 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the Right Problem is Key for Translational NLP: A Case Study in UMLS Vocabulary Insertion
Nov 25, 2023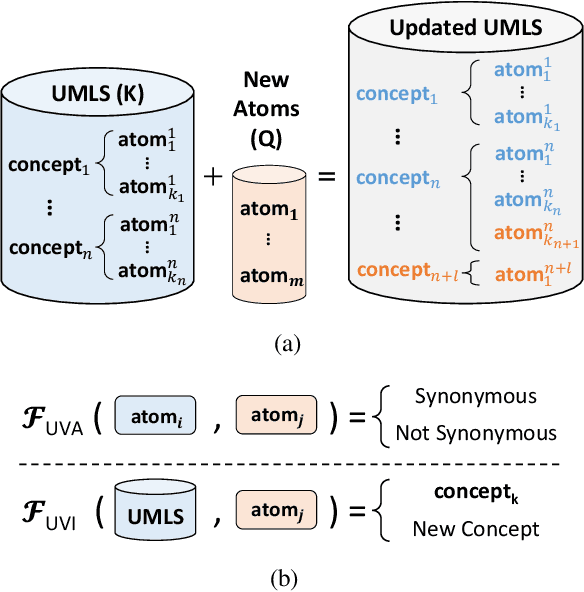
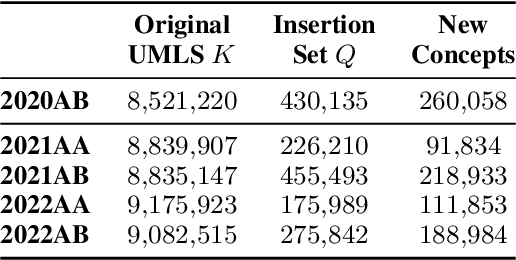
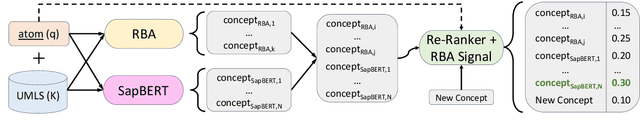

As the immense opportunities enabled by large language models become more apparent, NLP systems will be increasingly expected to excel in real-world settings. However, in many instances, powerful models alone will not yield translational NLP solutions, especially if the formulated problem is not well aligned with the real-world task. In this work, we study the case of UMLS vocabulary insertion, an important real-world task in which hundreds of thousands of new terms, referred to as atoms, are added to the UMLS, one of the most comprehensive open-source biomedical knowledge bases. Previous work aimed to develop an automated NLP system to make this time-consuming, costly, and error-prone task more efficient. Nevertheless, practical progress in this direction has been difficult to achieve due to a problem formulation and evaluation gap between research output and the real-world task. In order to address this gap, we introduce a new formulation for UMLS vocabulary insertion which mirrors the real-world task, datasets which faithfully represent it and several strong baselines we developed through re-purposing existing solutions. Additionally, we propose an effective rule-enhanced biomedical language model which enables important new model behavior, outperforms all strong baselines and provides measurable qualitative improvements to editors who carry out the UVI task. We hope this case study provides insight into the considerable importance of problem formulation for the success of translational NLP solutions.
UVA Resources for the Biomedical Vocabulary Alignment at Scale in the UMLS Metathesaurus
May 21, 2022



