 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMIC: Multi-Modal Indian Earnings Calls Dataset to Predict Stock Prices
Apr 12, 2025


Predicting stock market prices following corporate earnings calls remains a significant challenge for investors and researchers alike, requiring innovative approaches that can process diverse information sources. This study investigates the impact of corporate earnings calls on stock prices by introducing a multi-modal predictive model. We leverage textual data from earnings call transcripts, along with images and tables from accompanying presentations, to forecast stock price movements on the trading day immediately following these calls. To facilitate this research, we developed the MiMIC (Multi-Modal Indian Earnings Calls) dataset, encompassing companies representing the Nifty 50, Nifty MidCap 50, and Nifty Small 50 indices. The dataset includes earnings call transcripts, presentations, fundamentals, technical indicators, and subsequent stock prices. We present a multimodal analytical framework that integrates quantitative variables with predictive signals derived from textual and visual modalities, thereby enabling a holistic approach to feature representation and analysis. This multi-modal approach demonstrates the potential for integrating diverse information sources to enhance financial forecasting accuracy. To promote further research in computational economics, we have made the MiMIC dataset publicly available under the CC-NC-SA-4.0 licence. Our work contributes to the growing body of literature on market reactions to corporate communications and highlights the efficacy of multi-modal machine learning techniques in financial analysis.
Generator-Guided Crowd Reaction Assessment
Mar 08, 2024In the realm of social media, understanding and predicting post reach is a significant challenge. This paper presents a Crowd Reaction AssessMent (CReAM) task designed to estimate if a given social media post will receive more reaction than another, a particularly essential task for digital marketers and content writers. We introduce the Crowd Reaction Estimation Dataset (CRED), consisting of pairs of tweets from The White House with comparative measures of retweet count. The proposed Generator-Guided Estimation Approach (GGEA) leverages generative Large Language Models (LLMs), such as ChatGPT, FLAN-UL2, and Claude, to guide classification models for making better predictions. Our results reveal that a fine-tuned FLANG-RoBERTa model, utilizing a cross-encoder architecture with tweet content and responses generated by Claude, performs optimally. We further use a T5-based paraphraser to generate paraphrases of a given post and demonstrate GGEA's ability to predict which post will elicit the most reactions. We believe this novel application of LLMs provides a significant advancement in predicting social media post reach.
Learning Semantic Text Similarity to rank Hypernyms of Financial Terms
Mar 20, 2023Over the years, there has been a paradigm shift in how users access financial services. With the advancement of digitalization more users have been preferring the online mode of performing financial activities. This has led to the generation of a huge volume of financial content. Most investors prefer to go through these contents before making decisions. Every industry has terms that are specific to the domain it operates in. Banking and Financial Services are not an exception to this. In order to fully comprehend these contents, one needs to have a thorough understanding of the financial terms. Getting a basic idea about a term becomes easy when it is explained with the help of the broad category to which it belongs. This broad category is referred to as hypernym. For example, "bond" is a hypernym of the financial term "alternative debenture". In this paper, we propose a system capable of extracting and ranking hypernyms for a given financial term. The system has been trained with financial text corpora obtained from various sources like DBpedia [4], Investopedia, Financial Industry Business Ontology (FIBO), prospectus and so on. Embeddings of these terms have been extracted using FinBERT [3], FinISH [1] and fine-tuned using SentenceBERT [54]. A novel approach has been used to augment the training set with negative samples. It uses the hierarchy present in FIBO. Finally, we benchmark the system performance with that of the existing ones. We establish that it performs better than the existing ones and is also scalable.
Evaluating Impact of Social Media Posts by Executives on Stock Prices
Nov 01, 2022Predicting stock market movements has always been of great interest to investors and an active area of research. Research has proven that popularity of products is highly influenced by what people talk about. Social media like Twitter, Reddit have become hotspots of such influences. This paper investigates the impact of social media posts on close price prediction of stocks using Twitter and Reddit posts. Our objective is to integrate sentiment of social media data with historical stock data and study its effect on closing prices using time series models. We carried out rigorous experiments and deep analysis using multiple deep learning based models on different datasets to study the influence of posts by executives and general people on the close price. Experimental results on multiple stocks (Apple and Tesla) and decentralised currencies (Bitcoin and Ethereum) consistently show improvements in prediction on including social media data and greater improvements on including executive posts.
