 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot VLM-Based G-Code and HMI Verification in CNC Machining
Dec 12, 2025Manual generation of G-code is important for learning the operation of CNC machines. Prior work in G-code verification uses Large-Language Models (LLMs), which primarily examine errors in the written programming. However, CNC machining requires extensive use and knowledge of the Human-Machine Interface (HMI), which displays machine status and errors. LLMs currently lack the capability to leverage knowledge of HMIs due to their inability to access the vision modality. This paper proposes a few-shot VLM-based verification approach that simultaneously evaluates the G-code and the HMI display for errors and safety status. The input dataset includes paired G-code text and associated HMI screenshots from a 15-slant-PRO lathe, including both correct and error-prone cases. To enable few-shot learning, the VLM is provided with a structured JSON schema based on prior heuristic knowledge. After determining the prompts, instances of G-code and HMI that either contain errors or are error free are used as few-shot examples to guide the VLM. The model was then evaluated in comparison to a zero-shot VLM through multiple scenarios of incorrect G-code and HMI errors with respect to per-slot accuracy. The VLM showed that few-shot prompting led to overall enhancement of detecting HMI errors and discrepancies with the G-code for more comprehensive debugging. Therefore, the proposed framework was demonstrated to be suitable for verification of manually generated G-code that is typically developed in CNC training.
Vision-Language Models for Infrared Industrial Sensing in Additive Manufacturing Scene Description
Dec 11, 2025Many manufacturing environments operate in low-light conditions or within enclosed machines where conventional vision systems struggle. Infrared cameras provide complementary advantages in such environments. Simultaneously, supervised AI systems require large labeled datasets, which makes zero-shot learning frameworks more practical for applications including infrared cameras. Recent advances in vision-language foundation models (VLMs) offer a new path in zero-shot predictions from paired image-text representations. However, current VLMs cannot understand infrared camera data since they are trained on RGB data. This work introduces VLM-IRIS (Vision-Language Models for InfraRed Industrial Sensing), a zero-shot framework that adapts VLMs to infrared data by preprocessing infrared images captured by a FLIR Boson sensor into RGB-compatible inputs suitable for CLIP-based encoders. We demonstrate zero-shot workpiece presence detection on a 3D printer bed where temperature differences between the build plate and workpieces make the task well-suited for thermal imaging. VLM-IRIS converts the infrared images to magma representation and applies centroid prompt ensembling with a CLIP ViT-B/32 encoder to achieve high accuracy on infrared images without any model retraining. These findings demonstrate that the proposed improvements to VLMs can be effectively extended to thermal applications for label-free monitoring.
Multimodal Object Detection using Depth and Image Data for Manufacturing Parts
Nov 13, 2024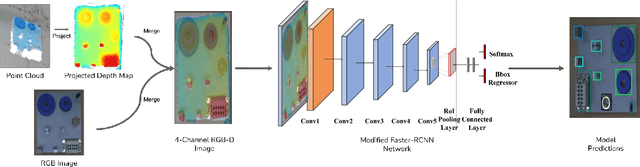
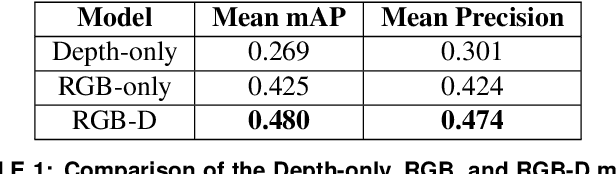
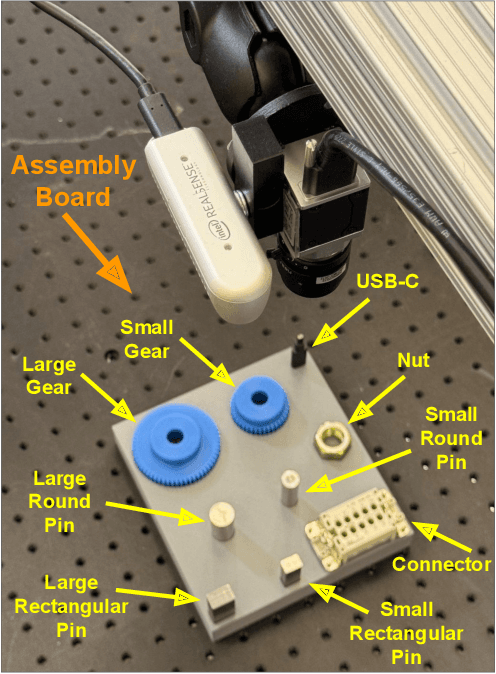

Manufacturing requires reliable object detection methods for precise picking and handling of diverse types of manufacturing parts and components. Traditional object detection methods utilize either only 2D images from cameras or 3D data from lidars or similar 3D sensors. However, each of these sensors have weaknesses and limitations. Cameras do not have depth perception and 3D sensors typically do not carry color information. These weaknesses can undermine the reliability and robustness of industrial manufacturing systems. To address these challenges, this work proposes a multi-sensor system combining an red-green-blue (RGB) camera and a 3D point cloud sensor. The two sensors are calibrated for precise alignment of the multimodal data captured from the two hardware devices. A novel multimodal object detection method is developed to process both RGB and depth data. This object detector is based on the Faster R-CNN baseline that was originally designed to process only camera images. The results show that the multimodal model significantly outperforms the depth-only and RGB-only baselines on established object detection metrics. More specifically, the multimodal model improves mAP by 13% and raises Mean Precision by 11.8% in comparison to the RGB-only baseline. Compared to the depth-only baseline, it improves mAP by 78% and raises Mean Precision by 57%. Hence, this method facilitates more reliable and robust object detection in service to smart manufacturing applications.
