 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources
Jan 24, 2022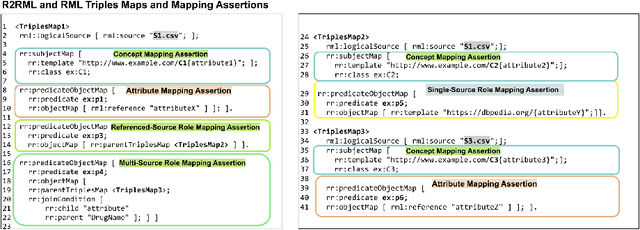
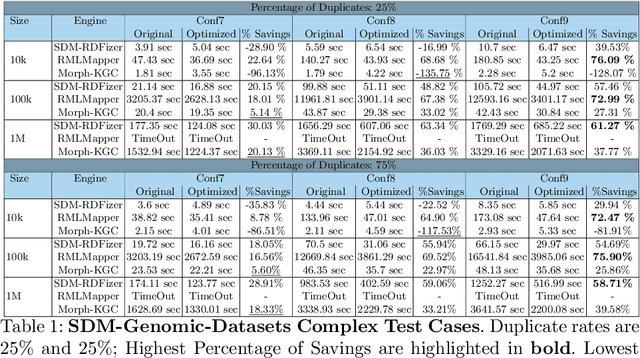
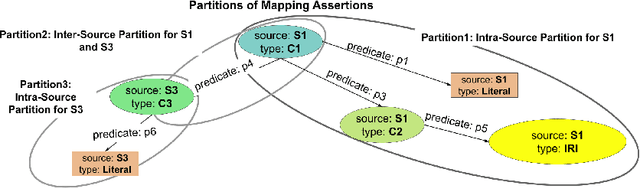
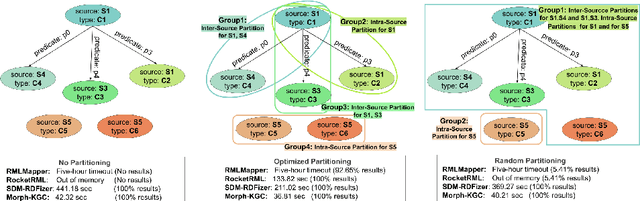
RDF knowledge graphs (KG) are powerful data structures to represent factual statements created from heterogeneous data sources. KG creation is laborious, and demands data management techniques to be executed efficiently. This paper tackles the problem of the automatic generation of KG creation processes declaratively specified; it proposes techniques for planning and transforming heterogeneous data into RDF triples following mapping assertions specified in the RDF Mapping Language (RML). Given a set of mapping assertions, the planner provides an optimized execution plan by partitioning and scheduling the execution of the assertions. First, the planner assesses an optimized number of partitions considering the number of data sources, type of mapping assertions, and the associations between different assertions. After providing a list of partitions and assertions that belong to each partition, the planner determines their execution order. A greedy algorithm is implemented to generate the partitions' bushy tree execution plan. Bushy tree plans are translated into operating system commands that guide the execution of the partitions of the mapping assertions in the order indicated by the bushy tree. The proposed optimization approach is evaluated over state-of-the-art RML-compliant engines and existing benchmarks of data sources and RML triples maps. Our experimental results suggest that the performance of the studied engines can be considerably improved, particularly in a complex setting with numerous triples maps and data sources. As a result, engines that usually time in complex cases out can, if not entirely execute all the assertions, still produce a portion of the KG.
EABlock: A Declarative Entity Alignment Block for Knowledge Graph Creation Pipelines
Dec 15, 2021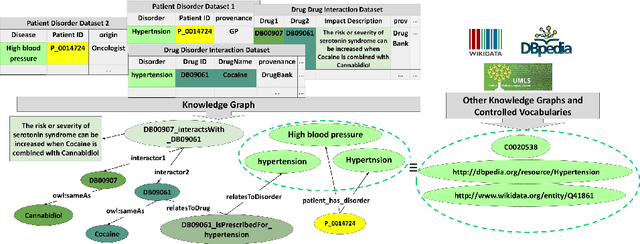
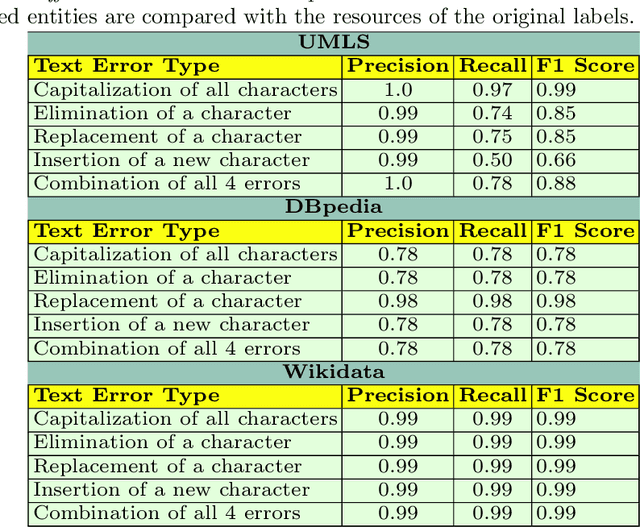
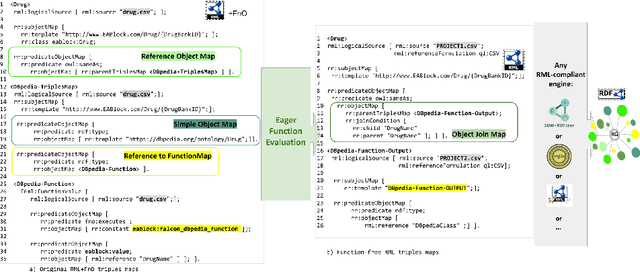
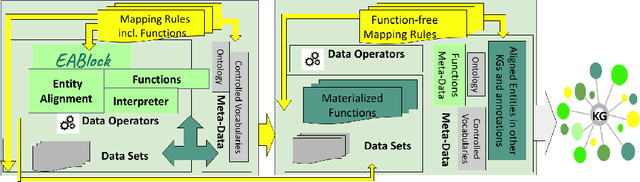
Despite encoding enormous amount of rich and valuable data, existing data sources are mostly created independently, being a significant challenge to their integration. Mapping languages, e.g., RML and R2RML, facilitate declarative specification of the process of applying meta-data and integrating data into a knowledge graph. Mapping rules can also include knowledge extraction functions in addition to expressing correspondences among data sources and a unified schema. Combining mapping rules and functions represents a powerful formalism to specify pipelines for integrating data into a knowledge graph transparently. Surprisingly, these formalisms are not fully adapted, and many knowledge graphs are created by executing ad-hoc programs to pre-process and integrate data. In this paper, we present EABlock, an approach integrating Entity Alignment (EA) as part of RML mapping rules. EABlock includes a block of functions performing entity recognition from textual attributes and link the recognized entities to the corresponding resources in Wikidata, DBpedia, and domain specific thesaurus, e.g., UMLS. EABlock provides agnostic and efficient techniques to evaluate the functions and transfer the mappings to facilitate its application in any RML-compliant engine. We have empirically evaluated EABlock performance, and results indicate that EABlock speeds up knowledge graph creation pipelines that require entity recognition and linking in state-of-the-art RML-compliant engines. EABlock is also publicly available as a tool through a GitHub repository(https://github.com/SDM-TIB/EABlock) and a DOI(https://doi.org/10.5281/zenodo.5779773).