 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Advanced NLP Framework for Automated Medical Diagnosis with DeBERTa and Dynamic Contextual Positional Gating
Feb 11, 2025



This paper presents a novel Natural Language Processing (NLP) framework for enhancing medical diagnosis through the integration of advanced techniques in data augmentation, feature extraction, and classification. The proposed approach employs back-translation to generate diverse paraphrased datasets, improving robustness and mitigating overfitting in classification tasks. Leveraging Decoding-enhanced BERT with Disentangled Attention (DeBERTa) with Dynamic Contextual Positional Gating (DCPG), the model captures fine-grained contextual and positional relationships, dynamically adjusting the influence of positional information based on semantic context to produce high-quality text embeddings. For classification, an Attention-Based Feedforward Neural Network (ABFNN) is utilized, effectively focusing on the most relevant features to improve decision-making accuracy. Applied to the classification of symptoms, clinical notes, and other medical texts, this architecture demonstrates its ability to address the complexities of medical data. The combination of data augmentation, contextual embedding generation, and advanced classification mechanisms offers a robust and accurate diagnostic tool, with potential applications in automated medical diagnosis and clinical decision support. This method demonstrates the effectiveness of the proposed NLP framework for medical diagnosis, achieving remarkable results with an accuracy of 99.78%, recall of 99.72%, precision of 99.79%, and an F1-score of 99.75%. These metrics not only underscore the model's robust performance in classifying medical texts with exceptional precision and reliability but also highlight its superiority over existing methods, making it a highly promising tool for automated diagnostic systems.
Transformer-Based Bearing Fault Detection using Temporal Decomposition Attention Mechanism
Dec 15, 2024Bearing fault detection is a critical task in predictive maintenance, where accurate and timely fault identification can prevent costly downtime and equipment damage. Traditional attention mechanisms in Transformer neural networks often struggle to capture the complex temporal patterns in bearing vibration data, leading to suboptimal performance. To address this limitation, we propose a novel attention mechanism, Temporal Decomposition Attention (TDA), which combines temporal bias encoding with seasonal-trend decomposition to capture both long-term dependencies and periodic fluctuations in time series data. Additionally, we incorporate the Hull Exponential Moving Average (HEMA) for feature extraction, enabling the model to effectively capture meaningful characteristics from the data while reducing noise. Our approach integrates TDA into the Transformer architecture, allowing the model to focus separately on the trend and seasonal components of the data. Experimental results on the Case Western Reserve University (CWRU) bearing fault detection dataset demonstrate that our approach outperforms traditional attention mechanisms and achieves state-of-the-art performance in terms of accuracy and interpretability. The HEMA-Transformer-TDA model achieves an accuracy of 98.1%, with exceptional precision, recall, and F1-scores, demonstrating its effectiveness in bearing fault detection and its potential for application in other time series tasks with seasonal patterns or trends.
Stock Price Prediction using Multi-Faceted Information based on Deep Recurrent Neural Networks
Nov 29, 2024


Accurate prediction of stock market trends is crucial for informed investment decisions and effective portfolio management, ultimately leading to enhanced wealth creation and risk mitigation. This study proposes a novel approach for predicting stock prices in the stock market by integrating Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) networks, using sentiment analysis of social network data and candlestick data (price). The proposed methodology consists of two primary components: sentiment analysis of social network and candlestick data. By amalgamating candlestick data with insights gleaned from Twitter, this approach facilitates a more detailed and accurate examination of market trends and patterns, ultimately leading to more effective stock price predictions. Additionally, a Random Forest algorithm is used to classify tweets as either positive or negative, allowing for a more subtle and informed assessment of market sentiment. This study uses CNN and LSTM networks to predict stock prices. The CNN extracts short-term features, while the LSTM models long-term dependencies. The integration of both networks enables a more comprehensive analysis of market trends and patterns, leading to more accurate stock price predictions.