FiNCAT: Financial Numeral Claim Analysis Tool
Jan 26, 2022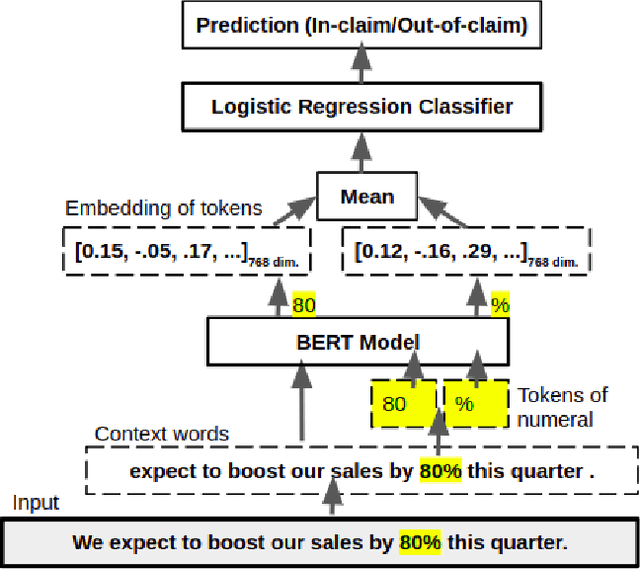
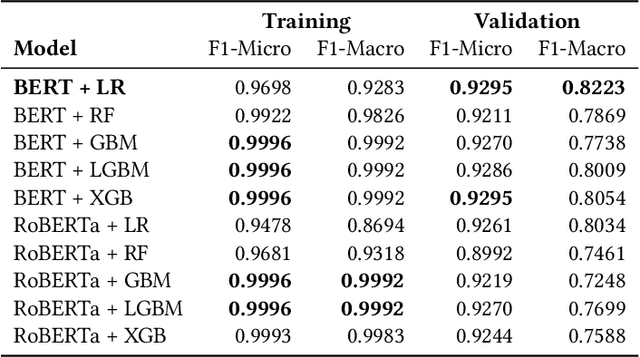
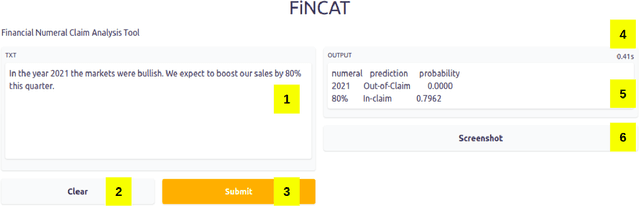
While making investment decisions by reading financial documents, investors need to differentiate between in-claim and outof-claim numerals. In this paper, we present a tool which does it automatically. It extracts context embeddings of the numerals using one of the transformer based pre-trained language model called BERT. After this, it uses a Logistic Regression based model to detect whether the numerals is in-claim or out-of-claim. We use FinNum-3 (English) dataset to train our model. After conducting rigorous experiments we achieve a Macro F1 score of 0.8223 on the validation set. We have open-sourced this tool and it can be accessed from https://github.com/sohomghosh/FiNCAT_Financial_Numeral_Claim_Analysis_Tool
Using Natural Language Processing to Understand Reasons and Motivators Behind Customer Calls in Financial Domain
Oct 18, 2021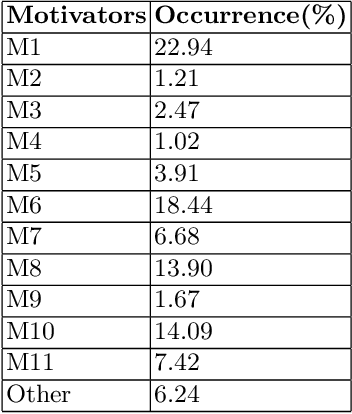
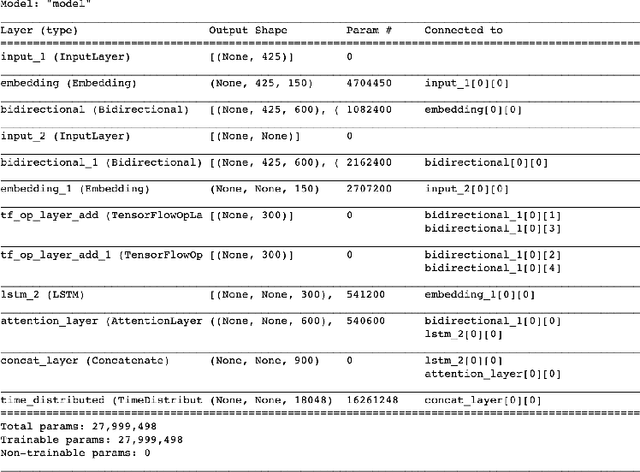
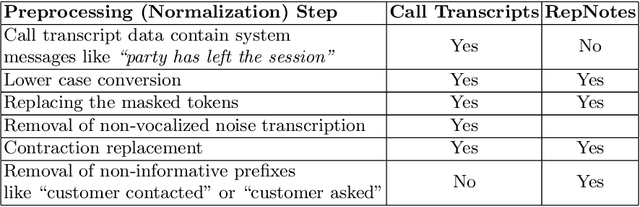
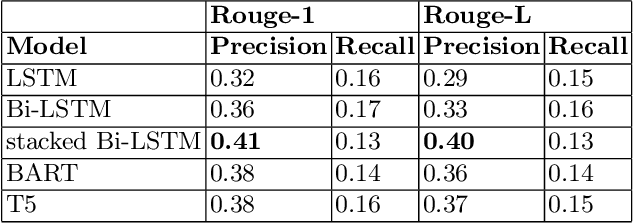
In this era of abundant digital information, customer satisfaction has become one of the prominent factors in the success of any business. Customers want a one-click solution for almost everything. They tend to get unsatisfied if they have to call about something which they could have done online. Moreover, incoming calls are a high-cost component for any business. Thus, it is essential to develop a framework capable of mining the reasons and motivators behind customer calls. This paper proposes two models. Firstly, an attention-based stacked bidirectional Long Short Term Memory Network followed by Hierarchical Clustering for extracting these reasons from transcripts of inbound calls. Secondly, a set of ensemble models based on probabilities from Support Vector Machines and Logistic Regression. It is capable of detecting factors that led to these calls. Extensive evaluation proves the effectiveness of these models.
