 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreast Histopathology Image Retrieval by Attention-based Adversarially Regularized Variational Graph Autoencoder with Contrastive Learning-Based Feature Extraction
May 07, 2024



Breast cancer is a significant global health concern, particularly for women. Early detection and appropriate treatment are crucial in mitigating its impact, with histopathology examinations playing a vital role in swift diagnosis. However, these examinations often require a substantial workforce and experienced medical experts for proper recognition and cancer grading. Automated image retrieval systems have the potential to assist pathologists in identifying cancerous tissues, thereby accelerating the diagnostic process. Nevertheless, due to considerable variability among the tissue and cell patterns in histological images, proposing an accurate image retrieval model is very challenging. This work introduces a novel attention-based adversarially regularized variational graph autoencoder model for breast histological image retrieval. Additionally, we incorporated cluster-guided contrastive learning as the graph feature extractor to boost the retrieval performance. We evaluated the proposed model's performance on two publicly available datasets of breast cancer histological images and achieved superior or very competitive retrieval performance, with average mAP scores of 96.5% for the BreakHis dataset and 94.7% for the BACH dataset, and mVP scores of 91.9% and 91.3%, respectively. Our proposed retrieval model has the potential to be used in clinical settings to enhance diagnostic performance and ultimately benefit patients.
FORML: A Riemannian Hessian-free Method for Meta-learning with Orthogonality Constraint
Feb 28, 2024



Meta-learning problem is usually formulated as a bi-level optimization in which the task-specific and the meta-parameters are updated in the inner and outer loops of optimization, respectively. However, performing the optimization in the Riemannian space, where the parameters and meta-parameters are located on Riemannian manifolds is computationally intensive. Unlike the Euclidean methods, the Riemannian backpropagation needs computing the second-order derivatives that include backward computations through the Riemannian operators such as retraction and orthogonal projection. This paper introduces a Hessian-free approach that uses a first-order approximation of derivatives on the Stiefel manifold. Our method significantly reduces the computational load and memory footprint. We show how using a Stiefel fully-connected layer that enforces orthogonality constraint on the parameters of the last classification layer as the head of the backbone network, strengthens the representation reuse of the gradient-based meta-learning methods. Our experimental results across various few-shot learning datasets, demonstrate the superiority of our proposed method compared to the state-of-the-art methods, especially MAML, its Euclidean counterpart.
Multi-modal reward for visual relationships-based image captioning
Mar 21, 2023Deep neural networks have achieved promising results in automatic image captioning due to their effective representation learning and context-based content generation capabilities. As a prominent type of deep features used in many of the recent image captioning methods, the well-known bottomup features provide a detailed representation of different objects of the image in comparison with the feature maps directly extracted from the raw image. However, the lack of high-level semantic information about the relationships between these objects is an important drawback of bottom-up features, despite their expensive and resource-demanding extraction procedure. To take advantage of visual relationships in caption generation, this paper proposes a deep neural network architecture for image captioning based on fusing the visual relationships information extracted from an image's scene graph with the spatial feature maps of the image. A multi-modal reward function is then introduced for deep reinforcement learning of the proposed network using a combination of language and vision similarities in a common embedding space. The results of extensive experimentation on the MSCOCO dataset show the effectiveness of using visual relationships in the proposed captioning method. Moreover, the results clearly indicate that the proposed multi-modal reward in deep reinforcement learning leads to better model optimization, outperforming several state-of-the-art image captioning algorithms, while using light and easy to extract image features. A detailed experimental study of the components constituting the proposed method is also presented.
Deep fusion of gray level co-occurrence matrices for lung nodule classification
May 10, 2022



