 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Decision Trees: Implications for Accuracy and Fairness
Paper and Code
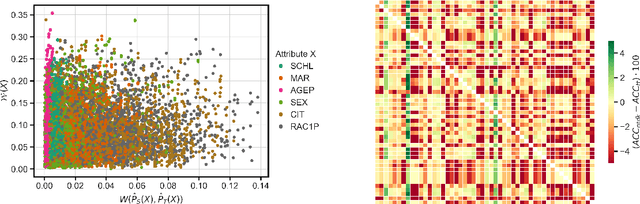
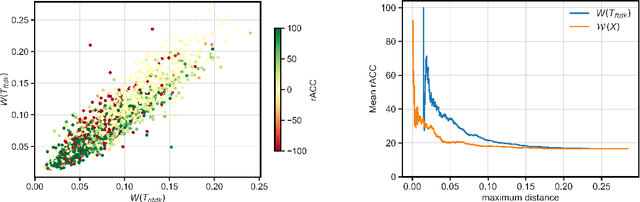
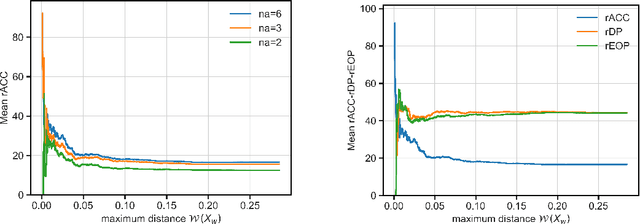
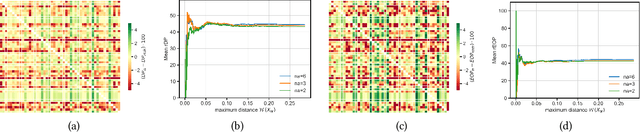
In uses of pre-trained machine learning models, it is a known issue that the target population in which the model is being deployed may not have been reflected in the source population with which the model was trained. This can result in a biased model when deployed, leading to a reduction in model performance. One risk is that, as the population changes, certain demographic groups will be under-served or otherwise disadvantaged by the model, even as they become more represented in the target population. The field of domain adaptation proposes techniques for a situation where label data for the target population does not exist, but some information about the target distribution does exist. In this paper we contribute to the domain adaptation literature by introducing domain-adaptive decision trees (DADT). We focus on decision trees given their growing popularity due to their interpretability and performance relative to other more complex models. With DADT we aim to improve the accuracy of models trained in a source domain (or training data) that differs from the target domain (or test data). We propose an in-processing step that adjusts the information gain split criterion with outside information corresponding to the distribution of the target population. We demonstrate DADT on real data and find that it improves accuracy over a standard decision tree when testing in a shifted target population. We also study the change in fairness under demographic parity and equal opportunity. Results show an improvement in fairness with the use of DADT.