Data Driven Content Creation using Statistical and Natural Language Processing Techniques for Financial Domain
Sep 07, 2021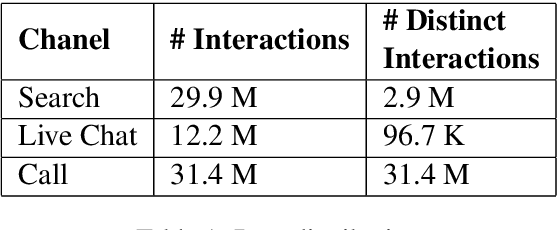
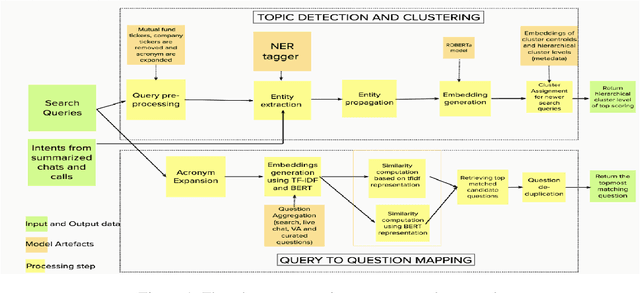
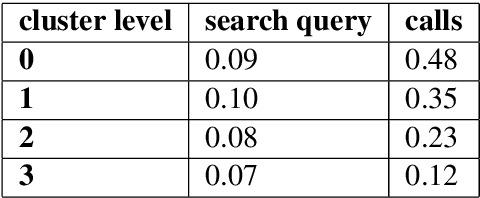
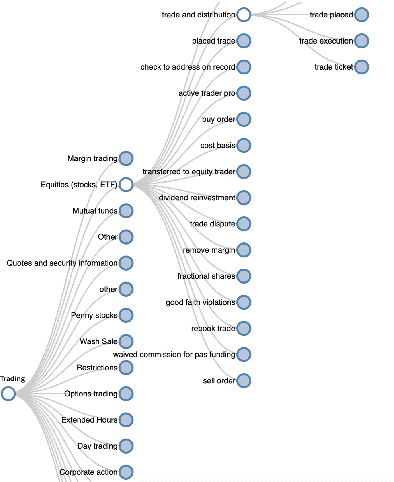
Over the years customers' expectation of getting information instantaneously has given rise to the increased usage of channels like virtual assistants. Typically, customers try to get their questions answered by low-touch channels like search and virtual assistant first, before getting in touch with a live chat agent or the phone representative. Higher usage of these low-touch systems is a win-win for both customers and the organization since it enables organizations to attain a low cost of service while customers get served without delay. In this paper, we propose a two-part framework where the first part describes methods to combine the information from different interaction channels like call, search, and chat. We do this by summarizing (using a stacked Bi-LSTM network) the high-touch interaction channel data such as call and chat into short searchquery like customer intents and then creating an organically grown intent taxonomy from interaction data (using Hierarchical Agglomerative Clustering). The second part of the framework focuses on extracting customer questions by analyzing interaction data sources. It calculates similarity scores using TF-IDF and BERT(Devlin et al., 2019). It also maps these identified questions to the output of the first part of the framework using syntactic and semantic similarity.
