 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIR: Similar Image Retrieval for Product Search in E-Commerce
Sep 29, 2020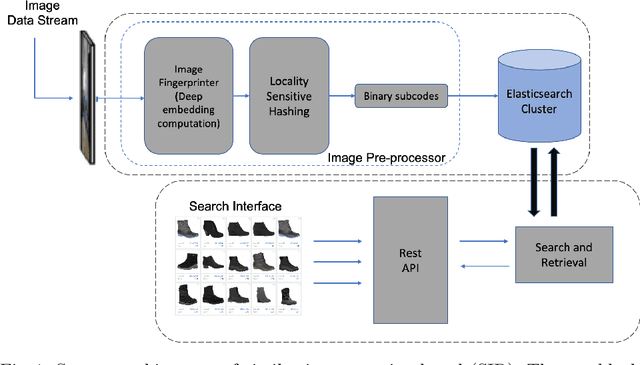
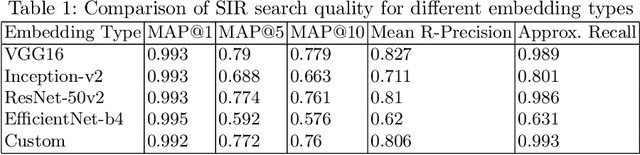
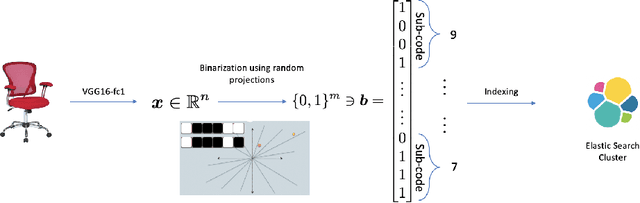

We present a similar image retrieval (SIR) platform that is used to quickly discover visually similar products in a catalog of millions. Given the size, diversity, and dynamism of our catalog, product search poses many challenges. It can be addressed by building supervised models to tagging product images with labels representing themes and later retrieving them by labels. This approach suffices for common and perennial themes like "white shirt" or "lifestyle image of TV". It does not work for new themes such as "e-cigarettes", hard-to-define ones such as "image with a promotional badge", or the ones with short relevance span such as "Halloween costumes". SIR is ideal for such cases because it allows us to search by an example, not a pre-defined theme. We describe the steps - embedding computation, encoding, and indexing - that power the approximate nearest neighbor search back-end. We also highlight two applications of SIR. The first one is related to the detection of products with various types of potentially objectionable themes. This application is run with a sense of urgency, hence the typical time frame to train and bootstrap a model is not permitted. Also, these themes are often short-lived based on current trends, hence spending resources to build a lasting model is not justified. The second application is a variant item detection system where SIR helps discover visual variants that are hard to find through text search. We analyze the performance of SIR in the context of these applications.
A Visual Technique to Analyze Flow of Information in a Machine Learning System
Aug 02, 2019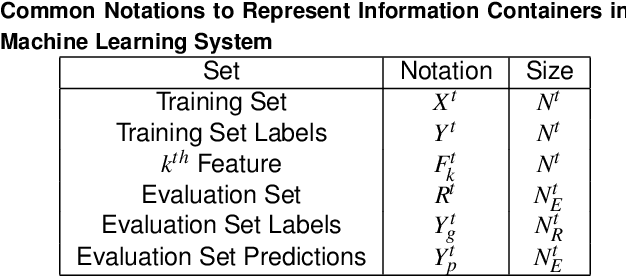

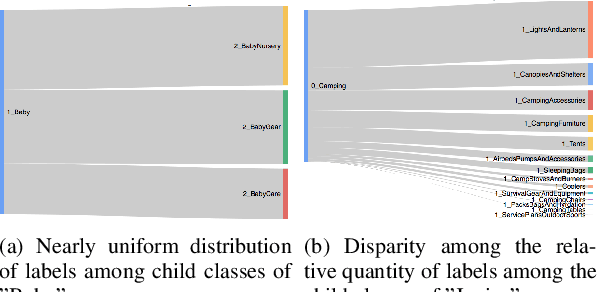
Machine learning (ML) algorithms and machine learning based software systems implicitly or explicitly involve complex flow of information between various entities such as training data, feature space, validation set and results. Understanding the statistical distribution of such information and how they flow from one entity to another influence the operation and correctness of such systems, especially in large-scale applications that perform classification or prediction in real time. In this paper, we propose a visual approach to understand and analyze flow of information during model training and serving phases. We build the visualizations using a technique called Sankey Diagram - conventionally used to understand data flow among sets - to address various use cases of in a machine learning system. We demonstrate how the proposed technique, tweaked and twisted to suit a classification problem, can play a critical role in better understanding of the training data, the features, and the classifier performance. We also discuss how this technique enables diagnostic analysis of model predictions and comparative analysis of predictions from multiple classifiers. The proposed concept is illustrated with the example of categorization of millions of products in the e-commerce domain - a multi-class hierarchical classification problem.
