 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Web Agents with Synthetic Supervision
Nov 08, 2025Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, we refine tasks when conflicts with actual observations are detected, mitigating hallucinations while maintaining task consistency. After collection, we conduct trajectory refinement with a global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code will be publicly available at https://github.com/aiming-lab/SynthAgent.
Attention Enhanced Entity Recommendation for Intelligent Monitoring in Cloud Systems
Oct 23, 2025In this paper, we present DiRecGNN, an attention-enhanced entity recommendation framework for monitoring cloud services at Microsoft. We provide insights on the usefulness of this feature as perceived by the cloud service owners and lessons learned from deployment. Specifically, we introduce the problem of recommending the optimal subset of attributes (dimensions) that should be tracked by an automated watchdog (monitor) for cloud services. To begin, we construct the monitor heterogeneous graph at production-scale. The interaction dynamics of these entities are often characterized by limited structural and engagement information, resulting in inferior performance of state-of-the-art approaches. Moreover, traditional methods fail to capture the dependencies between entities spanning a long range due to their homophilic nature. Therefore, we propose an attention-enhanced entity ranking model inspired by transformer architectures. Our model utilizes a multi-head attention mechanism to focus on heterogeneous neighbors and their attributes, and further attends to paths sampled using random walks to capture long-range dependencies. We also employ multi-faceted loss functions to optimize for relevant recommendations while respecting the inherent sparsity of the data. Empirical evaluations demonstrate significant improvements over existing methods, with our model achieving a 43.1% increase in MRR. Furthermore, product teams who consumed these features perceive the feature as useful and rated it 4.5 out of 5.
Beyond Spatio-Temporal Representations: Evolving Fourier Transform for Temporal Graphs
Feb 25, 2024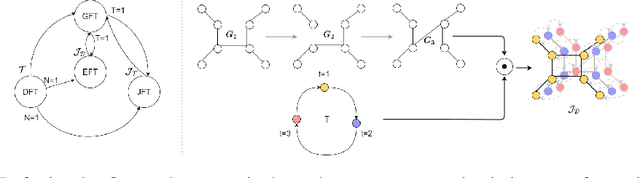
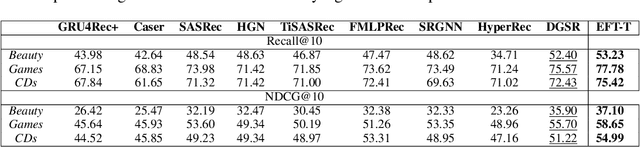
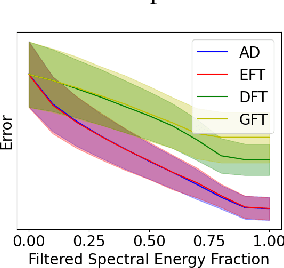
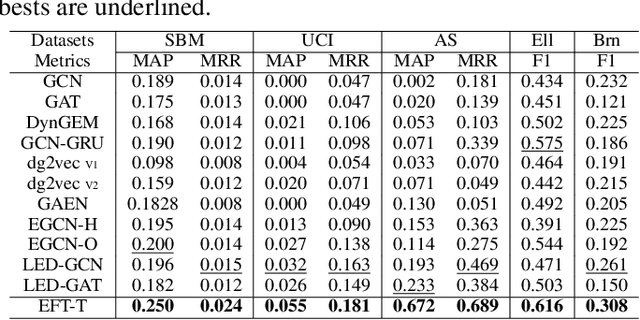
We present the Evolving Graph Fourier Transform (EFT), the first invertible spectral transform that captures evolving representations on temporal graphs. We motivate our work by the inadequacy of existing methods for capturing the evolving graph spectra, which are also computationally expensive due to the temporal aspect along with the graph vertex domain. We view the problem as an optimization over the Laplacian of the continuous time dynamic graph. Additionally, we propose pseudo-spectrum relaxations that decompose the transformation process, making it highly computationally efficient. The EFT method adeptly captures the evolving graph's structural and positional properties, making it effective for downstream tasks on evolving graphs. Hence, as a reference implementation, we develop a simple neural model induced with EFT for capturing evolving graph spectra. We empirically validate our theoretical findings on a number of large-scale and standard temporal graph benchmarks and demonstrate that our model achieves state-of-the-art performance.
Can Persistent Homology provide an efficient alternative for Evaluation of Knowledge Graph Completion Methods?
