 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidConv: A modernized 2D ConvNet for Efficient Video Recognition
Jul 08, 2022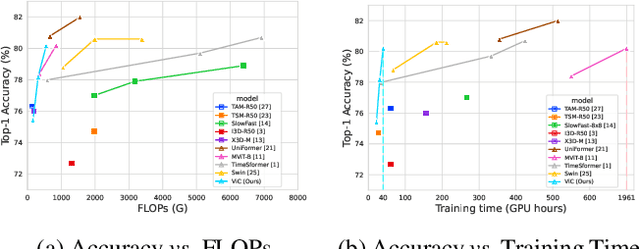
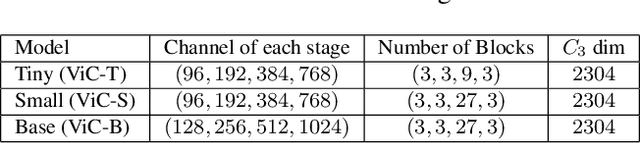
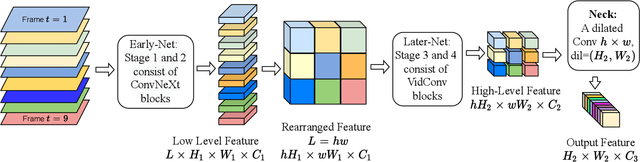
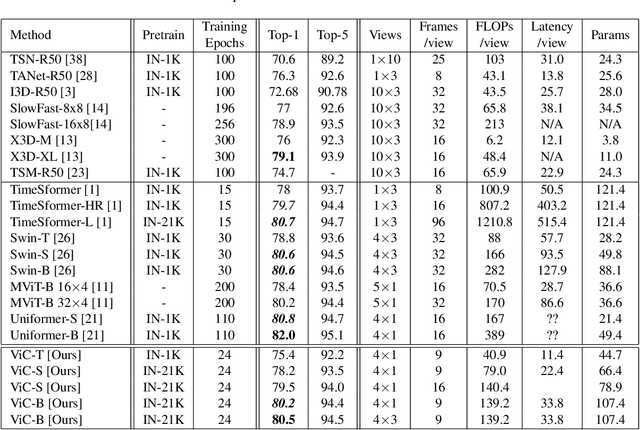
Since being introduced in 2020, Vision Transformers (ViT) has been steadily breaking the record for many vision tasks and are often described as ``all-you-need" to replace ConvNet. Despite that, ViTs are generally computational, memory-consuming, and unfriendly for embedded devices. In addition, recent research shows that standard ConvNet if redesigned and trained appropriately can compete favorably with ViT in terms of accuracy and scalability. In this paper, we adopt the modernized structure of ConvNet to design a new backbone for action recognition. Particularly, our main target is to serve for industrial product deployment, such as FPGA boards in which only standard operations are supported. Therefore, our network simply consists of 2D convolutions, without using any 3D convolution, long-range attention plugin, or Transformer blocks. While being trained with much fewer epochs (5x-10x), our backbone surpasses the methods using (2+1)D and 3D convolution, and achieve comparable results with ViT on two benchmark datasets.
Autonomous Navigation in Complex Environments with Deep Multimodal Fusion Network
Jul 31, 2020
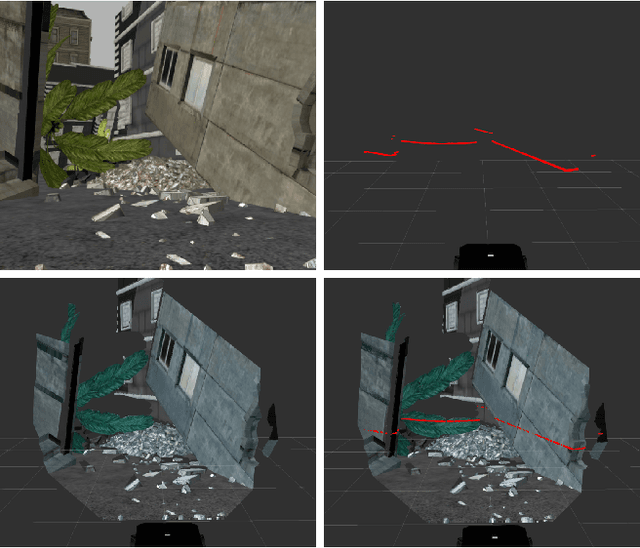
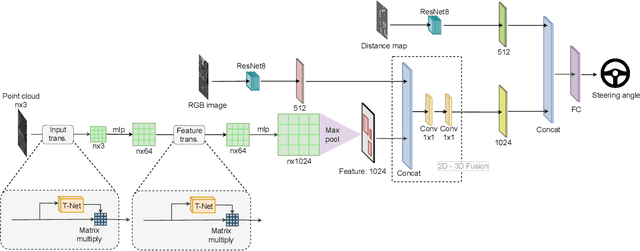
Autonomous navigation in complex environments is a crucial task in time-sensitive scenarios such as disaster response or search and rescue. However, complex environments pose significant challenges for autonomous platforms to navigate due to their challenging properties: constrained narrow passages, unstable pathway with debris and obstacles, or irregular geological structures and poor lighting conditions. In this work, we propose a multimodal fusion approach to address the problem of autonomous navigation in complex environments such as collapsed cites, or natural caves. We first simulate the complex environments in a physics-based simulation engine and collect a large-scale dataset for training. We then propose a Navigation Multimodal Fusion Network (NMFNet) which has three branches to effectively handle three visual modalities: laser, RGB images, and point cloud data. The extensively experimental results show that our NMFNet outperforms recent state of the art by a fair margin while achieving real-time performance. We further show that the use of multiple modalities is essential for autonomous navigation in complex environments. Finally, we successfully deploy our network to both simulated and real mobile robots.