Forecasting Foreign Exchange Market Prices Using Technical Indicators with Deep Learning and Attention Mechanism
Nov 29, 2024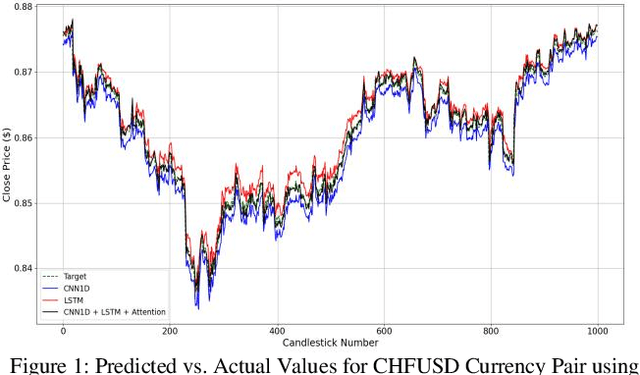
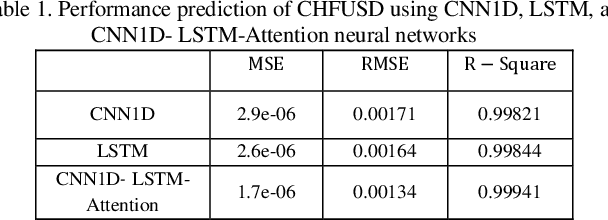
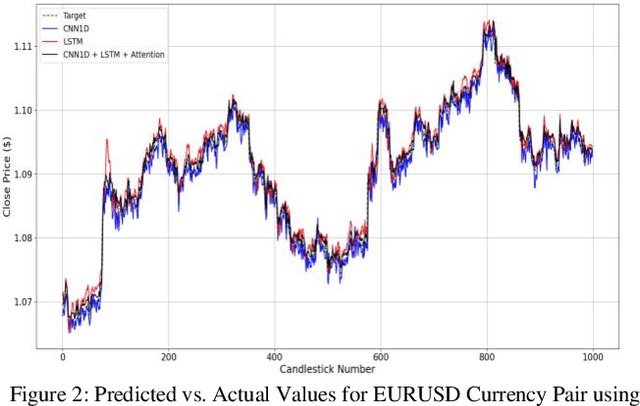
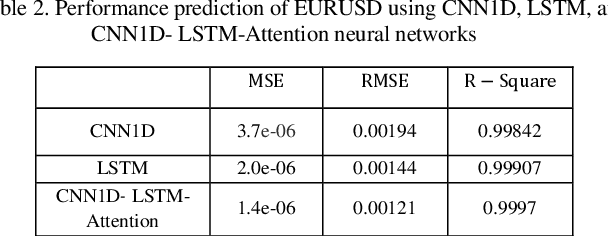
Accurate prediction of price behavior in the foreign exchange market is crucial. This paper proposes a novel approach that leverages technical indicators and deep neural networks. The proposed architecture consists of a Long Short-Term Memory (LSTM) and Convolutional Neural Network (CNN), and attention mechanism. Initially, trend and oscillation technical indicators are employed to extract statistical features from Forex currency pair data, providing insights into price trends, market volatility, relative price strength, and overbought and oversold conditions. Subsequently, the LSTM and CNN networks are utilized in parallel to predict future price movements, leveraging the strengths of both recurrent and convolutional architectures. The LSTM network captures long-term dependencies and temporal patterns in the data, while the CNN network extracts local patterns. The outputs of the parallel LSTM and CNN networks are then fed into an attention mechanism, which learns to weigh the importance of each feature and temporal dependency, generating a context-aware representation of the input data. The attention-weighted output is then used to predict future price movements, enabling the model to focus on the most relevant features and temporal dependencies. Through a comprehensive evaluation of the proposed approach on multiple Forex currency pairs, we demonstrate its effectiveness in predicting price behavior and outperforming benchmark models.