Hierarchical SegNet with Channel and Context Attention for Accurate Lung Segmentation in Chest X-ray Images
May 20, 2024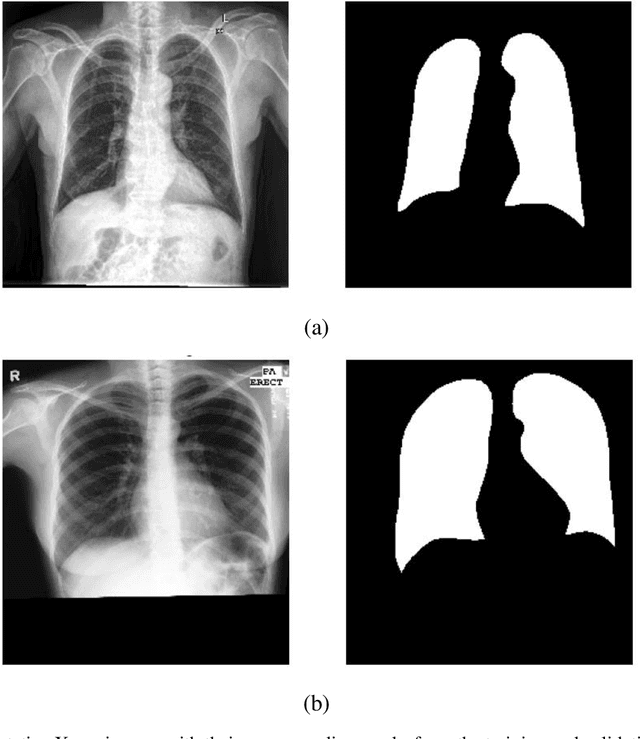
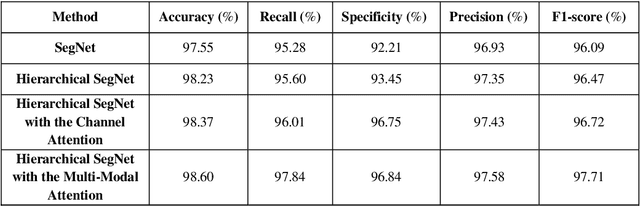
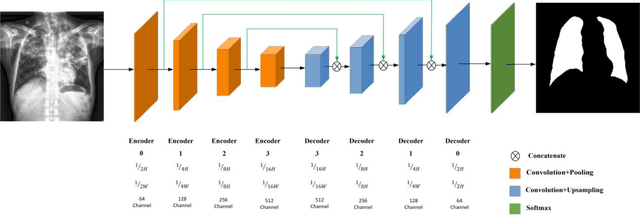
Lung segmentation in chest X-ray images is a critical task in medical image analysis, enabling accurate diagnosis and treatment of various lung diseases. In this paper, we propose a novel approach for lung segmentation by integrating Hierarchical SegNet with a proposed multi-modal attention mechanism. The channel attention mechanism highlights specific feature maps or channels crucial for lung region segmentation, while the context attention mechanism adaptively weighs the importance of different spatial regions. By combining both mechanisms, the proposed mechanism enables the model to better capture complex patterns and relationships between various features, leading to improved segmentation accuracy and better feature representation. Furthermore, an attention gating mechanism is employed to integrate attention information with encoder features, allowing the model to adaptively weigh the importance of different attention features and ignore irrelevant ones. Experimental results demonstrate that our proposed approach achieves state-of-the-art performance in lung segmentation tasks, outperforming existing methods. The proposed approach has the potential to improve the accuracy and efficiency of lung disease diagnosis and treatment, and can be extended to other medical image analysis tasks.