Jan 31, 2023In this paper we present a novel method, $\textit{Knowledge Persistence}$ ($\mathcal{KP}$), for faster evaluation of Knowledge Graph (KG) completion approaches. Current ranking-based evaluation is quadratic in the size of the KG, leading to long evaluation times and consequently a high carbon footprint. $\mathcal{KP}$ addresses this by representing the topology of the KG completion methods through the lens of topological data analysis, concretely using persistent homology. The characteristics of persistent homology allow $\mathcal{KP}$ to evaluate the quality of the KG completion looking only at a fraction of the data. Experimental results on standard datasets show that the proposed metric is highly correlated with ranking metrics (Hits@N, MR, MRR). Performance evaluation shows that $\mathcal{KP}$ is computationally efficient: In some cases, the evaluation time (validation+test) of a KG completion method has been reduced from 18 hours (using Hits@10) to 27 seconds (using $\mathcal{KP}$), and on average (across methods & data) reduces the evaluation time (validation+test) by $\approx$ $\textbf{99.96}\%$.
Learnable Spectral Wavelets on Dynamic Graphs to Capture Global Interactions
Nov 22, 2022



Learning on evolving(dynamic) graphs has caught the attention of researchers as static methods exhibit limited performance in this setting. The existing methods for dynamic graphs learn spatial features by local neighborhood aggregation, which essentially only captures the low pass signals and local interactions. In this work, we go beyond current approaches to incorporate global features for effectively learning representations of a dynamically evolving graph. We propose to do so by capturing the spectrum of the dynamic graph. Since static methods to learn the graph spectrum would not consider the history of the evolution of the spectrum as the graph evolves with time, we propose a novel approach to learn the graph wavelets to capture this evolving spectra. Further, we propose a framework that integrates the dynamically captured spectra in the form of these learnable wavelets into spatial features for incorporating local and global interactions. Experiments on eight standard datasets show that our method significantly outperforms related methods on various tasks for dynamic graphs.
Investigating Expressiveness of Transformer in Spectral Domain for Graphs
Jan 27, 2022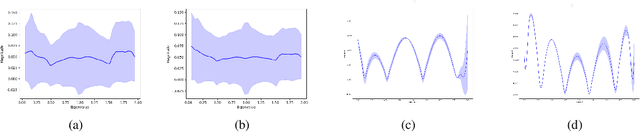
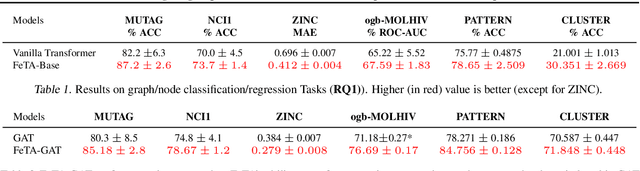
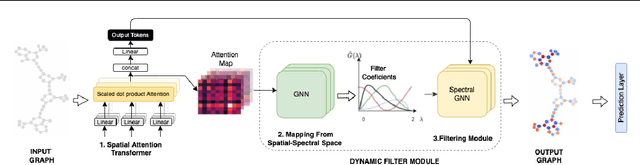
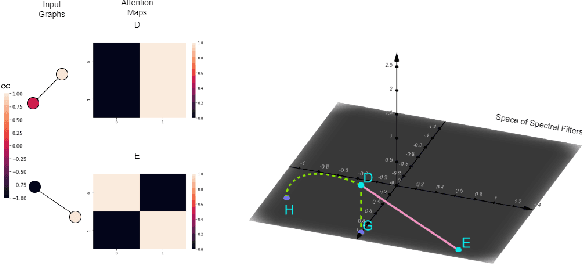
Transformers have been proven to be inadequate for graph representation learning. To understand this inadequacy, there is need to investigate if spectral analysis of transformer will reveal insights on its expressive power. Similar studies already established that spectral analysis of Graph neural networks (GNNs) provides extra perspectives on their expressiveness. In this work, we systematically study and prove the link between the spatial and spectral domain in the realm of the transformer. We further provide a theoretical analysis that the spatial attention mechanism in the transformer cannot effectively capture the desired frequency response, thus, inherently limiting its expressiveness in spectral space. Therefore, we propose FeTA, a framework that aims to perform attention over the entire graph spectrum analogous to the attention in spatial space. Empirical results suggest that FeTA provides homogeneous performance gain against vanilla transformer across all tasks on standard benchmarks and can easily be extended to GNN based models with low-pass characteristics (e.g., GAT). Furthermore, replacing the vanilla transformer model with FeTA in recently proposed position encoding schemes has resulted in comparable or better performance than transformer and GNN baselines.