Enhanced Fault Detection and Cause Identification Using Integrated Attention Mechanism
Jul 31, 2024



This study introduces a novel methodology for fault detection and cause identification within the Tennessee Eastman Process (TEP) by integrating a Bidirectional Long Short-Term Memory (BiLSTM) neural network with an Integrated Attention Mechanism (IAM). The IAM combines the strengths of scaled dot product attention, residual attention, and dynamic attention to capture intricate patterns and dependencies crucial for TEP fault detection. Initially, the attention mechanism extracts important features from the input data, enhancing the model's interpretability and relevance. The BiLSTM network processes these features bidirectionally to capture long-range dependencies, and the IAM further refines the output, leading to improved fault detection results. Simulation results demonstrate the efficacy of this approach, showcasing superior performance in accuracy, false alarm rate, and misclassification rate compared to existing methods. This methodology provides a robust and interpretable solution for fault detection and diagnosis in the TEP, highlighting its potential for industrial applications.
Brain Tumor Classification using Vision Transformer with Selective Cross-Attention Mechanism and Feature Calibration
Jun 25, 2024
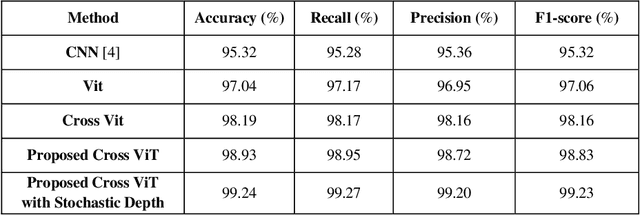
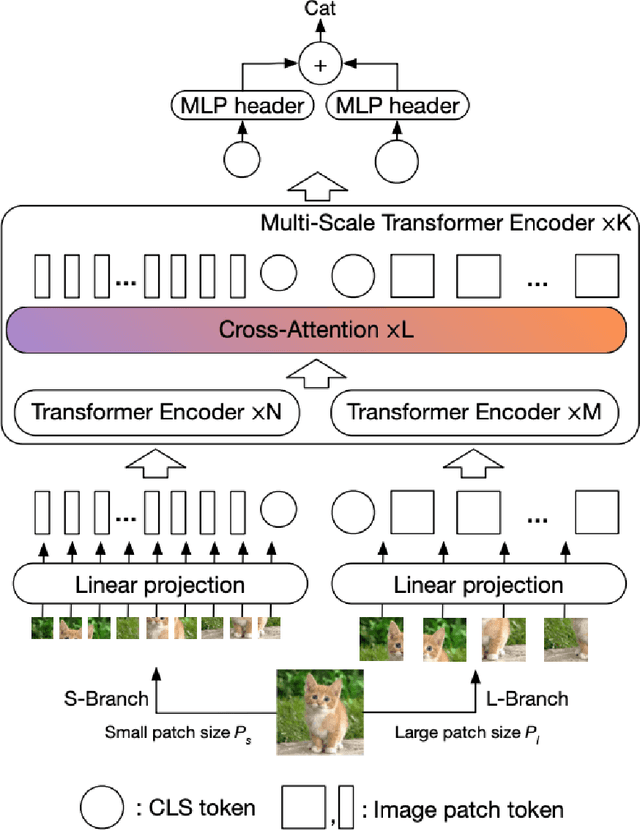
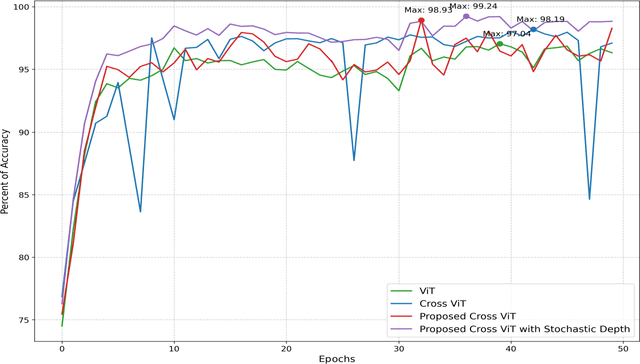
Brain tumor classification is a challenging task in medical image analysis. In this paper, we propose a novel approach to brain tumor classification using a vision transformer with a novel cross-attention mechanism. Our approach leverages the strengths of transformers in modeling long-range dependencies and multi-scale feature fusion. We introduce two new mechanisms to improve the performance of the cross-attention fusion module: Feature Calibration Mechanism (FCM) and Selective Cross-Attention (SCA). FCM calibrates the features from different branches to make them more compatible, while SCA selectively attends to the most informative features. Our experiments demonstrate that the proposed approach outperforms other state-of-the-art methods in brain tumor classification, achieving improved accuracy and efficiency. The proposed FCM and SCA mechanisms can be easily integrated into other vision transformer architectures, making them a promising direction for future research in medical image analysis. Experimental results confirm that our approach surpasses existing methods, achieving state-of-the-art performance in brain tumor classification tasks.
