 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACTOID: FACtual enTailment fOr hallucInation Detection
Mar 28, 2024The widespread adoption of Large Language Models (LLMs) has facilitated numerous benefits. However, hallucination is a significant concern. In response, Retrieval Augmented Generation (RAG) has emerged as a highly promising paradigm to improve LLM outputs by grounding them in factual information. RAG relies on textual entailment (TE) or similar methods to check if the text produced by LLMs is supported or contradicted, compared to retrieved documents. This paper argues that conventional TE methods are inadequate for spotting hallucinations in content generated by LLMs. For instance, consider a prompt about the 'USA's stance on the Ukraine war''. The AI-generated text states, ...U.S. President Barack Obama says the U.S. will not put troops in Ukraine...'' However, during the war the U.S. president is Joe Biden which contradicts factual reality. Moreover, current TE systems are unable to accurately annotate the given text and identify the exact portion that is contradicted. To address this, we introduces a new type of TE called ``Factual Entailment (FE).'', aims to detect factual inaccuracies in content generated by LLMs while also highlighting the specific text segment that contradicts reality. We present FACTOID (FACTual enTAILment for hallucInation Detection), a benchmark dataset for FE. We propose a multi-task learning (MTL) framework for FE, incorporating state-of-the-art (SoTA) long text embeddings such as e5-mistral-7b-instruct, along with GPT-3, SpanBERT, and RoFormer. The proposed MTL architecture for FE achieves an avg. 40\% improvement in accuracy on the FACTOID benchmark compared to SoTA TE methods. As FE automatically detects hallucinations, we assessed 15 modern LLMs and ranked them using our proposed Auto Hallucination Vulnerability Index (HVI_auto). This index quantifies and offers a comparative scale to evaluate and rank LLMs according to their hallucinations.
"Sorry, Come Again?" Prompting -- Enhancing Comprehension and Diminishing Hallucination with [PAUSE]-injected Optimal Paraphrasing
Mar 27, 2024Hallucination has emerged as the most vulnerable aspect of contemporary Large Language Models (LLMs). In this paper, we introduce the Sorry, Come Again (SCA) prompting, aimed to avoid LLM hallucinations by enhancing comprehension through: (i) optimal paraphrasing and (ii) injecting [PAUSE] tokens to delay LLM generation. First, we provide an in-depth analysis of linguistic nuances: formality, readability, and concreteness of prompts for 21 LLMs, and elucidate how these nuances contribute to hallucinated generation. Prompts with lower readability, formality, or concreteness pose comprehension challenges for LLMs, similar to those faced by humans. In such scenarios, an LLM tends to speculate and generate content based on its imagination (associative memory) to fill these information gaps. Although these speculations may occasionally align with factual information, their accuracy is not assured, often resulting in hallucination. Recent studies reveal that an LLM often neglects the middle sections of extended prompts, a phenomenon termed as lost in the middle. While a specific paraphrase may suit one LLM, the same paraphrased version may elicit a different response from another LLM. Therefore, we propose an optimal paraphrasing technique to identify the most comprehensible paraphrase of a given prompt, evaluated using Integrated Gradient (and its variations) to guarantee that the LLM accurately processes all words. While reading lengthy sentences, humans often pause at various points to better comprehend the meaning read thus far. We have fine-tuned an LLM with injected [PAUSE] tokens, allowing the LLM to pause while reading lengthier prompts. This has brought several key contributions: (i) determining the optimal position to inject [PAUSE], (ii) determining the number of [PAUSE] tokens to be inserted, and (iii) introducing reverse proxy tuning to fine-tune the LLM for [PAUSE] insertion.
The What, Why, and How of Context Length Extension Techniques in Large Language Models -- A Detailed Survey
Jan 15, 2024The advent of Large Language Models (LLMs) represents a notable breakthrough in Natural Language Processing (NLP), contributing to substantial progress in both text comprehension and generation. However, amidst these advancements, it is noteworthy that LLMs often face a limitation in terms of context length extrapolation. Understanding and extending the context length for LLMs is crucial in enhancing their performance across various NLP applications. In this survey paper, we delve into the multifaceted aspects of exploring why it is essential, and the potential transformations that superior techniques could bring to NLP applications. We study the inherent challenges associated with extending context length and present an organized overview of the existing strategies employed by researchers. Additionally, we discuss the intricacies of evaluating context extension techniques and highlight the open challenges that researchers face in this domain. Furthermore, we explore whether there is a consensus within the research community regarding evaluation standards and identify areas where further agreement is needed. This comprehensive survey aims to serve as a valuable resource for researchers, guiding them through the nuances of context length extension techniques and fostering discussions on future advancements in this evolving field.