ALLWAS: Active Learning on Language models in WASserstein space
Sep 03, 2021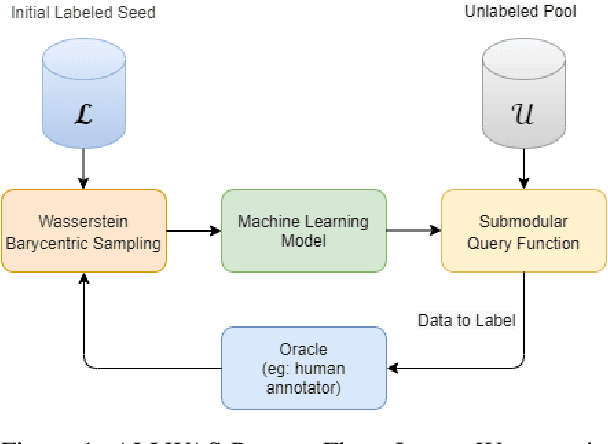
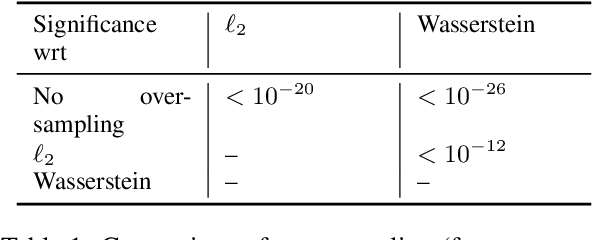

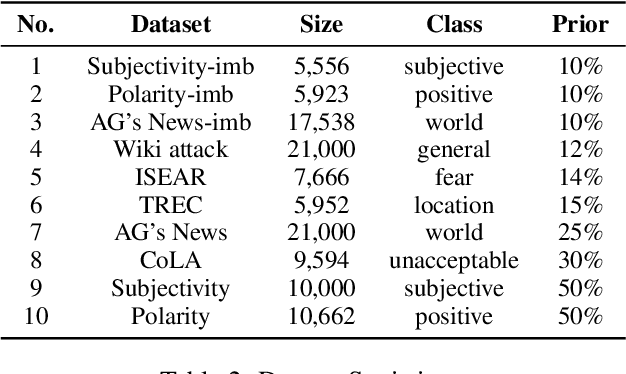
Active learning has emerged as a standard paradigm in areas with scarcity of labeled training data, such as in the medical domain. Language models have emerged as the prevalent choice of several natural language tasks due to the performance boost offered by these models. However, in several domains, such as medicine, the scarcity of labeled training data is a common issue. Also, these models may not work well in cases where class imbalance is prevalent. Active learning may prove helpful in these cases to boost the performance with a limited label budget. To this end, we propose a novel method using sampling techniques based on submodular optimization and optimal transport for active learning in language models, dubbed ALLWAS. We construct a sampling strategy based on submodular optimization of the designed objective in the gradient domain. Furthermore, to enable learning from few samples, we propose a novel strategy for sampling from the Wasserstein barycenters. Our empirical evaluations on standard benchmark datasets for text classification show that our methods perform significantly better (>20% relative increase in some cases) than existing approaches for active learning on language models.