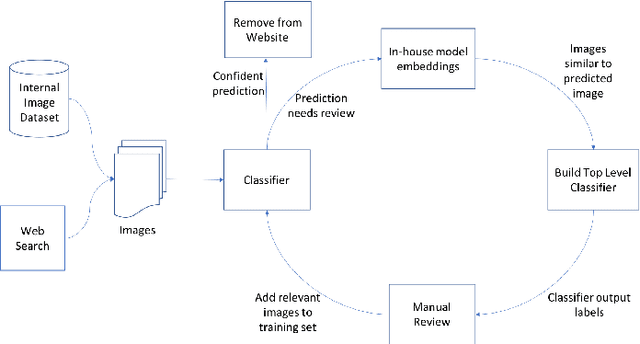
Image Matters: Detecting Offensive and Non-Compliant Content / Logo in Product Images
May 06, 2019
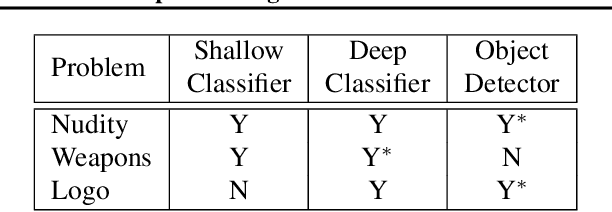

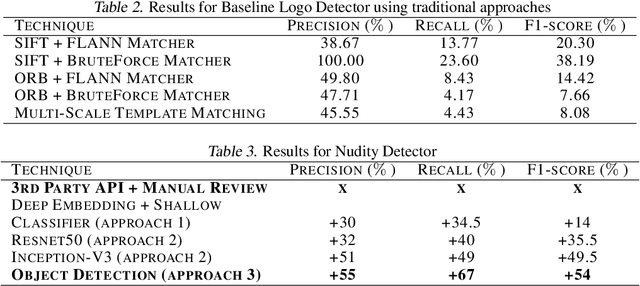
In e-commerce, product content, especially product images have a significant influence on a customer's journey from product discovery to evaluation and finally, purchase decision. Since many e-commerce retailers sell items from other third-party marketplace sellers besides their own, the content published by both internal and external content creators needs to be monitored and enriched, wherever possible. Despite guidelines and warnings, product listings that contain offensive and non-compliant images continue to enter catalogs. Offensive and non-compliant content can include a wide range of objects, logos, and banners conveying violent, sexually explicit, racist, or promotional messages. Such images can severely damage the customer experience, lead to legal issues, and erode the company brand. In this paper, we present a machine learning driven offensive and non-compliant image detection system for extremely large e-commerce catalogs. This system proactively detects and removes such content before they are published to the customer-facing website. This paper delves into the unique challenges of applying machine learning to real-world data from retail domain with hundreds of millions of product images. We demonstrate how we resolve the issue of non-compliant content that appears across tens of thousands of product categories. We also describe how we deal with the sheer variety in which each single non-compliant scenario appears. This paper showcases a number of practical yet unique approaches such as representative training data creation that are critical to solve an extremely rarely occurring problem. In summary, our system combines state-of-the-art image classification and object detection techniques, and fine tunes them with internal data to develop a solution customized for a massive, diverse, and constantly evolving product catalog.