Hierarchical SegNet with Channel and Context Attention for Accurate Lung Segmentation in Chest X-ray Images
May 20, 2024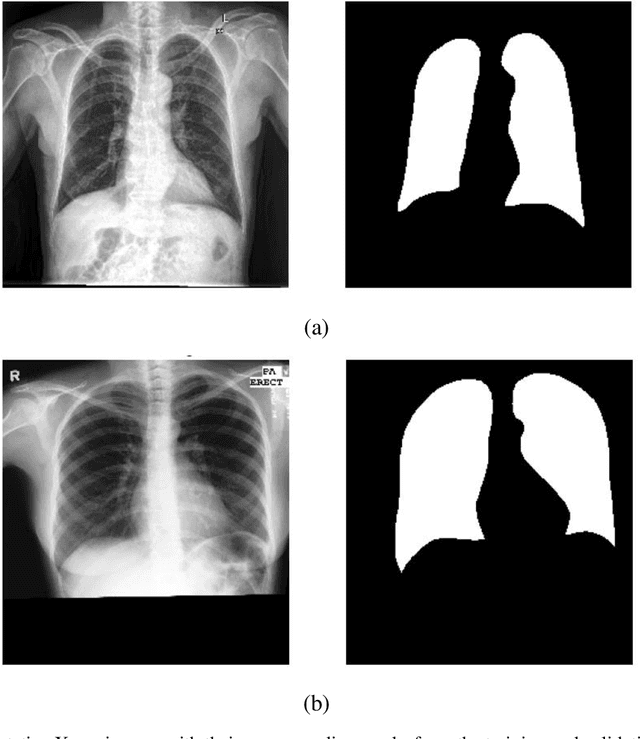
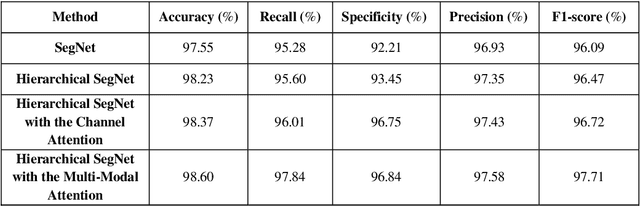
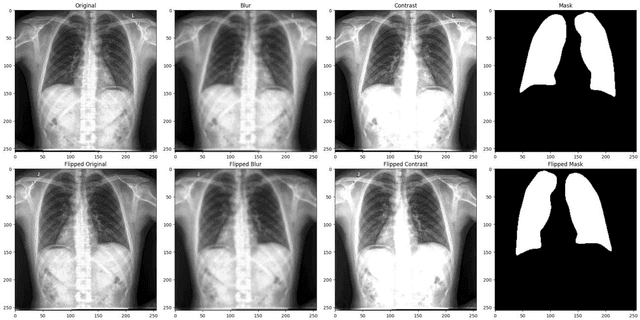
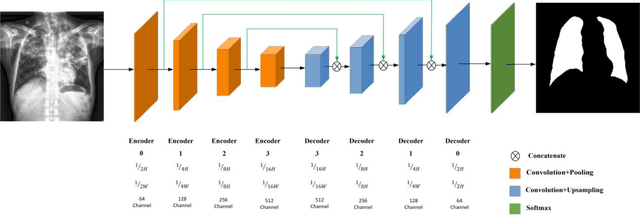
Lung segmentation in chest X-ray images is a critical task in medical image analysis, enabling accurate diagnosis and treatment of various lung diseases. In this paper, we propose a novel approach for lung segmentation by integrating Hierarchical SegNet with a proposed multi-modal attention mechanism. The channel attention mechanism highlights specific feature maps or channels crucial for lung region segmentation, while the context attention mechanism adaptively weighs the importance of different spatial regions. By combining both mechanisms, the proposed mechanism enables the model to better capture complex patterns and relationships between various features, leading to improved segmentation accuracy and better feature representation. Furthermore, an attention gating mechanism is employed to integrate attention information with encoder features, allowing the model to adaptively weigh the importance of different attention features and ignore irrelevant ones. Experimental results demonstrate that our proposed approach achieves state-of-the-art performance in lung segmentation tasks, outperforming existing methods. The proposed approach has the potential to improve the accuracy and efficiency of lung disease diagnosis and treatment, and can be extended to other medical image analysis tasks.
