 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspectiveNet: Multi-View Perception for Dynamic Scene Understanding
Paper and Code
Oct 22, 2024
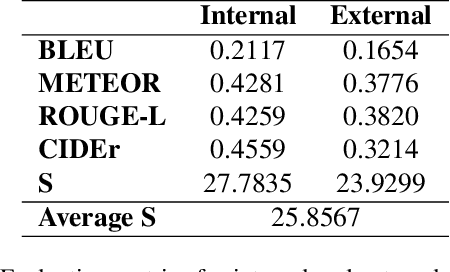


Generating detailed descriptions from multiple cameras and viewpoints is challenging due to the complex and inconsistent nature of visual data. In this paper, we introduce PerspectiveNet, a lightweight yet efficient model for generating long descriptions across multiple camera views. Our approach utilizes a vision encoder, a compact connector module to convert visual features into a fixed-size tensor, and large language models (LLMs) to harness the strong natural language generation capabilities of LLMs. The connector module is designed with three main goals: mapping visual features onto LLM embeddings, emphasizing key information needed for description generation, and producing a fixed-size feature matrix. Additionally, we augment our solution with a secondary task, the correct frame sequence detection, enabling the model to search for the correct sequence of frames to generate descriptions. Finally, we integrate the connector module, the secondary task, the LLM, and a visual feature extraction model into a single architecture, which is trained for the Traffic Safety Description and Analysis task. This task requires generating detailed, fine-grained descriptions of events from multiple cameras and viewpoints. The resulting model is lightweight, ensuring efficient training and inference, while remaining highly effective.