 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThey Look Like Each Other: Case-based Reasoning for Explainable Depression Detection on Twitter using Large Language Models
Jul 21, 2024



Depression is a common mental health issue that requires prompt diagnosis and treatment. Despite the promise of social media data for depression detection, the opacity of employed deep learning models hinders interpretability and raises bias concerns. We address this challenge by introducing ProtoDep, a novel, explainable framework for Twitter-based depression detection. ProtoDep leverages prototype learning and the generative power of Large Language Models to provide transparent explanations at three levels: (i) symptom-level explanations for each tweet and user, (ii) case-based explanations comparing the user to similar individuals, and (iii) transparent decision-making through classification weights. Evaluated on five benchmark datasets, ProtoDep achieves near state-of-the-art performance while learning meaningful prototypes. This multi-faceted approach offers significant potential to enhance the reliability and transparency of depression detection on social media, ultimately aiding mental health professionals in delivering more informed care.
FORML: A Riemannian Hessian-free Method for Meta-learning with Orthogonality Constraint
Feb 28, 2024



Meta-learning problem is usually formulated as a bi-level optimization in which the task-specific and the meta-parameters are updated in the inner and outer loops of optimization, respectively. However, performing the optimization in the Riemannian space, where the parameters and meta-parameters are located on Riemannian manifolds is computationally intensive. Unlike the Euclidean methods, the Riemannian backpropagation needs computing the second-order derivatives that include backward computations through the Riemannian operators such as retraction and orthogonal projection. This paper introduces a Hessian-free approach that uses a first-order approximation of derivatives on the Stiefel manifold. Our method significantly reduces the computational load and memory footprint. We show how using a Stiefel fully-connected layer that enforces orthogonality constraint on the parameters of the last classification layer as the head of the backbone network, strengthens the representation reuse of the gradient-based meta-learning methods. Our experimental results across various few-shot learning datasets, demonstrate the superiority of our proposed method compared to the state-of-the-art methods, especially MAML, its Euclidean counterpart.
Multi-modal reward for visual relationships-based image captioning
Mar 21, 2023Deep neural networks have achieved promising results in automatic image captioning due to their effective representation learning and context-based content generation capabilities. As a prominent type of deep features used in many of the recent image captioning methods, the well-known bottomup features provide a detailed representation of different objects of the image in comparison with the feature maps directly extracted from the raw image. However, the lack of high-level semantic information about the relationships between these objects is an important drawback of bottom-up features, despite their expensive and resource-demanding extraction procedure. To take advantage of visual relationships in caption generation, this paper proposes a deep neural network architecture for image captioning based on fusing the visual relationships information extracted from an image's scene graph with the spatial feature maps of the image. A multi-modal reward function is then introduced for deep reinforcement learning of the proposed network using a combination of language and vision similarities in a common embedding space. The results of extensive experimentation on the MSCOCO dataset show the effectiveness of using visual relationships in the proposed captioning method. Moreover, the results clearly indicate that the proposed multi-modal reward in deep reinforcement learning leads to better model optimization, outperforming several state-of-the-art image captioning algorithms, while using light and easy to extract image features. A detailed experimental study of the components constituting the proposed method is also presented.