HopfE: Knowledge Graph Representation Learning using Inverse Hopf Fibrations
Aug 12, 2021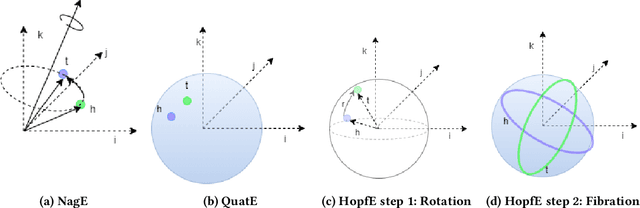

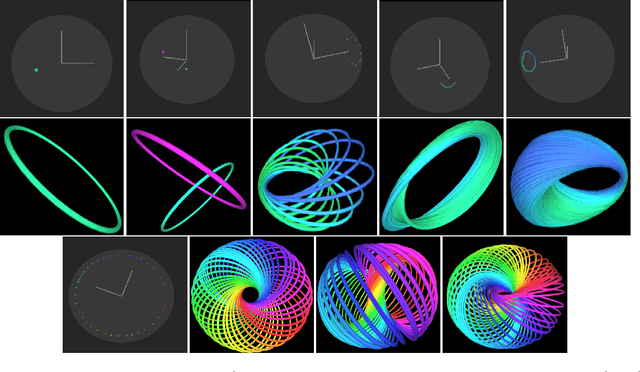
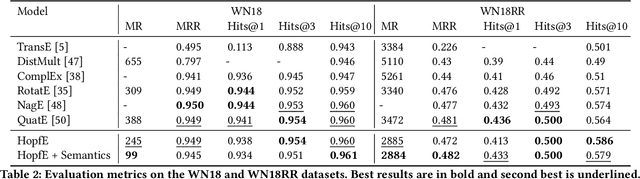
Recently, several Knowledge Graph Embedding (KGE) approaches have been devised to represent entities and relations in dense vector space and employed in downstream tasks such as link prediction. A few KGE techniques address interpretability, i.e., mapping the connectivity patterns of the relations (i.e., symmetric/asymmetric, inverse, and composition) to a geometric interpretation such as rotations. Other approaches model the representations in higher dimensional space such as four-dimensional space (4D) to enhance the ability to infer the connectivity patterns (i.e., expressiveness). However, modeling relation and entity in a 4D space often comes at the cost of interpretability. This paper proposes HopfE, a novel KGE approach aiming to achieve the interpretability of inferred relations in the four-dimensional space. We first model the structural embeddings in 3D Euclidean space and view the relation operator as an SO(3) rotation. Next, we map the entity embedding vector from a 3D space to a 4D hypersphere using the inverse Hopf Fibration, in which we embed the semantic information from the KG ontology. Thus, HopfE considers the structural and semantic properties of the entities without losing expressivity and interpretability. Our empirical results on four well-known benchmarks achieve state-of-the-art performance for the KG completion task.
KGPool: Dynamic Knowledge Graph Context Selection for Relation Extraction
Jun 06, 2021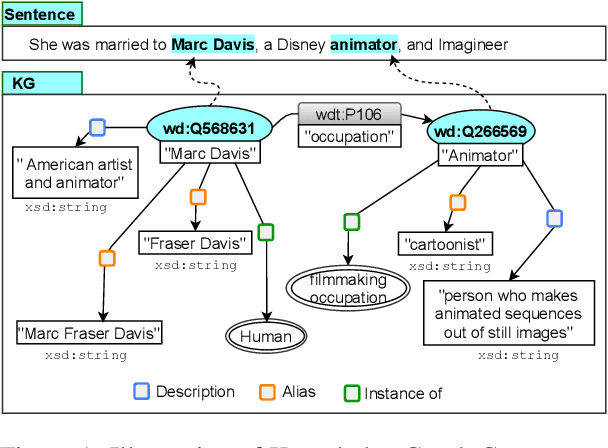
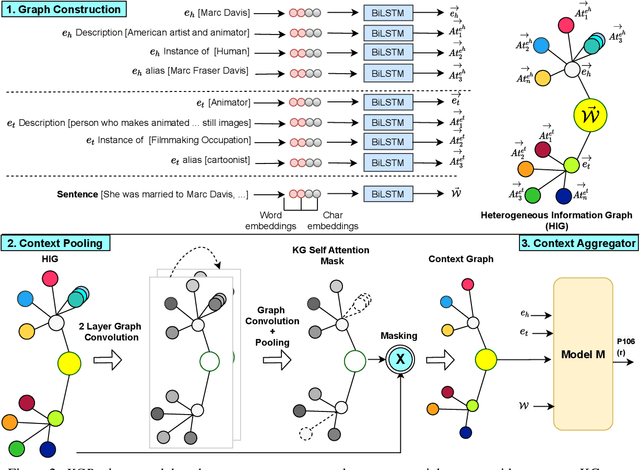
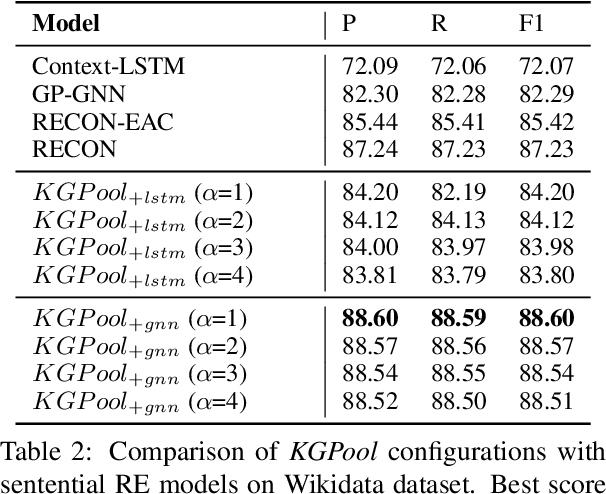
We present a novel method for relation extraction (RE) from a single sentence, mapping the sentence and two given entities to a canonical fact in a knowledge graph (KG). Especially in this presumed sentential RE setting, the context of a single sentence is often sparse. This paper introduces the KGPool method to address this sparsity, dynamically expanding the context with additional facts from the KG. It learns the representation of these facts (entity alias, entity descriptions, etc.) using neural methods, supplementing the sentential context. Unlike existing methods that statically use all expanded facts, KGPool conditions this expansion on the sentence. We study the efficacy of KGPool by evaluating it with different neural models and KGs (Wikidata and NYT Freebase). Our experimental evaluation on standard datasets shows that by feeding the KGPool representation into a Graph Neural Network, the overall method is significantly more accurate than state-of-the-art methods.
