 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Troubling Emergence of Hallucination in Large Language Models -- An Extensive Definition, Quantification, and Prescriptive Remediations
Oct 08, 2023The recent advancements in Large Language Models (LLMs) have garnered widespread acclaim for their remarkable emerging capabilities. However, the issue of hallucination has parallelly emerged as a by-product, posing significant concerns. While some recent endeavors have been made to identify and mitigate different types of hallucination, there has been a limited emphasis on the nuanced categorization of hallucination and associated mitigation methods. To address this gap, we offer a fine-grained discourse on profiling hallucination based on its degree, orientation, and category, along with offering strategies for alleviation. As such, we define two overarching orientations of hallucination: (i) factual mirage (FM) and (ii) silver lining (SL). To provide a more comprehensive understanding, both orientations are further sub-categorized into intrinsic and extrinsic, with three degrees of severity - (i) mild, (ii) moderate, and (iii) alarming. We also meticulously categorize hallucination into six types: (i) acronym ambiguity, (ii) numeric nuisance, (iii) generated golem, (iv) virtual voice, (v) geographic erratum, and (vi) time wrap. Furthermore, we curate HallucInation eLiciTation (HILT), a publicly available dataset comprising of 75,000 samples generated using 15 contemporary LLMs along with human annotations for the aforementioned categories. Finally, to establish a method for quantifying and to offer a comparative spectrum that allows us to evaluate and rank LLMs based on their vulnerability to producing hallucinations, we propose Hallucination Vulnerability Index (HVI). We firmly believe that HVI holds significant value as a tool for the wider NLP community, with the potential to serve as a rubric in AI-related policy-making. In conclusion, we propose two solution strategies for mitigating hallucinations.
Evaluating Impact of Social Media Posts by Executives on Stock Prices
Nov 01, 2022Predicting stock market movements has always been of great interest to investors and an active area of research. Research has proven that popularity of products is highly influenced by what people talk about. Social media like Twitter, Reddit have become hotspots of such influences. This paper investigates the impact of social media posts on close price prediction of stocks using Twitter and Reddit posts. Our objective is to integrate sentiment of social media data with historical stock data and study its effect on closing prices using time series models. We carried out rigorous experiments and deep analysis using multiple deep learning based models on different datasets to study the influence of posts by executives and general people on the close price. Experimental results on multiple stocks (Apple and Tesla) and decentralised currencies (Bitcoin and Ethereum) consistently show improvements in prediction on including social media data and greater improvements on including executive posts.
SIR: Similar Image Retrieval for Product Search in E-Commerce
Sep 29, 2020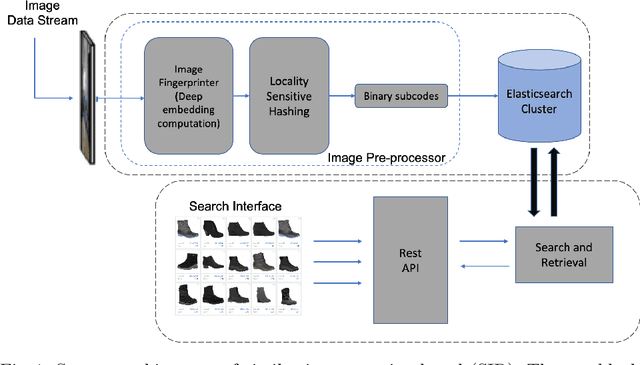
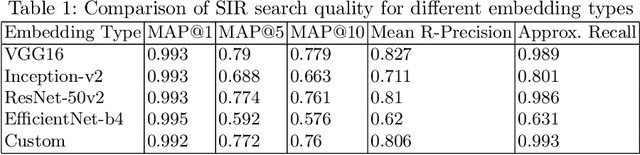
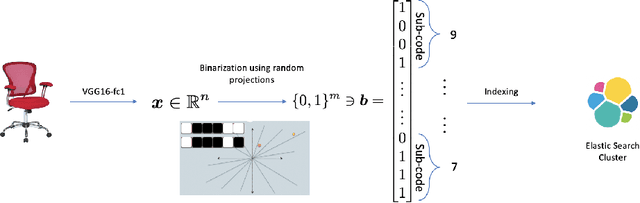

We present a similar image retrieval (SIR) platform that is used to quickly discover visually similar products in a catalog of millions. Given the size, diversity, and dynamism of our catalog, product search poses many challenges. It can be addressed by building supervised models to tagging product images with labels representing themes and later retrieving them by labels. This approach suffices for common and perennial themes like "white shirt" or "lifestyle image of TV". It does not work for new themes such as "e-cigarettes", hard-to-define ones such as "image with a promotional badge", or the ones with short relevance span such as "Halloween costumes". SIR is ideal for such cases because it allows us to search by an example, not a pre-defined theme. We describe the steps - embedding computation, encoding, and indexing - that power the approximate nearest neighbor search back-end. We also highlight two applications of SIR. The first one is related to the detection of products with various types of potentially objectionable themes. This application is run with a sense of urgency, hence the typical time frame to train and bootstrap a model is not permitted. Also, these themes are often short-lived based on current trends, hence spending resources to build a lasting model is not justified. The second application is a variant item detection system where SIR helps discover visual variants that are hard to find through text search. We analyze the performance of SIR in the context of these applications.