 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNucFuseRank: Dataset Fusion and Performance Ranking for Nuclei Instance Segmentation
Jan 27, 2026Nuclei instance segmentation in hematoxylin and eosin (H&E)-stained images plays an important role in automated histological image analysis, with various applications in downstream tasks. While several machine learning and deep learning approaches have been proposed for nuclei instance segmentation, most research in this field focuses on developing new segmentation algorithms and benchmarking them on a limited number of arbitrarily selected public datasets. In this work, rather than focusing on model development, we focused on the datasets used for this task. Based on an extensive literature review, we identified manually annotated, publicly available datasets of H&E-stained images for nuclei instance segmentation and standardized them into a unified input and annotation format. Using two state-of-the-art segmentation models, one based on convolutional neural networks (CNNs) and one based on a hybrid CNN and vision transformer architecture, we systematically evaluated and ranked these datasets based on their nuclei instance segmentation performance. Furthermore, we proposed a unified test set (NucFuse-test) for fair cross-dataset evaluation and a unified training set (NucFuse-train) for improved segmentation performance by merging images from multiple datasets. By evaluating and ranking the datasets, performing comprehensive analyses, generating fused datasets, conducting external validation, and making our implementation publicly available, we provided a new benchmark for training, testing, and evaluating nuclei instance segmentation models on H&E-stained histological images.
Developing Predictive and Robust Radiomics Models for Chemotherapy Response in High-Grade Serous Ovarian Carcinoma
Jan 13, 2026Objectives: High-grade serous ovarian carcinoma (HGSOC) is typically diagnosed at an advanced stage with extensive peritoneal metastases, making treatment challenging. Neoadjuvant chemotherapy (NACT) is often used to reduce tumor burden before surgery, but about 40% of patients show limited response. Radiomics, combined with machine learning (ML), offers a promising non-invasive method for predicting NACT response by analyzing computed tomography (CT) imaging data. This study aimed to improve response prediction in HGSOC patients undergoing NACT by integration different feature selection methods. Materials and methods: A framework for selecting robust radiomics features was introduced by employing an automated randomisation algorithm to mimic inter-observer variability, ensuring a balance between feature robustness and prediction accuracy. Four response metrics were used: chemotherapy response score (CRS), RECIST, volume reduction (VolR), and diameter reduction (DiaR). Lesions in different anatomical sites were studied. Pre- and post-NACT CT scans were used for feature extraction and model training on one cohort, and an independent cohort was used for external testing. Results: The best prediction performance was achieved using all lesions combined for VolR prediction, with an AUC of 0.83. Omental lesions provided the best results for CRS prediction (AUC 0.77), while pelvic lesions performed best for DiaR (AUC 0.76). Conclusion: The integration of robustness into the feature selection processes ensures the development of reliable models and thus facilitates the implementation of the radiomics models in clinical applications for HGSOC patients. Future work should explore further applications of radiomics in ovarian cancer, particularly in real-time clinical settings.
ACS-SegNet: An Attention-Based CNN-SegFormer Segmentation Network for Tissue Segmentation in Histopathology
Oct 23, 2025Automated histopathological image analysis plays a vital role in computer-aided diagnosis of various diseases. Among developed algorithms, deep learning-based approaches have demonstrated excellent performance in multiple tasks, including semantic tissue segmentation in histological images. In this study, we propose a novel approach based on attention-driven feature fusion of convolutional neural networks (CNNs) and vision transformers (ViTs) within a unified dual-encoder model to improve semantic segmentation performance. Evaluation on two publicly available datasets showed that our model achieved {\mu}IoU/{\mu}Dice scores of 76.79%/86.87% on the GCPS dataset and 64.93%/76.60% on the PUMA dataset, outperforming state-of-the-art and baseline benchmarks. The implementation of our method is publicly available in a GitHub repository: https://github.com/NimaTorbati/ACS-SegNet
Fusion of Foundation and Vision Transformer Model Features for Dermatoscopic Image Classification
May 22, 2025Accurate classification of skin lesions from dermatoscopic images is essential for diagnosis and treatment of skin cancer. In this study, we investigate the utility of a dermatology-specific foundation model, PanDerm, in comparison with two Vision Transformer (ViT) architectures (ViT base and Swin Transformer V2 base) for the task of skin lesion classification. Using frozen features extracted from PanDerm, we apply non-linear probing with three different classifiers, namely, multi-layer perceptron (MLP), XGBoost, and TabNet. For the ViT-based models, we perform full fine-tuning to optimize classification performance. Our experiments on the HAM10000 and MSKCC datasets demonstrate that the PanDerm-based MLP model performs comparably to the fine-tuned Swin transformer model, while fusion of PanDerm and Swin Transformer predictions leads to further performance improvements. Future work will explore additional foundation models, fine-tuning strategies, and advanced fusion techniques.
A Multi-Stage Auto-Context Deep Learning Framework for Tissue and Nuclei Segmentation and Classification in H&E-Stained Histological Images of Advanced Melanoma
Mar 31, 2025