Term Expansion and FinBERT fine-tuning for Hypernym and Synonym Ranking of Financial Terms
Jul 29, 2021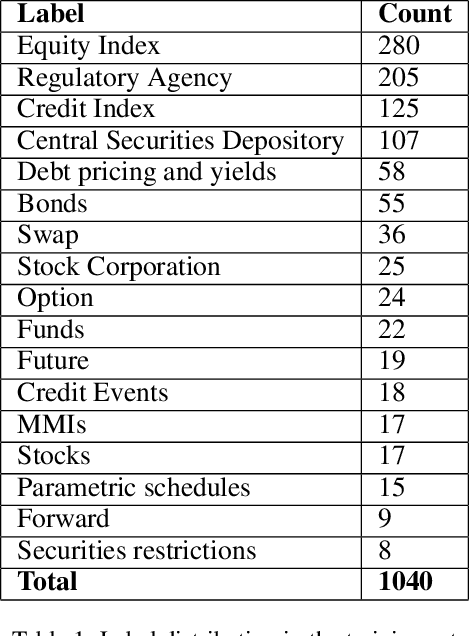

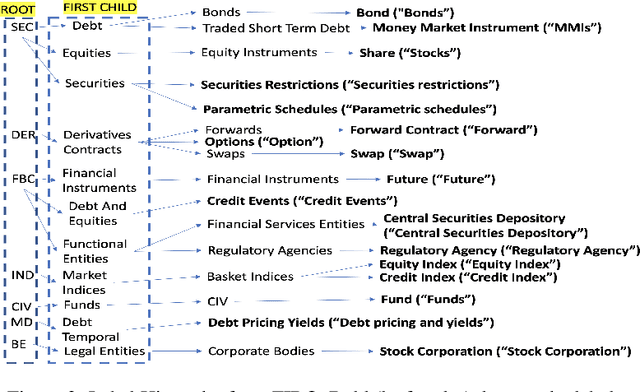
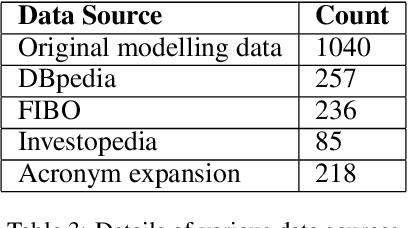
Hypernym and synonym matching are one of the mainstream Natural Language Processing (NLP) tasks. In this paper, we present systems that attempt to solve this problem. We designed these systems to participate in the FinSim-3, a shared task of FinNLP workshop at IJCAI-2021. The shared task is focused on solving this problem for the financial domain. We experimented with various transformer based pre-trained embeddings by fine-tuning these for either classification or phrase similarity tasks. We also augmented the provided dataset with abbreviations derived from prospectus provided by the organizers and definitions of the financial terms from DBpedia [Auer et al., 2007], Investopedia, and the Financial Industry Business Ontology (FIBO). Our best performing system uses both FinBERT [Araci, 2019] and data augmentation from the afore-mentioned sources. We observed that term expansion using data augmentation in conjunction with semantic similarity is beneficial for this task and could be useful for the other tasks that deal with short phrases. Our best performing model (Accuracy: 0.917, Rank: 1.156) was developed by fine-tuning SentenceBERT [Reimers et al., 2019] (with FinBERT at the backend) over an extended labelled set created using the hierarchy of labels present in FIBO.
