 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHInC: A Theory-Driven Framework for Computational Humor Detection
Sep 02, 2024



Humor is a fundamental aspect of human communication and cognition, as it plays a crucial role in social engagement. Although theories about humor have evolved over centuries, there is still no agreement on a single, comprehensive humor theory. Likewise, computationally recognizing humor remains a significant challenge despite recent advances in large language models. Moreover, most computational approaches to detecting humor are not based on existing humor theories. This paper contributes to bridging this long-standing gap between humor theory research and computational humor detection by creating an interpretable framework for humor classification, grounded in multiple humor theories, called THInC (Theory-driven Humor Interpretation and Classification). THInC ensembles interpretable GA2M classifiers, each representing a different humor theory. We engineered a transparent flow to actively create proxy features that quantitatively reflect different aspects of theories. An implementation of this framework achieves an F1 score of 0.85. The associative interpretability of the framework enables analysis of proxy efficacy, alignment of joke features with theories, and identification of globally contributing features. This paper marks a pioneering effort in creating a humor detection framework that is informed by diverse humor theories and offers a foundation for future advancements in theory-driven humor classification. It also serves as a first step in automatically comparing humor theories in a quantitative manner.
RobBERT-2022: Updating a Dutch Language Model to Account for Evolving Language Use
Nov 15, 2022Large transformer-based language models, e.g. BERT and GPT-3, outperform previous architectures on most natural language processing tasks. Such language models are first pre-trained on gigantic corpora of text and later used as base-model for finetuning on a particular task. Since the pre-training step is usually not repeated, base models are not up-to-date with the latest information. In this paper, we update RobBERT, a RoBERTa-based state-of-the-art Dutch language model, which was trained in 2019. First, the tokenizer of RobBERT is updated to include new high-frequent tokens present in the latest Dutch OSCAR corpus, e.g. corona-related words. Then we further pre-train the RobBERT model using this dataset. To evaluate if our new model is a plug-in replacement for RobBERT, we introduce two additional criteria based on concept drift of existing tokens and alignment for novel tokens.We found that for certain language tasks this update results in a significant performance increase. These results highlight the benefit of continually updating a language model to account for evolving language use.
RobBERTje: a Distilled Dutch BERT Model
Apr 28, 2022
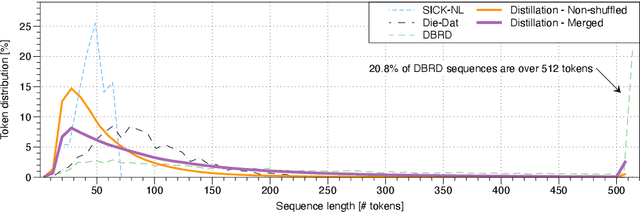


Pre-trained large-scale language models such as BERT have gained a lot of attention thanks to their outstanding performance on a wide range of natural language tasks. However, due to their large number of parameters, they are resource-intensive both to deploy and to fine-tune. Researchers have created several methods for distilling language models into smaller ones to increase efficiency, with a small performance trade-off. In this paper, we create several different distilled versions of the state-of-the-art Dutch RobBERT model and call them RobBERTje. The distillations differ in their distillation corpus, namely whether or not they are shuffled and whether they are merged with subsequent sentences. We found that the performance of the models using the shuffled versus non-shuffled datasets is similar for most tasks and that randomly merging subsequent sentences in a corpus creates models that train faster and perform better on tasks with long sequences. Upon comparing distillation architectures, we found that the larger DistilBERT architecture worked significantly better than the Bort hyperparametrization. Interestingly, we also found that the distilled models exhibit less gender-stereotypical bias than its teacher model. Since smaller architectures decrease the time to fine-tune, these models allow for more efficient training and more lightweight deployment of many Dutch downstream language tasks.
* Published in CLIN journal
Shape Inference and Grammar Induction for Example-based Procedural Generation
Sep 21, 2021
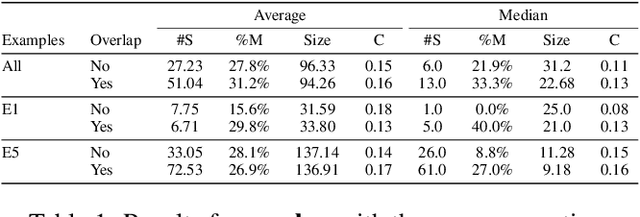

