 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Recurrent Neural Networks for Product Attribute Extraction in eCommerce
Mar 29, 2018
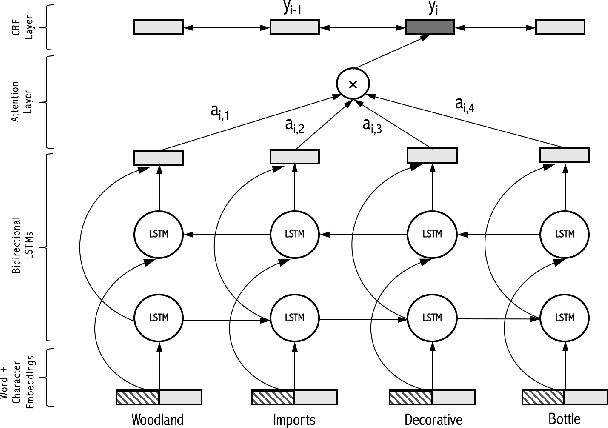
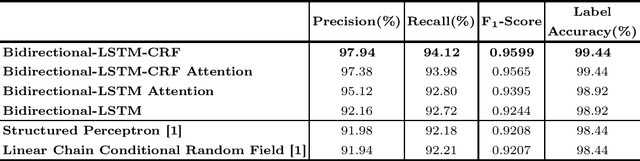
Extracting accurate attribute qualities from product titles is a vital component in delivering eCommerce customers with a rewarding online shopping experience via an enriched faceted search. We demonstrate the potential of Deep Recurrent Networks in this domain, primarily models such as Bidirectional LSTMs and Bidirectional LSTM-CRF with or without an attention mechanism. These have improved overall F1 scores, as compared to the previous benchmarks (More et al.) by at least 0.0391, showcasing an overall precision of 97.94%, recall of 94.12% and the F1 score of 0.9599. This has made us achieve a significant coverage of important facets or attributes of products which not only shows the efficacy of deep recurrent models over previous machine learning benchmarks but also greatly enhances the overall customer experience while shopping online.
Survey of resampling techniques for improving classification performance in unbalanced datasets
Aug 22, 2016A number of classification problems need to deal with data imbalance between classes. Often it is desired to have a high recall on the minority class while maintaining a high precision on the majority class. In this paper, we review a number of resampling techniques proposed in literature to handle unbalanced datasets and study their effect on classification performance.
Attribute Extraction from Product Titles in eCommerce
Aug 15, 2016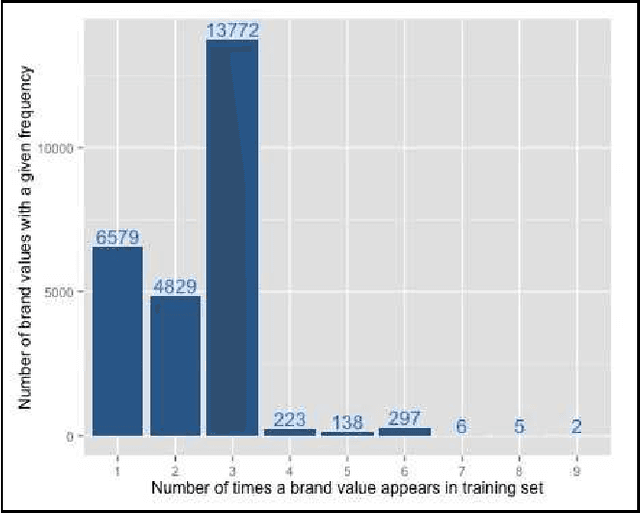
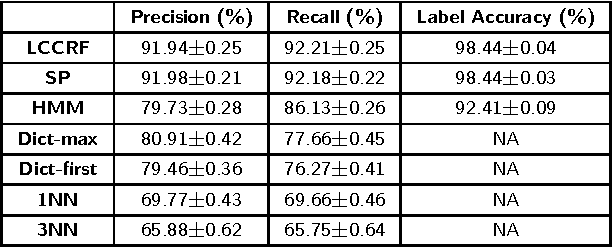
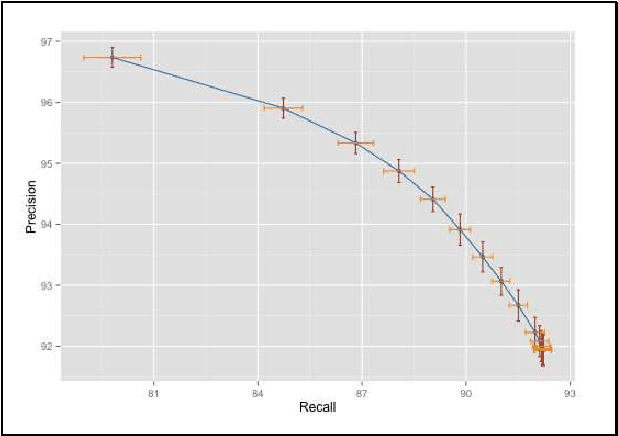
This paper presents a named entity extraction system for detecting attributes in product titles of eCommerce retailers like Walmart. The absence of syntactic structure in such short pieces of text makes extracting attribute values a challenging problem. We find that combining sequence labeling algorithms such as Conditional Random Fields and Structured Perceptron with a curated normalization scheme produces an effective system for the task of extracting product attribute values from titles. To keep the discussion concrete, we will illustrate the mechanics of the system from the point of view of a particular attribute - brand. We also discuss the importance of an attribute extraction system in the context of retail websites with large product catalogs, compare our approach to other potential approaches to this problem and end the paper with a discussion of the performance of our system for extracting attributes.