Geometric Multimodal Deep Learning with Multi-Scaled Graph Wavelet Convolutional Network
Nov 26, 2021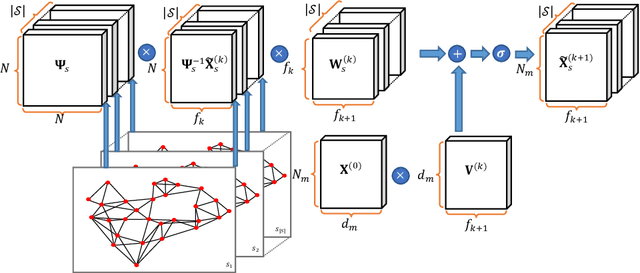
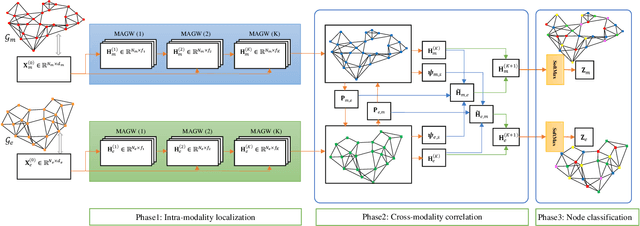
Multimodal data provide complementary information of a natural phenomenon by integrating data from various domains with very different statistical properties. Capturing the intra-modality and cross-modality information of multimodal data is the essential capability of multimodal learning methods. The geometry-aware data analysis approaches provide these capabilities by implicitly representing data in various modalities based on their geometric underlying structures. Also, in many applications, data are explicitly defined on an intrinsic geometric structure. Generalizing deep learning methods to the non-Euclidean domains is an emerging research field, which has recently been investigated in many studies. Most of those popular methods are developed for unimodal data. In this paper, a multimodal multi-scaled graph wavelet convolutional network (M-GWCN) is proposed as an end-to-end network. M-GWCN simultaneously finds intra-modality representation by applying the multiscale graph wavelet transform to provide helpful localization properties in the graph domain of each modality, and cross-modality representation by learning permutations that encode correlations among various modalities. M-GWCN is not limited to either the homogeneous modalities with the same number of data, or any prior knowledge indicating correspondences between modalities. Several semi-supervised node classification experiments have been conducted on three popular unimodal explicit graph-based datasets and five multimodal implicit ones. The experimental results indicate the superiority and effectiveness of the proposed methods compared with both spectral graph domain convolutional neural networks and state-of-the-art multimodal methods.
Weighted Least Squares Twin Support Vector Machine with Fuzzy Rough Set Theory for Imbalanced Data Classification
May 21, 2021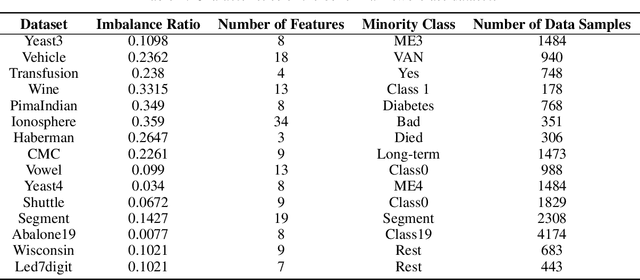
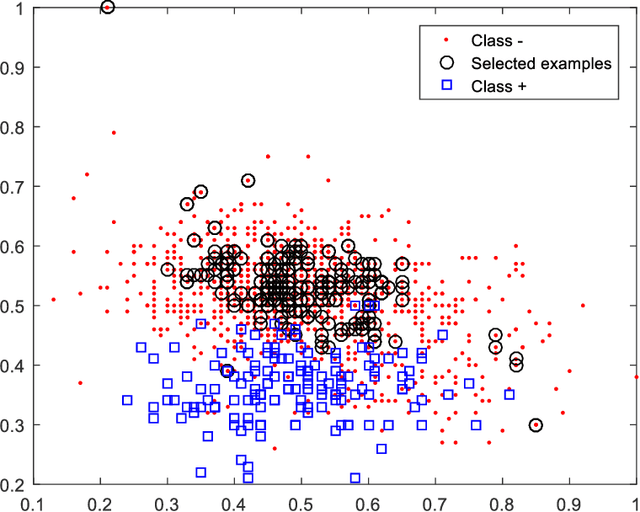

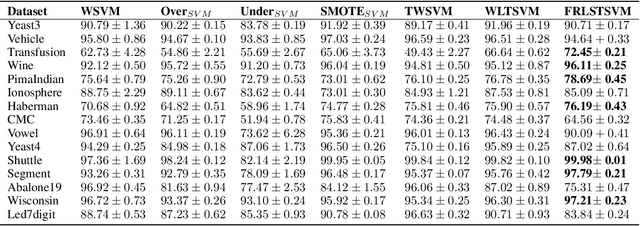
Support vector machines (SVMs) are powerful supervised learning tools developed to solve classification problems. However, SVMs are likely to perform poorly in the classification of imbalanced data. The rough set theory presents a mathematical tool for inference in nondeterministic cases that provides methods for removing irrelevant information from data. In this work, we propose an approach that efficiently used fuzzy rough set theory in weighted least squares twin support vector machine called FRLSTSVM for classification of imbalanced data. The first innovation is introducing a new fuzzy rough set-based under-sampling strategy to make the classifier robust in terms of the imbalanced data. For constructing the two proximal hyperplanes in FRLSTSVM, data points from the minority class remain unchanged while a subset of data points in the majority class are selected using a new method. In this model, we embed the weight biases in the LSTSVM formulations to overcome the bias phenomenon in the original twin SVM for the classification of imbalanced data. In order to determine these weights in this formulation, we introduce a new strategy that uses fuzzy rough set theory as the second innovation. Experimental results on the famous imbalanced datasets, compared to the related traditional SVM-based methods, demonstrate the superiority of the proposed FRLSTSVM model in the imbalanced data classification.