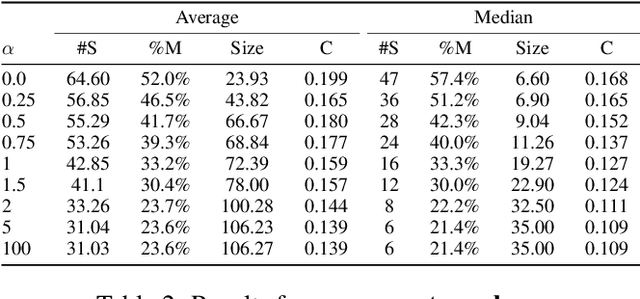
Designers increasingly rely on procedural generation for automatic generation of content in various industries. These techniques require extensive knowledge of the desired content, and about how to actually implement such procedural methods. Algorithms for learning interpretable generative models from example content could alleviate both difficulties. We propose SIGI, a novel method for inferring shapes and inducing a shape grammar from grid-based 3D building examples. This interpretable grammar is well-suited for co-creative design. Applied to Minecraft buildings, we show how the shape grammar can be used to automatically generate new buildings in a similar style.
DeepStochLog: Neural Stochastic Logic Programming
Jun 23, 2021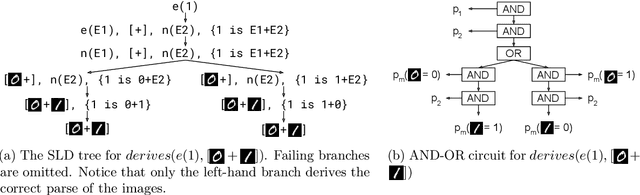

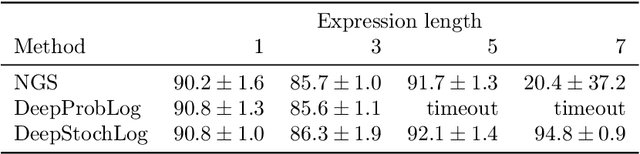
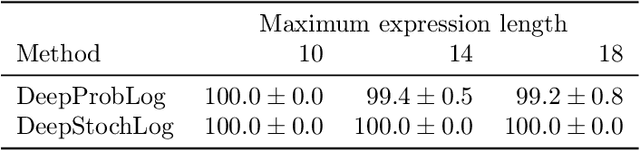
Recent advances in neural symbolic learning, such as DeepProbLog, extend probabilistic logic programs with neural predicates. Like graphical models, these probabilistic logic programs define a probability distribution over possible worlds, for which inference is computationally hard. We propose DeepStochLog, an alternative neural symbolic framework based on stochastic definite clause grammars, a type of stochastic logic program, which defines a probability distribution over possible derivations. More specifically, we introduce neural grammar rules into stochastic definite clause grammars to create a framework that can be trained end-to-end. We show that inference and learning in neural stochastic logic programming scale much better than for neural probabilistic logic programs. Furthermore, the experimental evaluation shows that DeepStochLog achieves state-of-the-art results on challenging neural symbolic learning tasks.
Dutch Humor Detection by Generating Negative Examples
Oct 26, 2020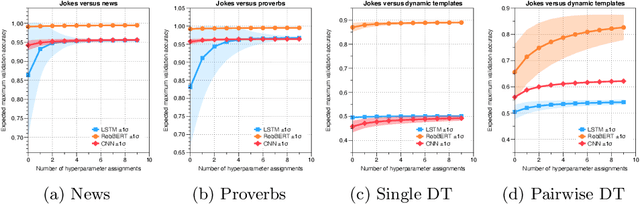
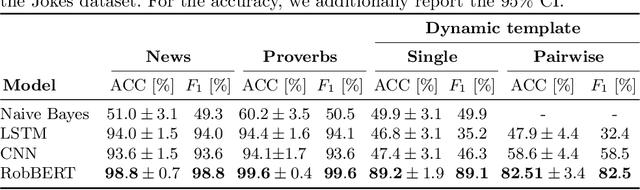
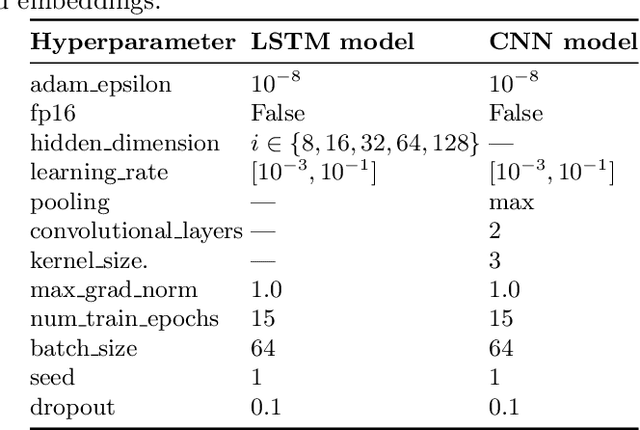

