 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic Memory: Fuzzy Duplication in Copyright Traps for Large Language Models
Paper and Code

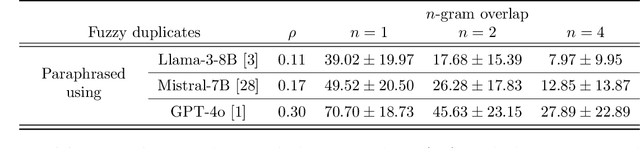
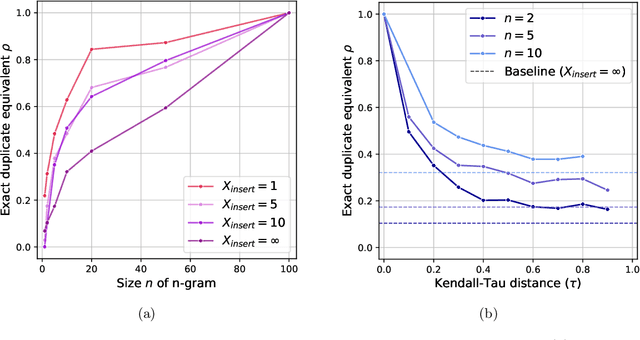
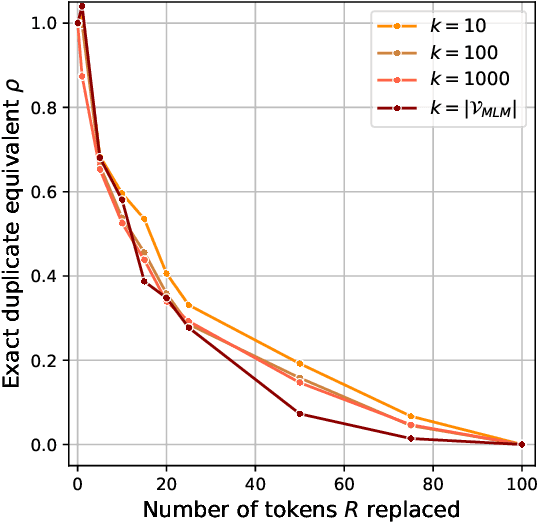
The immense datasets used to develop Large Language Models (LLMs) often include copyright-protected content, typically without the content creator's consent. Copyright traps have been proposed to be injected into the original content, improving content detectability in newly released LLMs. Traps, however, rely on the exact duplication of a unique text sequence, leaving them vulnerable to commonly deployed data deduplication techniques. We here propose the generation of fuzzy copyright traps, featuring slight modifications across duplication. When injected in the fine-tuning data of a 1.3B LLM, we show fuzzy trap sequences to be memorized nearly as well as exact duplicates. Specifically, the Membership Inference Attack (MIA) ROC AUC only drops from 0.90 to 0.87 when 4 tokens are replaced across the fuzzy duplicates. We also find that selecting replacement positions to minimize the exact overlap between fuzzy duplicates leads to similar memorization, while making fuzzy duplicates highly unlikely to be removed by any deduplication process. Lastly, we argue that the fact that LLMs memorize across fuzzy duplicates challenges the study of LLM memorization relying on naturally occurring duplicates. Indeed, we find that the commonly used training dataset, The Pile, contains significant amounts of fuzzy duplicates. This introduces a previously unexplored confounding factor in post-hoc studies of LLM memorization, and questions the effectiveness of (exact) data deduplication as a privacy protection technique.