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
Jan 08, 2024As Large Language Models (LLMs) continue to advance in their ability to write human-like text, a key challenge remains around their tendency to hallucinate generating content that appears factual but is ungrounded. This issue of hallucination is arguably the biggest hindrance to safely deploying these powerful LLMs into real-world production systems that impact people's lives. The journey toward widespread adoption of LLMs in practical settings heavily relies on addressing and mitigating hallucinations. Unlike traditional AI systems focused on limited tasks, LLMs have been exposed to vast amounts of online text data during training. While this allows them to display impressive language fluency, it also means they are capable of extrapolating information from the biases in training data, misinterpreting ambiguous prompts, or modifying the information to align superficially with the input. This becomes hugely alarming when we rely on language generation capabilities for sensitive applications, such as summarizing medical records, financial analysis reports, etc. This paper presents a comprehensive survey of over 32 techniques developed to mitigate hallucination in LLMs. Notable among these are Retrieval Augmented Generation (Lewis et al, 2021), Knowledge Retrieval (Varshney et al,2023), CoNLI (Lei et al, 2023), and CoVe (Dhuliawala et al, 2023). Furthermore, we introduce a detailed taxonomy categorizing these methods based on various parameters, such as dataset utilization, common tasks, feedback mechanisms, and retriever types. This classification helps distinguish the diverse approaches specifically designed to tackle hallucination issues in LLMs. Additionally, we analyze the challenges and limitations inherent in these techniques, providing a solid foundation for future research in addressing hallucinations and related phenomena within the realm of LLMs.
Counter Turing Test CT^2: AI-Generated Text Detection is Not as Easy as You May Think -- Introducing AI Detectability Index
Oct 24, 2023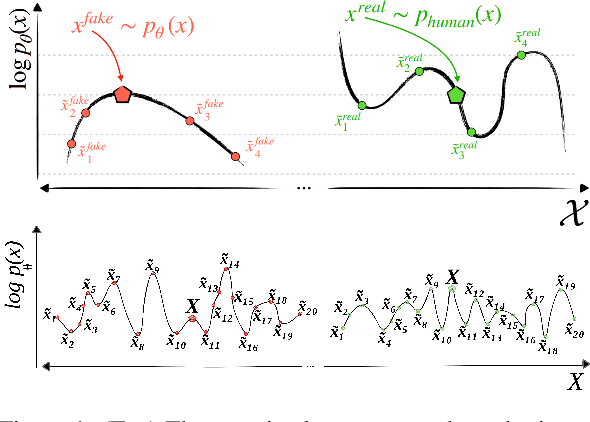



With the rise of prolific ChatGPT, the risk and consequences of AI-generated text has increased alarmingly. To address the inevitable question of ownership attribution for AI-generated artifacts, the US Copyright Office released a statement stating that 'If a work's traditional elements of authorship were produced by a machine, the work lacks human authorship and the Office will not register it'. Furthermore, both the US and the EU governments have recently drafted their initial proposals regarding the regulatory framework for AI. Given this cynosural spotlight on generative AI, AI-generated text detection (AGTD) has emerged as a topic that has already received immediate attention in research, with some initial methods having been proposed, soon followed by emergence of techniques to bypass detection. This paper introduces the Counter Turing Test (CT^2), a benchmark consisting of techniques aiming to offer a comprehensive evaluation of the robustness of existing AGTD techniques. Our empirical findings unequivocally highlight the fragility of the proposed AGTD methods under scrutiny. Amidst the extensive deliberations on policy-making for regulating AI development, it is of utmost importance to assess the detectability of content generated by LLMs. Thus, to establish a quantifiable spectrum facilitating the evaluation and ranking of LLMs according to their detectability levels, we propose the AI Detectability Index (ADI). We conduct a thorough examination of 15 contemporary LLMs, empirically demonstrating that larger LLMs tend to have a higher ADI, indicating they are less detectable compared to smaller LLMs. We firmly believe that ADI holds significant value as a tool for the wider NLP community, with the potential to serve as a rubric in AI-related policy-making.