Melanoma is the most lethal form of skin cancer, with an increasing incidence rate worldwide. Analyzing histological images of melanoma by localizing and classifying tissues and cell nuclei is considered the gold standard method for diagnosis and treatment options for patients. While many computerized approaches have been proposed for automatic analysis, most perform tissue-based analysis and nuclei (cell)-based analysis as separate tasks, which might be suboptimal. In this work, using the PUMA challenge dataset, we proposed a novel multi-stage deep learning approach by combining tissue and nuclei information in a unified framework based on the auto-context concept to perform segmentation and classification in histological images of melanoma. Through pre-training and further post-processing, our approach achieved second and first place rankings in the PUMA challenge, with average micro Dice tissue score and summed nuclei F1-score of 73.40% for Track 1 and 63.48% for Track 2, respectively. Our implementation for training and testing is available at: https://github.com/NimaTorbati/PumaSubmit
Evaluating Pre-trained Convolutional Neural Networks and Foundation Models as Feature Extractors for Content-based Medical Image Retrieval
Sep 14, 2024


Medical image retrieval refers to the task of finding similar images for given query images in a database, with applications such as diagnosis support, treatment planning, and educational tools for inexperienced medical practitioners. While traditional medical image retrieval was performed using clinical metadata, content-based medical image retrieval (CBMIR) relies on the characteristic features of the images, such as color, texture, shape, and spatial features. Many approaches have been proposed for CBMIR, and among them, using pre-trained convolutional neural networks (CNNs) is a widely utilized approach. However, considering the recent advances in the development of foundation models for various computer vision tasks, their application for CBMIR can be also investigated for its potentially superior performance. In this study, we used several pre-trained feature extractors from well-known pre-trained CNNs (VGG19, ResNet-50, DenseNet121, and EfficientNetV2M) and pre-trained foundation models (MedCLIP, BioMedCLIP, OpenCLIP, CONCH and UNI) and investigated the CBMIR performance on a subset of the MedMNIST V2 dataset, including eight types of 2D and 3D medical images. Furthermore, we also investigated the effect of image size on the CBMIR performance. Our results show that, overall, for the 2D datasets, foundation models deliver superior performance by a large margin compared to CNNs, with UNI providing the best overall performance across all datasets and image sizes. For 3D datasets, CNNs and foundation models deliver more competitive performance, with CONCH achieving the best overall performance. Moreover, our findings confirm that while using larger image sizes (especially for 2D datasets) yields slightly better performance, competitive CBMIR performance can still be achieved even with smaller image sizes. Our codes to generate and reproduce the results are available on GitHub.
WCEbleedGen: A wireless capsule endoscopy dataset and its benchmarking for automatic bleeding classification, detection, and segmentation
Aug 22, 2024