The construction and maintenance process of the UMLS (Unified Medical Language System) Metathesaurus is time-consuming, costly, and error-prone as it relies on (1) the lexical and semantic processing for suggesting synonymous terms, and (2) the expertise of UMLS editors for curating the suggestions. For improving the UMLS Metathesaurus construction process, our research group has defined a new task called UVA (UMLS Vocabulary Alignment) and generated a dataset for evaluating the task. Our group has also developed different baselines for this task using logical rules (RBA), and neural networks (LexLM and ConLM). In this paper, we present a set of reusable and reproducible resources including (1) a dataset generator, (2) three datasets generated by using the generator, and (3) three baseline approaches. We describe the UVA dataset generator and its implementation generalized for any given UMLS release. We demonstrate the use of the dataset generator by generating datasets corresponding to three UMLS releases, 2020AA, 2021AA, and 2021AB. We provide three UVA baselines using the three existing approaches (LexLM, ConLM, and RBA). The code, the datasets, and the experiments are publicly available, reusable, and reproducible with any UMLS release (a no-cost license agreement is required for downloading the UMLS).
UBERT: A Novel Language Model for Synonymy Prediction at Scale in the UMLS Metathesaurus
Apr 27, 2022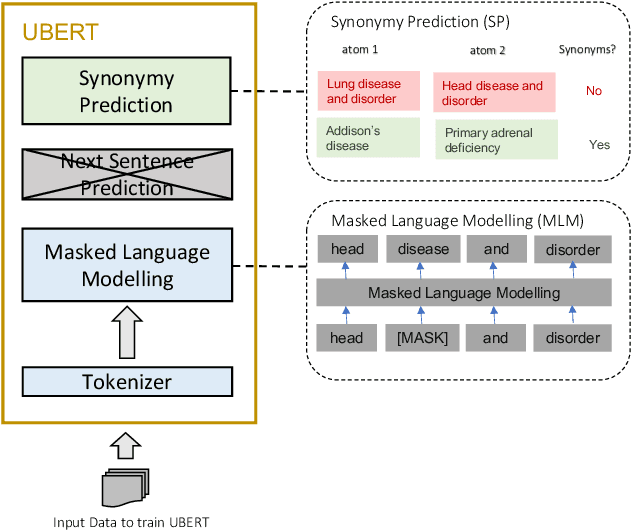
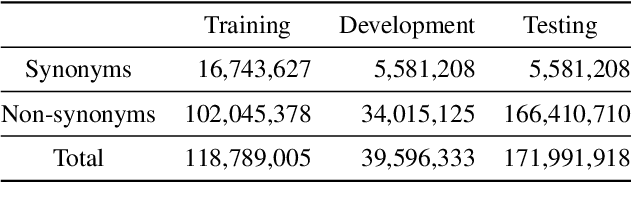
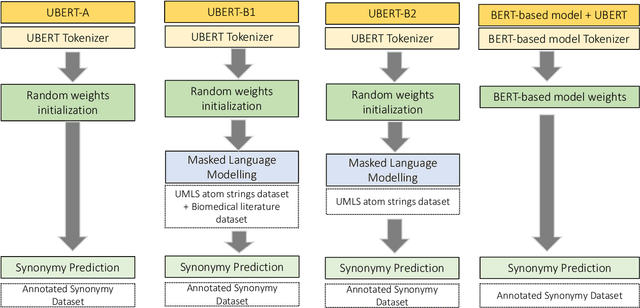

The UMLS Metathesaurus integrates more than 200 biomedical source vocabularies. During the Metathesaurus construction process, synonymous terms are clustered into concepts by human editors, assisted by lexical similarity algorithms. This process is error-prone and time-consuming. Recently, a deep learning model (LexLM) has been developed for the UMLS Vocabulary Alignment (UVA) task. This work introduces UBERT, a BERT-based language model, pretrained on UMLS terms via a supervised Synonymy Prediction (SP) task replacing the original Next Sentence Prediction (NSP) task. The effectiveness of UBERT for UMLS Metathesaurus construction process is evaluated using the UMLS Vocabulary Alignment (UVA) task. We show that UBERT outperforms the LexLM, as well as biomedical BERT-based models. Key to the performance of UBERT are the synonymy prediction task specifically developed for UBERT, the tight alignment of training data to the UVA task, and the similarity of the models used for pretrained UBERT.
Evaluating Biomedical BERT Models for Vocabulary Alignment at Scale in the UMLS Metathesaurus
Sep 14, 2021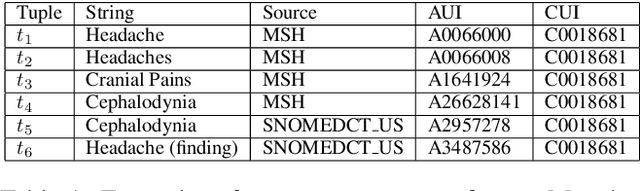
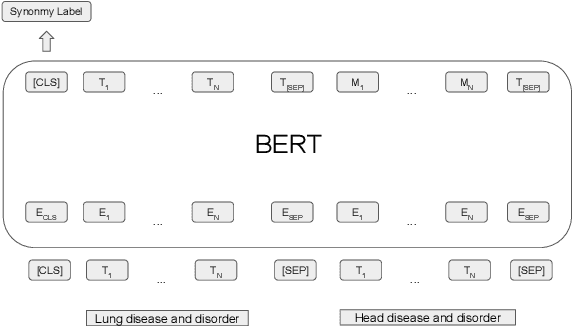

