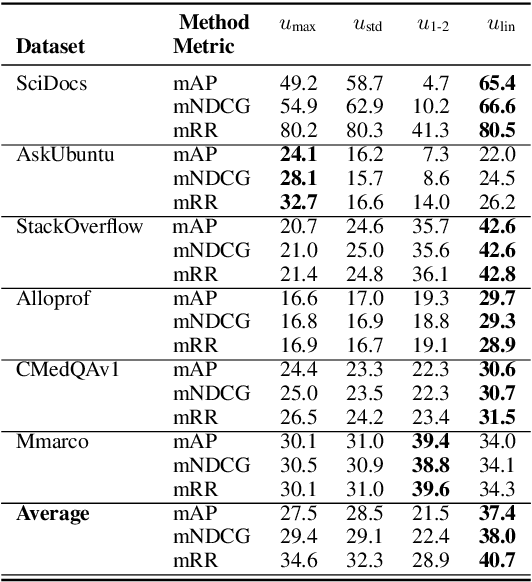
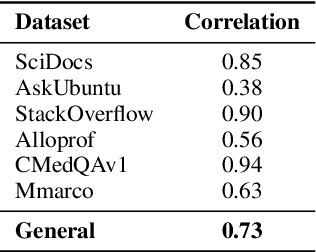
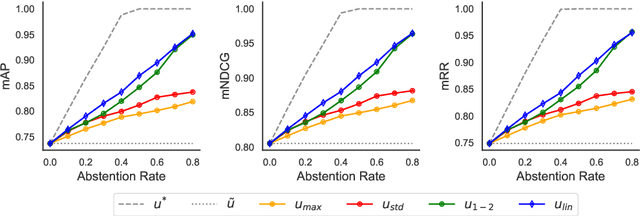
Neural Information Retrieval (NIR) has significantly improved upon heuristic-based IR systems. Yet, failures remain frequent, the models used often being unable to retrieve documents relevant to the user's query. We address this challenge by proposing a lightweight abstention mechanism tailored for real-world constraints, with particular emphasis placed on the reranking phase. We introduce a protocol for evaluating abstention strategies in a black-box scenario, demonstrating their efficacy, and propose a simple yet effective data-driven mechanism. We provide open-source code for experiment replication and abstention implementation, fostering wider adoption and application in diverse contexts.
Theoretical and experimental study of SMOTE: limitations and comparisons of rebalancing strategies
Feb 06, 2024Synthetic Minority Oversampling Technique (SMOTE) is a common rebalancing strategy for handling imbalanced data sets. Asymptotically, we prove that SMOTE (with default parameter) regenerates the original distribution by simply copying the original minority samples. We also prove that SMOTE density vanishes near the boundary of the support of the minority distribution, therefore justifying the common BorderLine SMOTE strategy. Then we introduce two new SMOTE-related strategies, and compare them with state-of-the-art rebalancing procedures. We show that rebalancing strategies are only required when the data set is highly imbalanced. For such data sets, SMOTE, our proposals, or undersampling procedures are the best strategies.