The Troubling Emergence of Hallucination in Large Language Models -- An Extensive Definition, Quantification, and Prescriptive Remediations
Oct 08, 2023The recent advancements in Large Language Models (LLMs) have garnered widespread acclaim for their remarkable emerging capabilities. However, the issue of hallucination has parallelly emerged as a by-product, posing significant concerns. While some recent endeavors have been made to identify and mitigate different types of hallucination, there has been a limited emphasis on the nuanced categorization of hallucination and associated mitigation methods. To address this gap, we offer a fine-grained discourse on profiling hallucination based on its degree, orientation, and category, along with offering strategies for alleviation. As such, we define two overarching orientations of hallucination: (i) factual mirage (FM) and (ii) silver lining (SL). To provide a more comprehensive understanding, both orientations are further sub-categorized into intrinsic and extrinsic, with three degrees of severity - (i) mild, (ii) moderate, and (iii) alarming. We also meticulously categorize hallucination into six types: (i) acronym ambiguity, (ii) numeric nuisance, (iii) generated golem, (iv) virtual voice, (v) geographic erratum, and (vi) time wrap. Furthermore, we curate HallucInation eLiciTation (HILT), a publicly available dataset comprising of 75,000 samples generated using 15 contemporary LLMs along with human annotations for the aforementioned categories. Finally, to establish a method for quantifying and to offer a comparative spectrum that allows us to evaluate and rank LLMs based on their vulnerability to producing hallucinations, we propose Hallucination Vulnerability Index (HVI). We firmly believe that HVI holds significant value as a tool for the wider NLP community, with the potential to serve as a rubric in AI-related policy-making. In conclusion, we propose two solution strategies for mitigating hallucinations.
Exploring the Relationship between LLM Hallucinations and Prompt Linguistic Nuances: Readability, Formality, and Concreteness
Sep 20, 2023As Large Language Models (LLMs) have advanced, they have brought forth new challenges, with one of the prominent issues being LLM hallucination. While various mitigation techniques are emerging to address hallucination, it is equally crucial to delve into its underlying causes. Consequently, in this preliminary exploratory investigation, we examine how linguistic factors in prompts, specifically readability, formality, and concreteness, influence the occurrence of hallucinations. Our experimental results suggest that prompts characterized by greater formality and concreteness tend to result in reduced hallucination. However, the outcomes pertaining to readability are somewhat inconclusive, showing a mixed pattern.
FACTIFY-5WQA: 5W Aspect-based Fact Verification through Question Answering
May 07, 2023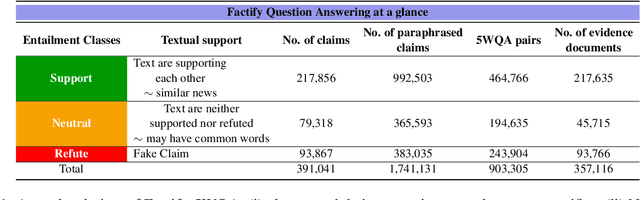
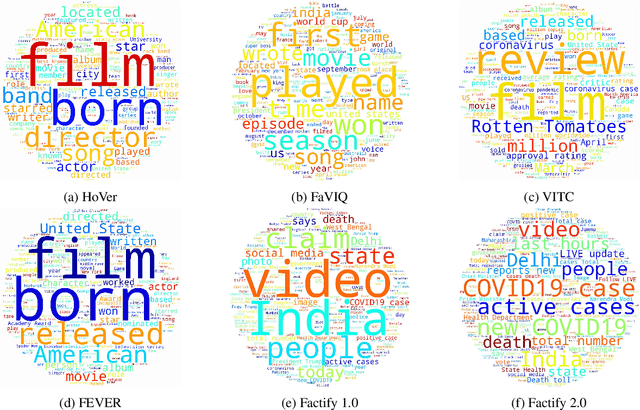

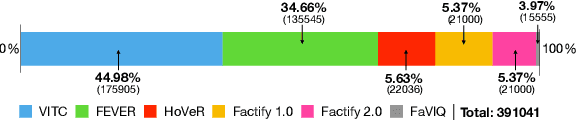
Automatic fact verification has received significant attention recently. Contemporary automatic fact-checking systems focus on estimating truthfulness using numerical scores which are not human-interpretable. A human fact-checker generally follows several logical steps to verify a verisimilitude claim and conclude whether it is truthful or a mere masquerade. Popular fact-checking websites follow a common structure for fact categorization such as half true, half false, false, pants on fire, etc. Therefore, it is necessary to have an aspect-based (which part is true and which part is false) explainable system that can assist human fact-checkers in asking relevant questions related to a fact, which can then be validated separately to reach a final verdict. In this paper, we propose a 5W framework (who, what, when, where, and why) for question-answer-based fact explainability. To that end, we have gathered a semi-automatically generated dataset called FACTIFY-5WQA, which consists of 395, 019 facts along with relevant 5W QAs underscoring our major contribution to this paper. A semantic role labeling system has been utilized to locate 5Ws, which generates QA pairs for claims using a masked language model. Finally, we report a baseline QA system to automatically locate those answers from evidence documents, which can be served as the baseline for future research in this field. Lastly, we propose a robust fact verification system that takes paraphrased claims and automatically validates them. The dataset and the baseline model are available at https://github.com/ankuranii/acl-5W-QA.