Computer-based analysis of Wireless Capsule Endoscopy (WCE) is crucial. However, a medically annotated WCE dataset for training and evaluation of automatic classification, detection, and segmentation of bleeding and non-bleeding frames is currently lacking. The present work focused on development of a medically annotated WCE dataset called WCEbleedGen for automatic classification, detection, and segmentation of bleeding and non-bleeding frames. It comprises 2,618 WCE bleeding and non-bleeding frames which were collected from various internet resources and existing WCE datasets. A comprehensive benchmarking and evaluation of the developed dataset was done using nine classification-based, three detection-based, and three segmentation-based deep learning models. The dataset is of high-quality, is class-balanced and contains single and multiple bleeding sites. Overall, our standard benchmark results show that Visual Geometric Group (VGG) 19, You Only Look Once version 8 nano (YOLOv8n), and Link network (Linknet) performed best in automatic classification, detection, and segmentation-based evaluations, respectively. Automatic bleeding diagnosis is crucial for WCE video interpretations. This diverse dataset will aid in developing of real-time, multi-task learning-based innovative solutions for automatic bleeding diagnosis in WCE. The dataset and code are publicly available at https://zenodo.org/records/10156571 and https://github.com/misahub2023/Benchmarking-Codes-of-the-WCEBleedGen-dataset.
Capsule Vision 2024 Challenge: Multi-Class Abnormality Classification for Video Capsule Endoscopy
Aug 09, 2024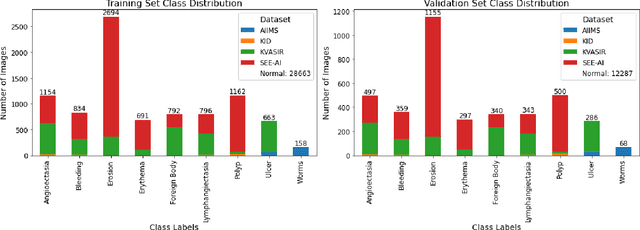
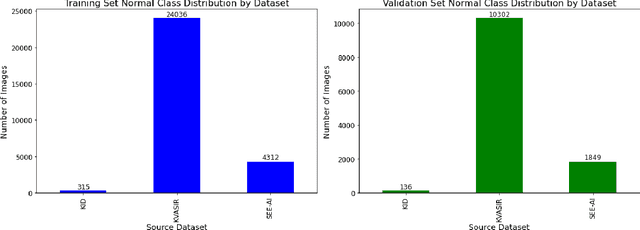
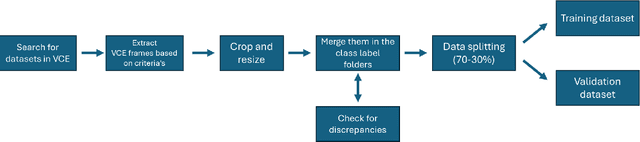

We present the Capsule Vision 2024 Challenge: Multi-Class Abnormality Classification for Video Capsule Endoscopy. It is being virtually organized by the Research Center for Medical Image Analysis and Artificial Intelligence (MIAAI), Department of Medicine, Danube Private University, Krems, Austria and Medical Imaging and Signal Analysis Hub (MISAHUB) in collaboration with the 9th International Conference on Computer Vision & Image Processing (CVIP 2024) being organized by the Indian Institute of Information Technology, Design and Manufacturing (IIITDM) Kancheepuram, Chennai, India. This document describes the overview of the challenge, its registration and rules, submission format, and the description of the utilized datasets.
Breast Histopathology Image Retrieval by Attention-based Adversarially Regularized Variational Graph Autoencoder with Contrastive Learning-Based Feature Extraction
May 07, 2024



Breast cancer is a significant global health concern, particularly for women. Early detection and appropriate treatment are crucial in mitigating its impact, with histopathology examinations playing a vital role in swift diagnosis. However, these examinations often require a substantial workforce and experienced medical experts for proper recognition and cancer grading. Automated image retrieval systems have the potential to assist pathologists in identifying cancerous tissues, thereby accelerating the diagnostic process. Nevertheless, due to considerable variability among the tissue and cell patterns in histological images, proposing an accurate image retrieval model is very challenging. This work introduces a novel attention-based adversarially regularized variational graph autoencoder model for breast histological image retrieval. Additionally, we incorporated cluster-guided contrastive learning as the graph feature extractor to boost the retrieval performance. We evaluated the proposed model's performance on two publicly available datasets of breast cancer histological images and achieved superior or very competitive retrieval performance, with average mAP scores of 96.5% for the BreakHis dataset and 94.7% for the BACH dataset, and mVP scores of 91.9% and 91.3%, respectively. Our proposed retrieval model has the potential to be used in clinical settings to enhance diagnostic performance and ultimately benefit patients.
Improving Generalization Capability of Deep Learning-Based Nuclei Instance Segmentation by Non-deterministic Train Time and Deterministic Test Time Stain Normalization
Sep 12, 2023



With the advent of digital pathology and microscopic systems that can scan and save whole slide histological images automatically, there is a growing trend to use computerized methods to analyze acquired images. Among different histopathological image analysis tasks, nuclei instance segmentation plays a fundamental role in a wide range of clinical and research applications. While many semi- and fully-automatic computerized methods have been proposed for nuclei instance segmentation, deep learning (DL)-based approaches have been shown to deliver the best performances. However, the performance of such approaches usually degrades when tested on unseen datasets. In this work, we propose a novel approach to improve the generalization capability of a DL-based automatic segmentation approach. Besides utilizing one of the state-of-the-art DL-based models as a baseline, our method incorporates non-deterministic train time and deterministic test time stain normalization. We trained the model with one single training set and evaluated its segmentation performance on seven test datasets. Our results show that the proposed method provides up to 5.77%, 5.36%, and 5.27% better performance in segmenting nuclei based on Dice score, aggregated Jaccard index, and panoptic quality score, respectively, compared to the baseline segmentation model.