Lung cancer is a severe menace to human health, due to which millions of people die because of late diagnoses of cancer; thus, it is vital to detect the disease as early as possible. The Computerized chest analysis Tomography of scan is assumed to be one of the efficient solutions for detecting and classifying lung nodules. The necessity of high accuracy of analyzing C.T. scan images of the lung is considered as one of the crucial challenges in detecting and classifying lung cancer. A new long-short-term-memory (LSTM) based deep fusion structure, is introduced, where, the texture features computed from lung nodules through new volumetric grey-level-co-occurrence-matrices (GLCM) computations are applied to classify the nodules into: benign, malignant and ambiguous. An improved Otsu segmentation method combined with the water strider optimization algorithm (WSA) is proposed to detect the lung nodules. Otsu-WSA thresholding can overcome the restrictions present in previous thresholding methods. Extended experiments are run to assess this fusion structure by considering 2D-GLCM computations based 2D-slices fusion, and an approximation of this 3D-GLCM with volumetric 2.5D-GLCM computations-based LSTM fusion structure. The proposed methods are trained and assessed through the LIDC-IDRI dataset, where 94.4%, 91.6%, and 95.8% Accuracy, sensitivity, and specificity are obtained, respectively for 2D-GLCM fusion and 97.33%, 96%, and 98%, accuracy, sensitivity, and specificity, respectively, for 2.5D-GLCM fusion. The yield of the same are 98.7%, 98%, and 99%, for the 3D-GLCM fusion. The obtained results and analysis indicate that the WSA-Otsu method requires less execution time and yields a more accurate thresholding process. It is found that 3D-GLCM based LSTM outperforms its counterparts.
Weighted Least Squares Twin Support Vector Machine with Fuzzy Rough Set Theory for Imbalanced Data Classification
May 21, 2021
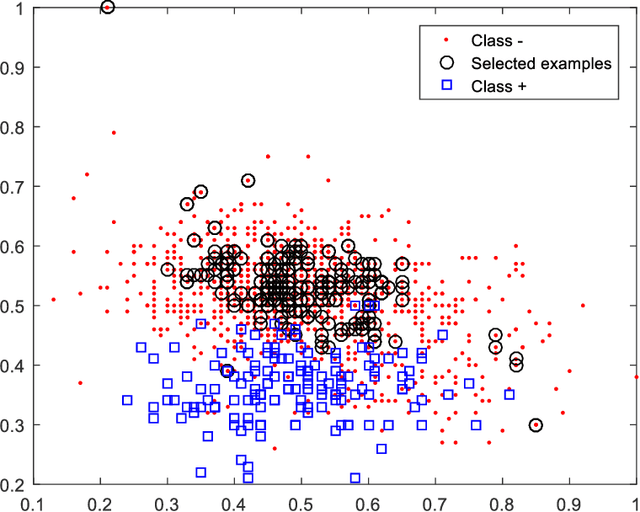

Support vector machines (SVMs) are powerful supervised learning tools developed to solve classification problems. However, SVMs are likely to perform poorly in the classification of imbalanced data. The rough set theory presents a mathematical tool for inference in nondeterministic cases that provides methods for removing irrelevant information from data. In this work, we propose an approach that efficiently used fuzzy rough set theory in weighted least squares twin support vector machine called FRLSTSVM for classification of imbalanced data. The first innovation is introducing a new fuzzy rough set-based under-sampling strategy to make the classifier robust in terms of the imbalanced data. For constructing the two proximal hyperplanes in FRLSTSVM, data points from the minority class remain unchanged while a subset of data points in the majority class are selected using a new method. In this model, we embed the weight biases in the LSTSVM formulations to overcome the bias phenomenon in the original twin SVM for the classification of imbalanced data. In order to determine these weights in this formulation, we introduce a new strategy that uses fuzzy rough set theory as the second innovation. Experimental results on the famous imbalanced datasets, compared to the related traditional SVM-based methods, demonstrate the superiority of the proposed FRLSTSVM model in the imbalanced data classification.
PCB Defect Detection Using Denoising Convolutional Autoencoders
Aug 28, 2020
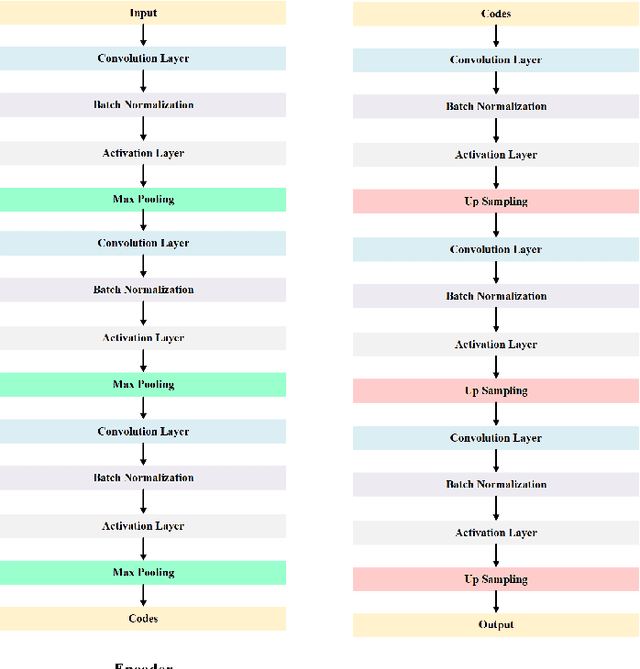


Printed Circuit boards (PCBs) are one of the most important stages in making electronic products. A small defect in PCBs can cause significant flaws in the final product. Hence, detecting all defects in PCBs and locating them is essential. In this paper, we propose an approach based on denoising convolutional autoencoders for detecting defective PCBs and to locate the defects. Denoising autoencoders take a corrupted image and try to recover the intact image. We trained our model with defective PCBs and forced it to repair the defective parts. Our model not only detects all kinds of defects and locates them, but it can also repair them as well. By subtracting the repaired output from the input, the defective parts are located. The experimental results indicate that our model detects the defective PCBs with high accuracy (97.5%) compare to state of the art works.