 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Analysis of Deep Learning Workloads on a Composable System
Mar 19, 2021
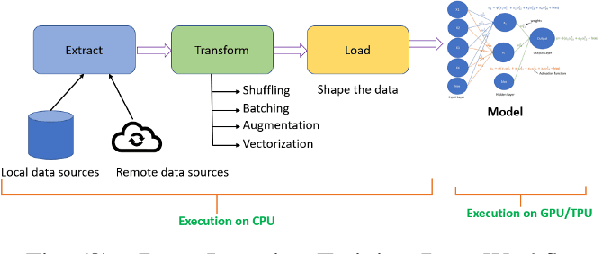

A composable infrastructure is defined as resources, such as compute, storage, accelerators and networking, that are shared in a pool and that can be grouped in various configurations to meet application requirements. This freedom to 'mix and match' resources dynamically allows for experimentation early in the design cycle, prior to the final architectural design or hardware implementation of a system. This design provides flexibility to serve a variety of workloads and provides a dynamic co-design platform that allows experiments and measurements in a controlled manner. For instance, key performance bottlenecks can be revealed early on in the experimentation phase thus avoiding costly and time consuming mistakes. Additionally, various system-level topologies can be evaluated when experimenting with new System on Chip (SoCs) and new accelerator types. This paper details the design of an enterprise composable infrastructure that we have implemented and made available to our partners in the IBM Research AI Hardware Center (AIHC). Our experimental evaluations on the composable system give insights into how the system works and evaluates the impact of various resource aggregations and reconfigurations on representative deep learning benchmarks.
Autonomous Navigation in Complex Environments with Deep Multimodal Fusion Network
Jul 31, 2020
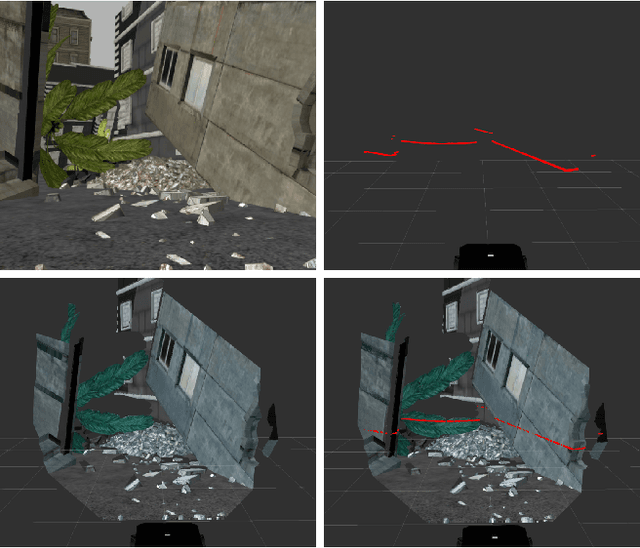
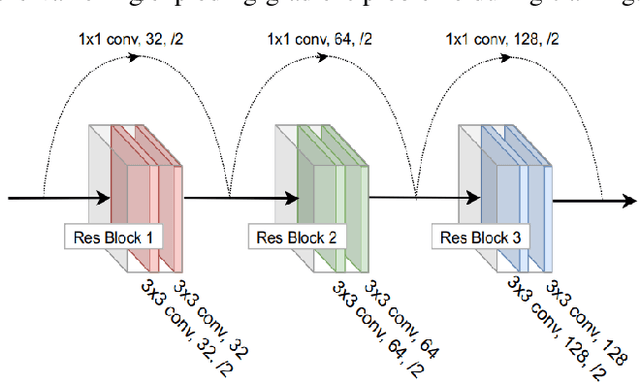
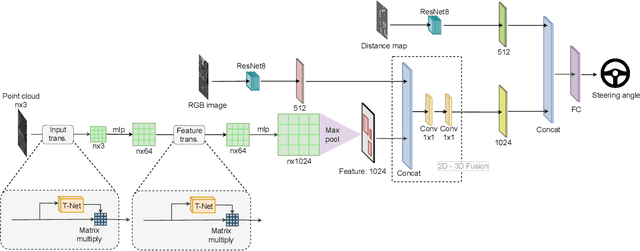
Autonomous navigation in complex environments is a crucial task in time-sensitive scenarios such as disaster response or search and rescue. However, complex environments pose significant challenges for autonomous platforms to navigate due to their challenging properties: constrained narrow passages, unstable pathway with debris and obstacles, or irregular geological structures and poor lighting conditions. In this work, we propose a multimodal fusion approach to address the problem of autonomous navigation in complex environments such as collapsed cites, or natural caves. We first simulate the complex environments in a physics-based simulation engine and collect a large-scale dataset for training. We then propose a Navigation Multimodal Fusion Network (NMFNet) which has three branches to effectively handle three visual modalities: laser, RGB images, and point cloud data. The extensively experimental results show that our NMFNet outperforms recent state of the art by a fair margin while achieving real-time performance. We further show that the use of multiple modalities is essential for autonomous navigation in complex environments. Finally, we successfully deploy our network to both simulated and real mobile robots.