Cross-Modal and Multimodal Data Analysis Based on Functional Mapping of Spectral Descriptors and Manifold Regularization
May 12, 2021
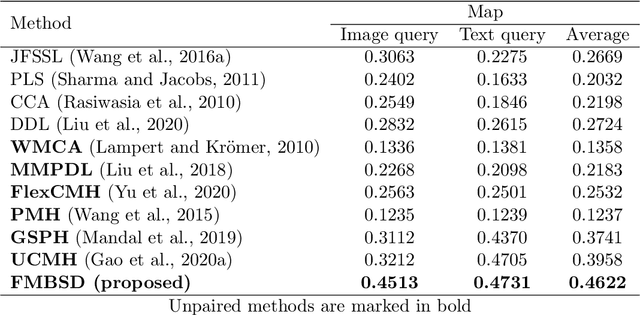
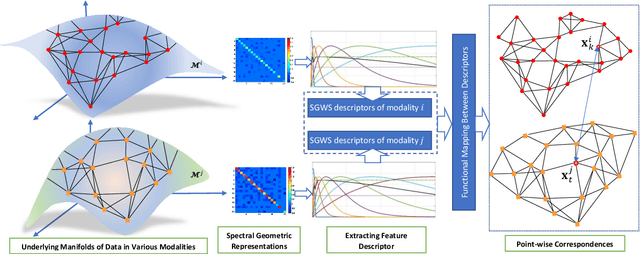

Multimodal manifold modeling methods extend the spectral geometry-aware data analysis to learning from several related and complementary modalities. Most of these methods work based on two major assumptions: 1) there are the same number of homogeneous data samples in each modality, and 2) at least partial correspondences between modalities are given in advance as prior knowledge. This work proposes two new multimodal modeling methods. The first method establishes a general analyzing framework to deal with the multimodal information problem for heterogeneous data without any specific prior knowledge. For this purpose, first, we identify the localities of each manifold by extracting local descriptors via spectral graph wavelet signatures (SGWS). Then, we propose a manifold regularization framework based on the functional mapping between SGWS descriptors (FMBSD) for finding the pointwise correspondences. The second method is a manifold regularized multimodal classification based on pointwise correspondences (M$^2$CPC) used for the problem of multiclass classification of multimodal heterogeneous, which the correspondences between modalities are determined based on the FMBSD method. The experimental results of evaluating the FMBSD method on three common cross-modal retrieval datasets and evaluating the (M$^2$CPC) method on three benchmark multimodal multiclass classification datasets indicate their effectiveness and superiority over state-of-the-art methods.
