 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
Aug 31, 2023



We present Belebele, a multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. Significantly expanding the language coverage of natural language understanding (NLU) benchmarks, this dataset enables the evaluation of text models in high-, medium-, and low-resource languages. Each question is based on a short passage from the Flores-200 dataset and has four multiple-choice answers. The questions were carefully curated to discriminate between models with different levels of general language comprehension. The English dataset on its own proves difficult enough to challenge state-of-the-art language models. Being fully parallel, this dataset enables direct comparison of model performance across all languages. We use this dataset to evaluate the capabilities of multilingual masked language models (MLMs) and large language models (LLMs). We present extensive results and find that despite significant cross-lingual transfer in English-centric LLMs, much smaller MLMs pretrained on balanced multilingual data still understand far more languages. We also observe that larger vocabulary size and conscious vocabulary construction correlate with better performance on low-resource languages. Overall, Belebele opens up new avenues for evaluating and analyzing the multilingual capabilities of NLP systems.
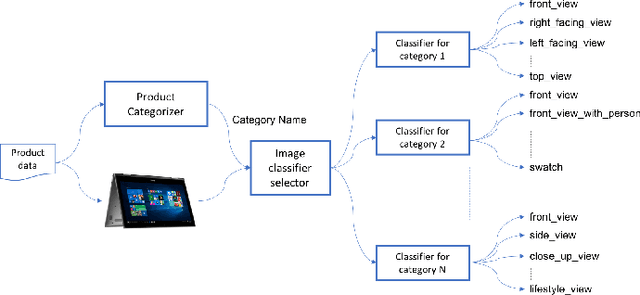
Large Scale Product Categorization using Structured and Unstructured Attributes
Mar 01, 2019



