 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Non-Monotonic Automatic Post-Editing of Translations from Human Orderings
Paper and Code

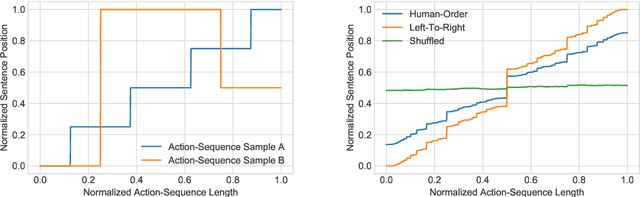
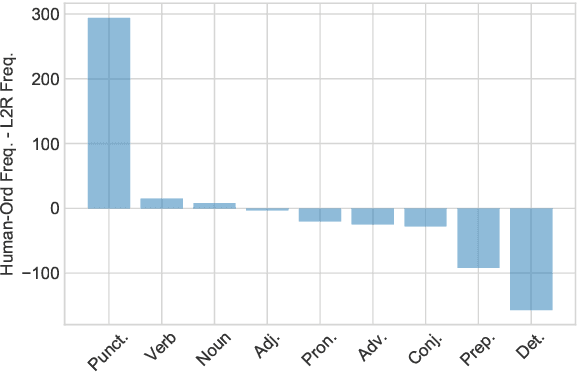
Recent research in neural machine translation has explored flexible generation orders, as an alternative to left-to-right generation. However, training non-monotonic models brings a new complication: how to search for a good ordering when there is a combinatorial explosion of orderings arriving at the same final result? Also, how do these automatic orderings compare with the actual behaviour of human translators? Current models rely on manually built biases or are left to explore all possibilities on their own. In this paper, we analyze the orderings produced by human post-editors and use them to train an automatic post-editing system. We compare the resulting system with those trained with left-to-right and random post-editing orderings. We observe that humans tend to follow a nearly left-to-right order, but with interesting deviations, such as preferring to start by correcting punctuation or verbs.