Detecting if a text is humorous is a hard task to do computationally, as it usually requires linguistic and common sense insights. In machine learning, humor detection is usually modeled as a binary classification task, trained to predict if the given text is a joke or another type of text. Rather than using completely different non-humorous texts, we propose using text generation algorithms for imitating the original joke dataset to increase the difficulty for the learning algorithm. We constructed several different joke and non-joke datasets to test the humor detection abilities of different language technologies. In particular, we compare the humor detection capabilities of classic neural network approaches with the state-of-the-art Dutch language model RobBERT. In doing so, we create and compare the first Dutch humor detection systems. We found that while other language models perform well when the non-jokes came from completely different domains, RobBERT was the only one that was able to distinguish jokes from generated negative examples. This performance illustrates the usefulness of using text generation to create negative datasets for humor recognition, and also shows that transformer models are a large step forward in humor detection.
Discovering Textual Structures: Generative Grammar Induction using Template Trees
Sep 09, 2020
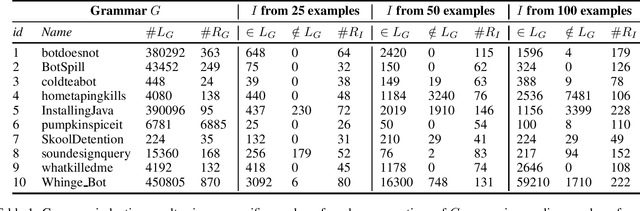
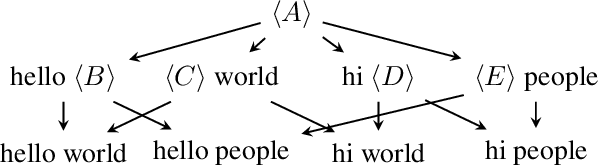
Natural language generation provides designers with methods for automatically generating text, e.g. for creating summaries, chatbots and game content. In practise, text generators are often either learned and hard to interpret, or created by hand using techniques such as grammars and templates. In this paper, we introduce a novel grammar induction algorithm for learning interpretable grammars for generative purposes, called Gitta. We also introduce the novel notion of template trees to discover latent templates in corpora to derive these generative grammars. By using existing human-created grammars, we found that the algorithm can reasonably approximate these grammars using only a few examples. These results indicate that Gitta could be used to automatically learn interpretable and easily modifiable grammars, and thus provide a stepping stone for human-machine co-creation of generative models.
RobBERT: a Dutch RoBERTa-based Language Model
Jan 17, 2020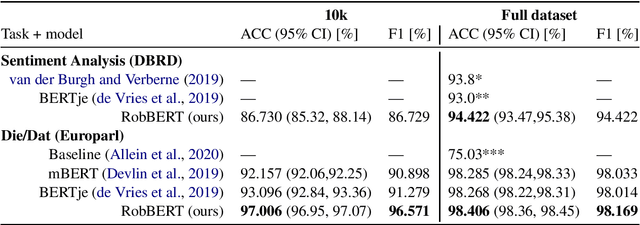

Pre-trained language models have been dominating the field of natural language processing in recent years, and have led to significant performance gains for various complex natural language tasks. One of the most prominent pre-trained language models is BERT (Bi-directional Encoders for Transformers), which was released as an English as well as a multilingual version. Although multilingual BERT performs well on many tasks, recent studies showed that BERT models trained on a single language significantly outperform the multilingual results. Training a Dutch BERT model thus has a lot of potential for a wide range of Dutch NLP tasks. While previous approaches have used earlier implementations of BERT to train their Dutch BERT, we used RoBERTa, a robustly optimized BERT approach, to train a Dutch language model called RobBERT. We show that RobBERT improves state of the art results in Dutch-specific language tasks, and also outperforms other existing Dutch BERT-based models in sentiment analysis. These results indicate that RobBERT is a powerful pre-trained model for fine-tuning for a large variety of Dutch language tasks. We publicly release this pre-trained model in hope of supporting further downstream Dutch NLP applications.
Generating Philosophical Statements using Interpolated Markov Models and Dynamic Templates
Sep 19, 2019
Automatically imitating input text is a common task in natural language generation, often used to create humorous results. Classic algorithms for learning to imitate text, e.g. simple Markov chains, usually have a trade-off between originality and syntactic correctness. We present two ways of automatically parodying philosophical statements from examples overcoming this issue, and show how these can work in interactive systems as well. The first algorithm uses interpolated Markov models with extensions to improve the quality of the generated texts. For the second algorithm, we propose dynamically extracting templates and filling these with new content. To illustrate these algorithms, we implemented TorfsBot, a Twitterbot imitating the witty, semi-philosophical tweets of professor Rik Torfs, the previous KU Leuven rector. We found that users preferred generative models that focused on local coherent sentences, rather than those mimicking the global structure of a philosophical statement. The proposed algorithms are thus valuable new tools for automatic parody as well as template learning systems.