Product categorization using text data for eCommerce is a very challenging extreme classification problem with several thousands of classes and several millions of products to classify. Even though multi-class text classification is a well studied problem both in academia and industry, most approaches either deal with treating product content as a single pile of text, or only consider a few product attributes for modelling purposes. Given the variety of products sold on popular eCommerce platforms, it is hard to consider all available product attributes as part of the modeling exercise, considering that products possess their own unique set of attributes based on category. In this paper, we compare hierarchical models to flat models and show that in specific cases, flat models perform better. We explore two Deep Learning based models that extract features from individual pieces of unstructured data from each product and then combine them to create a product signature. We also propose a novel idea of using structured attributes and their values together in an unstructured fashion along with convolutional filters such that the ordering of the attributes and the differing attributes by product categories no longer becomes a modelling challenge. This approach is also more robust to the presence of faulty product attribute names and values and can elegantly generalize to use both closed list and open list attributes.
A Smart System for Selection of Optimal Product Images in E-Commerce
Nov 12, 2018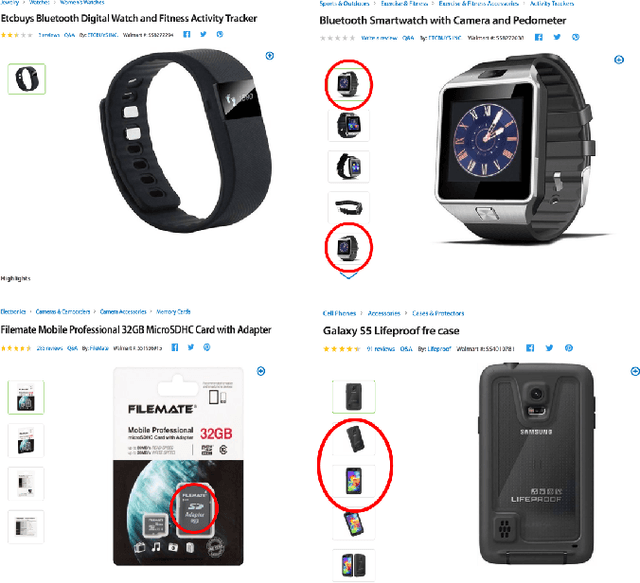
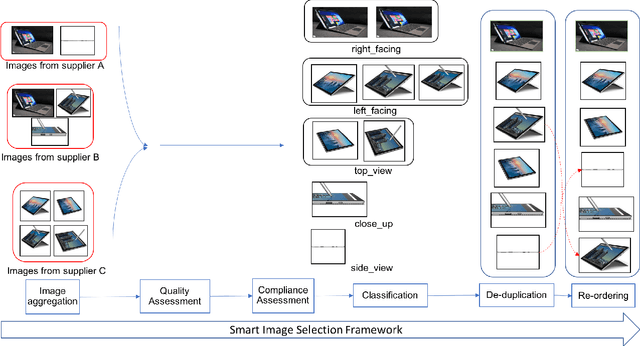
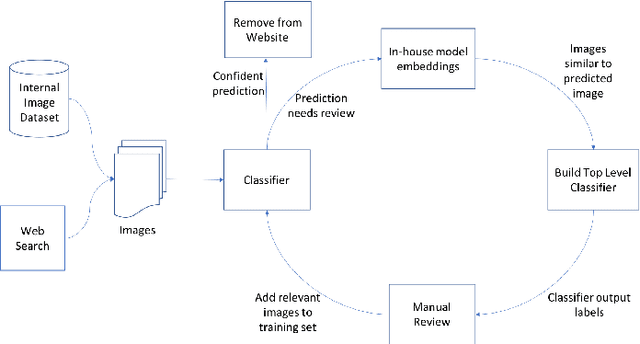
In e-commerce, content quality of the product catalog plays a key role in delivering a satisfactory experience to the customers. In particular, visual content such as product images influences customers' engagement and purchase decisions. With the rapid growth of e-commerce and the advent of artificial intelligence, traditional content management systems are giving way to automated scalable systems. In this paper, we present a machine learning driven visual content management system for extremely large e-commerce catalogs. For a given product, the system aggregates images from various suppliers, understands and analyzes them to produce a superior image set with optimal image count and quality, and arranges them in an order tailored to the demands of the customers. The system makes use of an array of technologies, ranging from deep learning to traditional computer vision, at different stages of analysis. In this paper, we outline how the system works and discuss the unique challenges related to applying machine learning techniques to real-world data from e-commerce domain. We emphasize how we tune state-of-the-art image classification techniques to develop solutions custom made for a massive, diverse, and constantly evolving product catalog. We also provide the details of how we measure the system's impact on various customer engagement metrics.
Deep Recurrent Neural Networks for Product Attribute Extraction in eCommerce
Mar 29, 2018
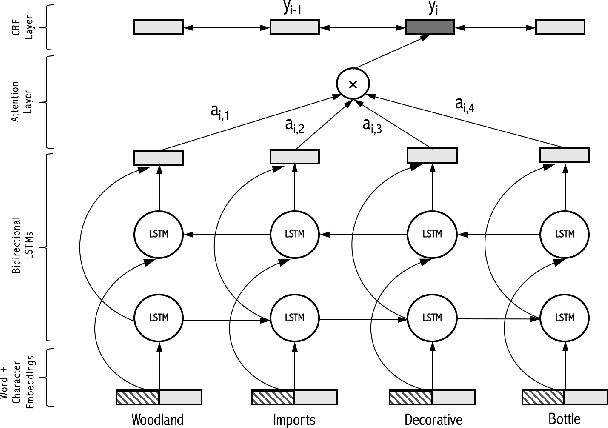
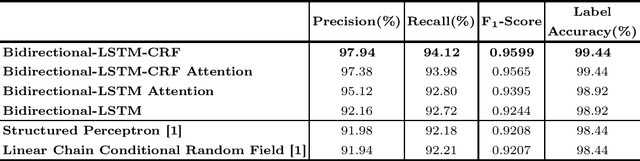
Extracting accurate attribute qualities from product titles is a vital component in delivering eCommerce customers with a rewarding online shopping experience via an enriched faceted search. We demonstrate the potential of Deep Recurrent Networks in this domain, primarily models such as Bidirectional LSTMs and Bidirectional LSTM-CRF with or without an attention mechanism. These have improved overall F1 scores, as compared to the previous benchmarks (More et al.) by at least 0.0391, showcasing an overall precision of 97.94%, recall of 94.12% and the F1 score of 0.9599. This has made us achieve a significant coverage of important facets or attributes of products which not only shows the efficacy of deep recurrent models over previous machine learning benchmarks but also greatly enhances the overall customer experience while shopping online.
Is a picture worth a thousand words? A Deep Multi-Modal Fusion Architecture for Product Classification in e-commerce
Nov 29, 2016



Classifying products into categories precisely and efficiently is a major challenge in modern e-commerce. The high traffic of new products uploaded daily and the dynamic nature of the categories raise the need for machine learning models that can reduce the cost and time of human editors. In this paper, we propose a decision level fusion approach for multi-modal product classification using text and image inputs. We train input specific state-of-the-art deep neural networks for each input source, show the potential of forging them together into a multi-modal architecture and train a novel policy network that learns to choose between them. Finally, we demonstrate that our multi-modal network improves the top-1 accuracy % over both networks on a real-world large-scale product classification dataset that we collected fromWalmart.com. While we focus on image-text fusion that characterizes e-commerce domains, our algorithms can be easily applied to other modalities such as audio, video, physical sensors, etc.