 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quality Type-aware Annotated Corpus and Lexicon for Harassment Research
Paper and Code
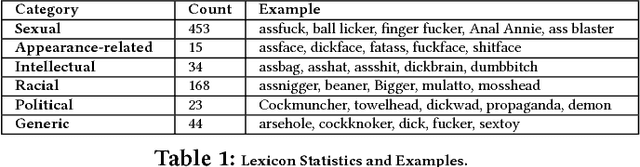
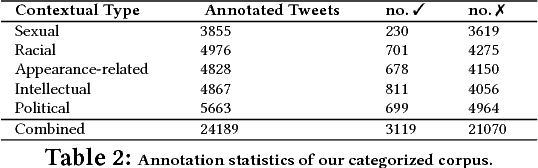

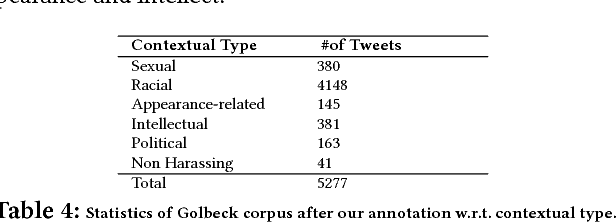
Having a quality annotated corpus is essential especially for applied research. Despite the recent focus of Web science community on researching about cyberbullying, the community dose not still have standard benchmarks. In this paper, we publish first, a quality annotated corpus and second, an offensive words lexicon capturing different types type of harassment as (i) sexual harassment, (ii) racial harassment, (iii) appearance-related harassment, (iv) intellectual harassment, and (v) political harassment.We crawled data from Twitter using our offensive lexicon. Then relied on the human judge to annotate the collected tweets w.r.t. the contextual types because using offensive words is not sufficient to reliably detect harassment. Our corpus consists of 25,000 annotated tweets in five contextual types. We are pleased to share this novel annotated corpus and the lexicon with the research community. The instruction to acquire the corpus has been published on the Git repository.