Machine learning for Internet of Things data analysis: A survey
Feb 17, 2018
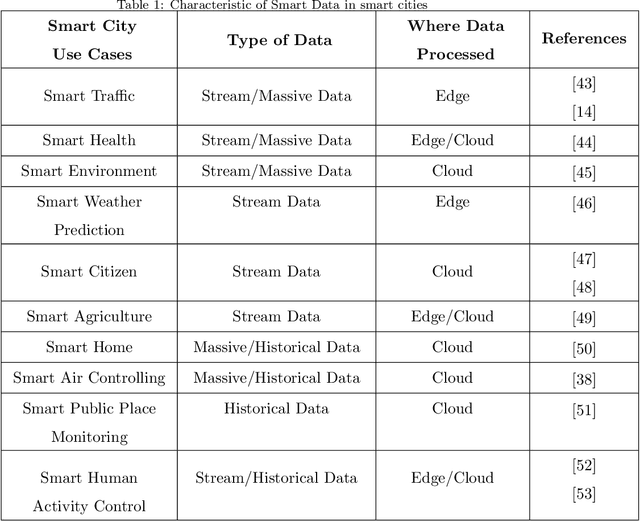
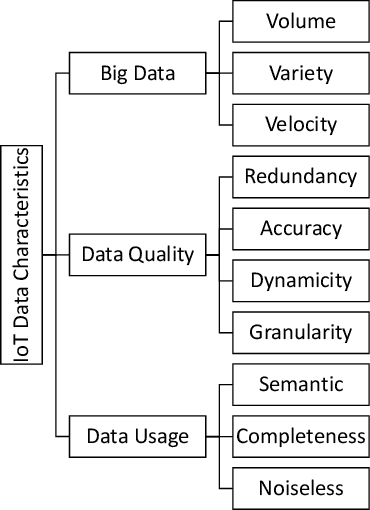
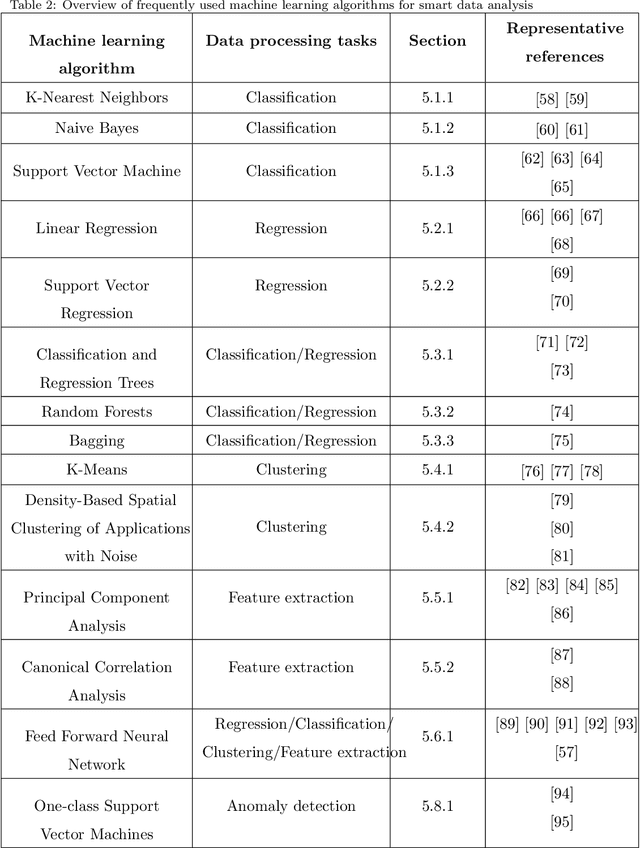
Rapid developments in hardware, software, and communication technologies have allowed the emergence of Internet-connected sensory devices that provide observation and data measurement from the physical world. By 2020, it is estimated that the total number of Internet-connected devices being used will be between 25 and 50 billion. As the numbers grow and technologies become more mature, the volume of data published will increase. Internet-connected devices technology, referred to as Internet of Things (IoT), continues to extend the current Internet by providing connectivity and interaction between the physical and cyber worlds. In addition to increased volume, the IoT generates Big Data characterized by velocity in terms of time and location dependency, with a variety of multiple modalities and varying data quality. Intelligent processing and analysis of this Big Data is the key to developing smart IoT applications. This article assesses the different machine learning methods that deal with the challenges in IoT data by considering smart cities as the main use case. The key contribution of this study is presentation of a taxonomy of machine learning algorithms explaining how different techniques are applied to the data in order to extract higher level information. The potential and challenges of machine learning for IoT data analytics will also be discussed. A use case of applying Support Vector Machine (SVM) on Aarhus Smart City traffic data is presented for a more detailed exploration.