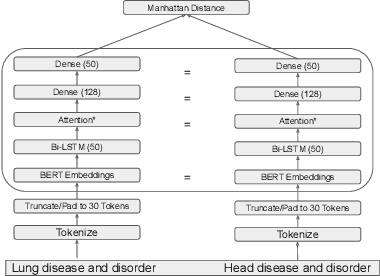
The current UMLS (Unified Medical Language System) Metathesaurus construction process for integrating over 200 biomedical source vocabularies is expensive and error-prone as it relies on the lexical algorithms and human editors for deciding if the two biomedical terms are synonymous. Recent advances in Natural Language Processing such as Transformer models like BERT and its biomedical variants with contextualized word embeddings have achieved state-of-the-art (SOTA) performance on downstream tasks. We aim to validate if these approaches using the BERT models can actually outperform the existing approaches for predicting synonymy in the UMLS Metathesaurus. In the existing Siamese Networks with LSTM and BioWordVec embeddings, we replace the BioWordVec embeddings with the biomedical BERT embeddings extracted from each BERT model using different ways of extraction. In the Transformer architecture, we evaluate the use of the different biomedical BERT models that have been pre-trained using different datasets and tasks. Given the SOTA performance of these BERT models for other downstream tasks, our experiments yield surprisingly interesting results: (1) in both model architectures, the approaches employing these biomedical BERT-based models do not outperform the existing approaches using Siamese Network with BioWordVec embeddings for the UMLS synonymy prediction task, (2) the original BioBERT large model that has not been pre-trained with the UMLS outperforms the SapBERT models that have been pre-trained with the UMLS, and (3) using the Siamese Networks yields better performance for synonymy prediction when compared to using the biomedical BERT models.
On Reasoning with RDF Statements about Statements using Singleton Property Triples
Sep 15, 2015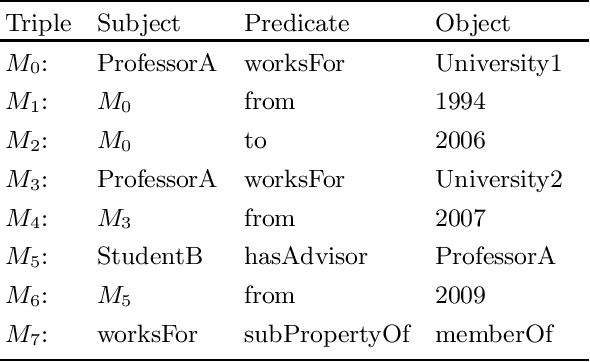

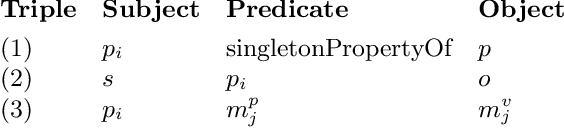
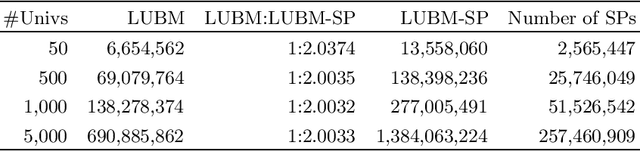
The Singleton Property (SP) approach has been proposed for representing and querying metadata about RDF triples such as provenance, time, location, and evidence. In this approach, one singleton property is created to uniquely represent a relationship in a particular context, and in general, generates a large property hierarchy in the schema. It has become the subject of important questions from Semantic Web practitioners. Can an existing reasoner recognize the singleton property triples? And how? If the singleton property triples describe a data triple, then how can a reasoner infer this data triple from the singleton property triples? Or would the large property hierarchy affect the reasoners in some way? We address these questions in this paper and present our study about the reasoning aspects of the singleton properties. We propose a simple mechanism to enable existing reasoners to recognize the singleton property triples, as well as to infer the data triples described by the singleton property triples. We evaluate the effect of the singleton property triples in the reasoning processes by comparing the performance on RDF datasets with and without singleton properties. Our evaluation uses as benchmark the LUBM datasets and the LUBM-SP datasets derived from LUBM with temporal information added through singleton properties.