OOG- Optuna Optimized GAN Sampling Technique for Tabular Imbalanced Malware Data
Nov 25, 2022
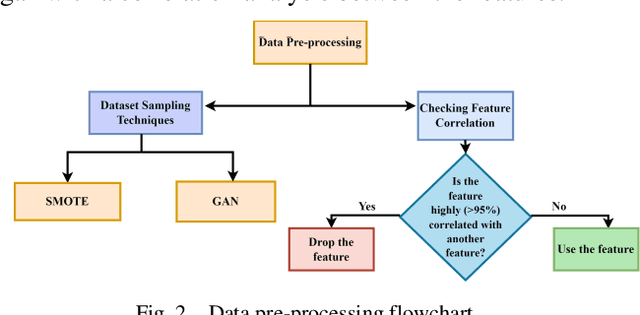
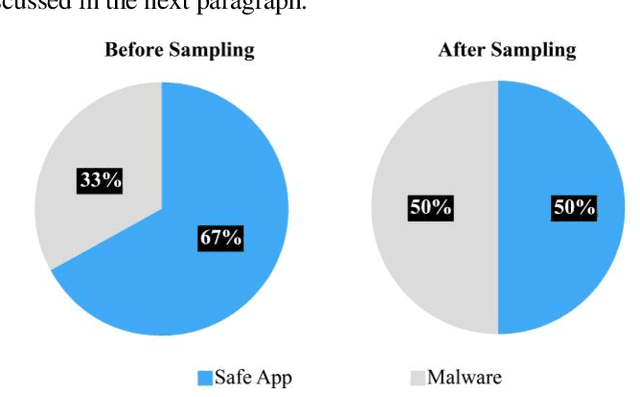
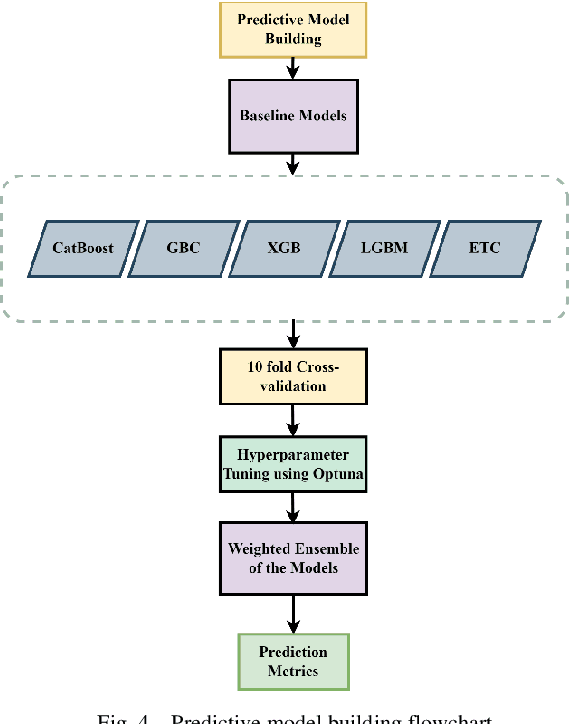
Cyberspace occupies a large portion of people's life in the age of modern technology, and while there are those who utilize it for good, there are also those who do not. Malware is an application whose construction was not motivated by a benign goal and it can harm, steal, or even alter personal information and secure applications and software. Thus, there are numerous techniques to avoid malware, one of which is to develop samples of malware so that the system can be updated with the growing number of malwares, allowing it to recognize when malwares attempt to enter. The Generative Adversarial Network (GAN) sampling technique has been used in this study to generate new malware samples. GANs have multiple variants, and in order to determine which variant is optimal for a given dataset sample, their parameters must be modified. This study employs Optuna, an autonomous hyperparameter tuning algorithm, to determine the optimal settings for the dataset under consideration. In this study, the architecture of the Optuna Optimized GAN (OOG) method is shown, along with scores of 98.06%, 99.00%, 97.23%, and 98.04% for accuracy, precision, recall and f1 score respectively. After tweaking the hyperparameters of five supervised boosting algorithms, XGBoost, LightGBM, CatBoost, Extra Trees Classifier, and Gradient Boosting Classifier, the methodology of this paper additionally employs the weighted ensemble technique to acquire this result. In addition to comparing existing efforts in this domain, the study demonstrates how promising GAN is in comparison to other sampling techniques such as SMOTE.