A Smart System for Selection of Optimal Product Images in E-Commerce
Nov 12, 2018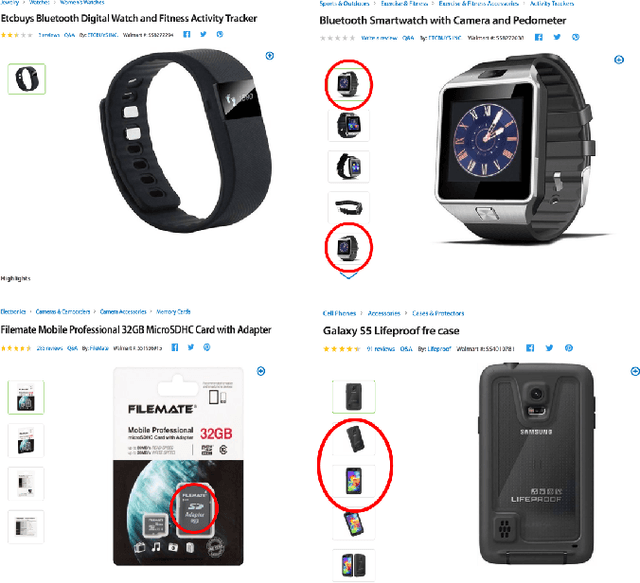
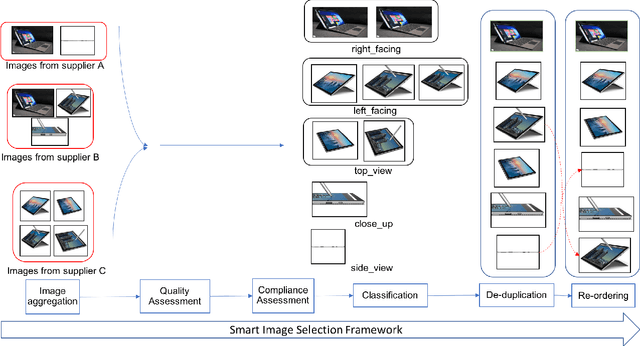
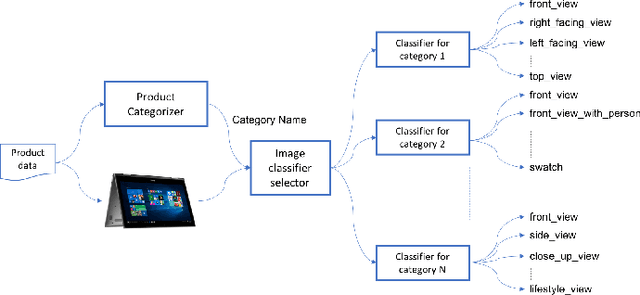
In e-commerce, content quality of the product catalog plays a key role in delivering a satisfactory experience to the customers. In particular, visual content such as product images influences customers' engagement and purchase decisions. With the rapid growth of e-commerce and the advent of artificial intelligence, traditional content management systems are giving way to automated scalable systems. In this paper, we present a machine learning driven visual content management system for extremely large e-commerce catalogs. For a given product, the system aggregates images from various suppliers, understands and analyzes them to produce a superior image set with optimal image count and quality, and arranges them in an order tailored to the demands of the customers. The system makes use of an array of technologies, ranging from deep learning to traditional computer vision, at different stages of analysis. In this paper, we outline how the system works and discuss the unique challenges related to applying machine learning techniques to real-world data from e-commerce domain. We emphasize how we tune state-of-the-art image classification techniques to develop solutions custom made for a massive, diverse, and constantly evolving product catalog. We also provide the details of how we measure the system's impact on various customer engagement metrics.