RECON: Relation Extraction using Knowledge Graph Context in a Graph Neural Network
Sep 18, 2020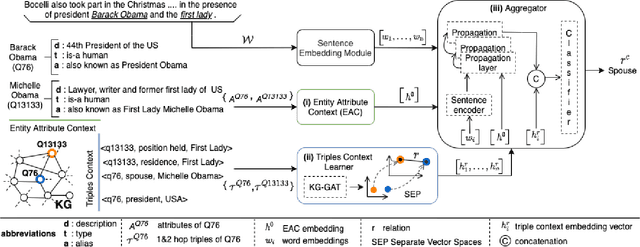
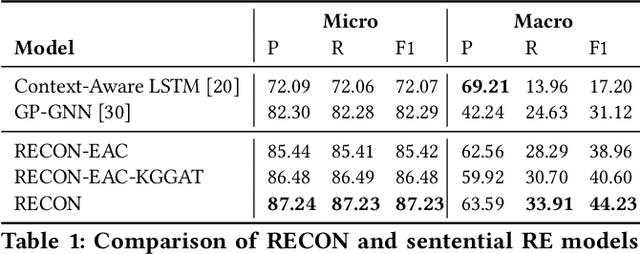
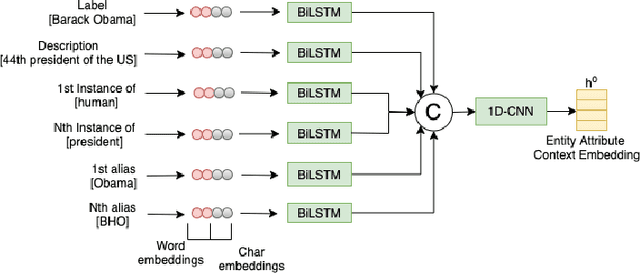
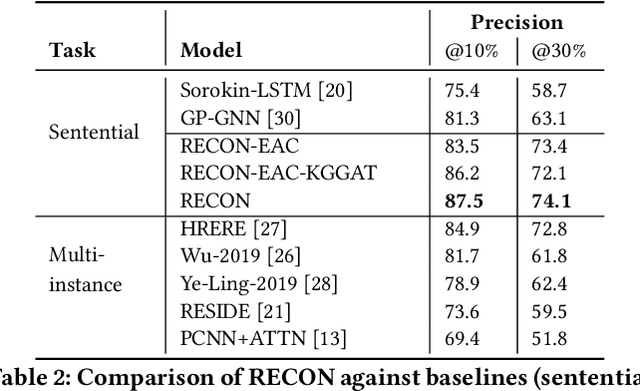
In this paper, we present a novel method named RECON, that automatically identifies relations in a sentence (sentential relation extraction) and aligns to a knowledge graph (KG). RECON uses a graph neural network to learn representations of both the sentence as well as facts stored in a KG, improving the overall extraction quality. These facts, including entity attributes (label, alias, description, instance-of) and factual triples, have not been collectively used in the state of the art methods. We evaluate the effect of various forms of representing the KG context on the performance of RECON. The empirical evaluation on two standard relation extraction datasets shows that RECON significantly outperforms all state of the art methods on NYT Freebase and Wikidata datasets. RECON reports 87.23 F1 score (Vs 82.29 baseline) on Wikidata dataset whereas on NYT Freebase, reported values are 87.5(P@10) and 74.1(P@30) compared to the previous baseline scores of 81.3(P@10) and 63.1(P@30).