Is it a click bait? Let's predict using Machine Learning
Jun 01, 2021

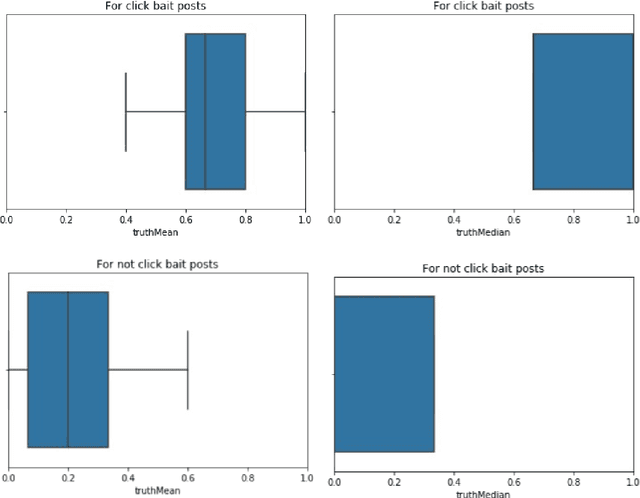
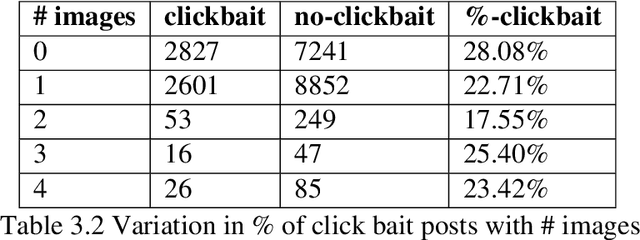
In this era of digitisation, news reader tend to read news online. This is because, online media instantly provides access to a wide variety of content. Thus, people don't have to wait for tomorrow's newspaper to know what's happening today. Along with these virtues, online news have some vices as well. One such vice is presence of social media posts (tweets) relating to news articles whose sole purpose is to draw attention of the users rather than directing them to read the actual content. Such posts are referred to as clickbaits. The objective of this project is to develop a system which would be capable of predicting how likely are the social media posts (tweets) relating to new articles tend to be clickbait.
Using Transformer based Ensemble Learning to classify Scientific Articles
Feb 19, 2021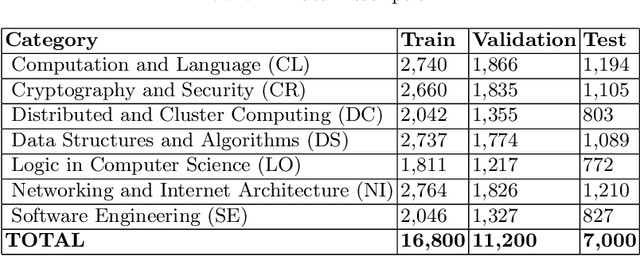
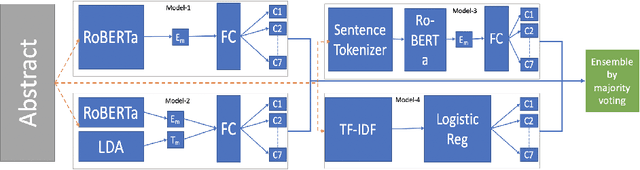
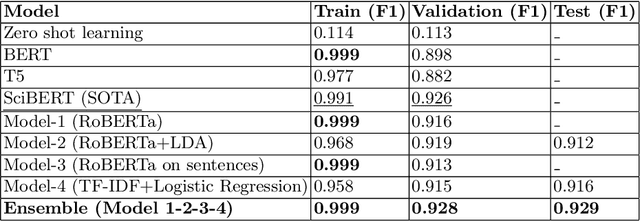
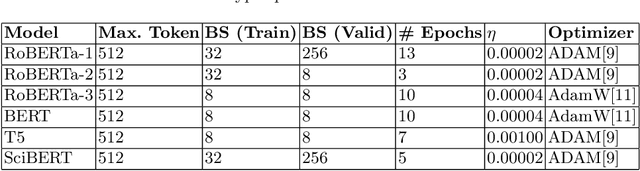
Many time reviewers fail to appreciate novel ideas of a researcher and provide generic feedback. Thus, proper assignment of reviewers based on their area of expertise is necessary. Moreover, reading each and every paper from end-to-end for assigning it to a reviewer is a tedious task. In this paper, we describe a system which our team FideLIPI submitted in the shared task of SDPRA-2021 [14]. It comprises four independent sub-systems capable of classifying abstracts of scientific literature to one of the given seven classes. The first one is a RoBERTa [10] based model built over these abstracts. Adding topic models / Latent dirichlet allocation (LDA) [2] based features to the first model results in the second sub-system. The third one is a sentence level RoBERTa [10] model. The fourth one is a Logistic Regression model built using Term Frequency Inverse Document Frequency (TF-IDF) features. We ensemble predictions of these four sub-systems using majority voting to develop the final system which gives a F1 score of 0.93 on the test and validation set. This outperforms the existing State Of The Art (SOTA) model SciBERT's [1] in terms of F1 score on the validation set.Our codebase is available at https://github.com/SDPRA-2021/shared-task/tree/main/FideLIPI