A Novel Approach to Chest X-ray Lung Segmentation Using U-net and Modified Convolutional Block Attention Module
Apr 22, 2024Lung segmentation in chest X-ray images is of paramount importance as it plays a crucial role in the diagnosis and treatment of various lung diseases. This paper presents a novel approach for lung segmentation in chest X-ray images by integrating U-net with attention mechanisms. The proposed method enhances the U-net architecture by incorporating a Convolutional Block Attention Module (CBAM), which unifies three distinct attention mechanisms: channel attention, spatial attention, and pixel attention. The channel attention mechanism enables the model to concentrate on the most informative features across various channels. The spatial attention mechanism enhances the model's precision in localization by focusing on significant spatial locations. Lastly, the pixel attention mechanism empowers the model to focus on individual pixels, further refining the model's focus and thereby improving the accuracy of segmentation. The adoption of the proposed CBAM in conjunction with the U-net architecture marks a significant advancement in the field of medical imaging, with potential implications for improving diagnostic precision and patient outcomes. The efficacy of this method is validated against contemporary state-of-the-art techniques, showcasing its superiority in segmentation performance.
Twin Transformer using Gated Dynamic Learnable Attention mechanism for Fault Detection and Diagnosis in the Tennessee Eastman Process
Mar 16, 2024Fault detection and diagnosis (FDD) is a crucial task for ensuring the safety and efficiency of industrial processes. We propose a novel FDD methodology for the Tennessee Eastman Process (TEP), a widely used benchmark for chemical process control. The model employs two separate Transformer branches, enabling independent processing of input data and potential extraction of diverse information. A novel attention mechanism, Gated Dynamic Learnable Attention (GDLAttention), is introduced which integrates a gating mechanism and dynamic learning capabilities. The gating mechanism modulates the attention weights, allowing the model to focus on the most relevant parts of the input. The dynamic learning approach adapts the attention strategy during training, potentially leading to improved performance. The attention mechanism uses a bilinear similarity function, providing greater flexibility in capturing complex relationships between query and key vectors. In order to assess the effectiveness of our approach, we tested it against 21 and 18 distinct fault scenarios in TEP, and compared its performance with several established FDD techniques. The outcomes indicate that the method outperforms others in terms of accuracy, false alarm rate, and misclassification rate. This underscores the robustness and efficacy of the approach for FDD in intricate industrial processes.
Enhancing Price Prediction in Cryptocurrency Using Transformer Neural Network and Technical Indicators
Mar 06, 2024This study presents an innovative approach for predicting cryptocurrency time series, specifically focusing on Bitcoin, Ethereum, and Litecoin. The methodology integrates the use of technical indicators, a Performer neural network, and BiLSTM (Bidirectional Long Short-Term Memory) to capture temporal dynamics and extract significant features from raw cryptocurrency data. The application of technical indicators, such facilitates the extraction of intricate patterns, momentum, volatility, and trends. The Performer neural network, employing Fast Attention Via positive Orthogonal Random features (FAVOR+), has demonstrated superior computational efficiency and scalability compared to the traditional Multi-head attention mechanism in Transformer models. Additionally, the integration of BiLSTM in the feedforward network enhances the model's capacity to capture temporal dynamics in the data, processing it in both forward and backward directions. This is particularly advantageous for time series data where past and future data points can influence the current state. The proposed method has been applied to the hourly and daily timeframes of the major cryptocurrencies and its performance has been benchmarked against other methods documented in the literature. The results underscore the potential of the proposed method to outperform existing models, marking a significant progression in the field of cryptocurrency price prediction.