 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity Considerations for Multi-agent Systems
Mar 09, 2026Multi-agent artificial intelligence systems or MAS are systems of autonomous agents that exercise delegated tool authority, share persistent memory, and coordinate via inter-agent communication. MAS introduces qualitatively distinct security vulnerabilities from those documented for singular AI models. Existing security and governance frameworks were not designed for these emerging attack surfaces. This study systematically characterizes the threat landscape of MAS and quantitatively evaluates 16 security frameworks for AI against it. A four-phase methodology is proposed: constructing a deep technical knowledge base of production multi-agent architectures; conducting generative AI-assisted threat modeling scoped to MAS cybersecurity risks and validated by domain experts; structuring survey plans at individual-threat granularity; and scoring each framework on a three-point scale against the cybersecurity risks. The risks were organized into 193 distinct main threat items across nine risk categories. The expected minimal average score is 2. No reviewed framework achieves majority coverage of any single category. Non-Determinism (mean score 1.231 across all 16 frameworks) and Data Leakage (1.340) are the most under-addressed domains. The OWASP Agentic Security Initiative leads overall at 65.3\% coverage and in the design phase; the CDAO Generative AI Responsible AI Toolkit leads in development and operational coverage. These results provide the first empirical cross-framework comparison for MAS security and offer evidence-based guidance for framework selection.
OpenRoboCare: A Multimodal Multi-Task Expert Demonstration Dataset for Robot Caregiving
Nov 17, 2025We present OpenRoboCare, a multimodal dataset for robot caregiving, capturing expert occupational therapist demonstrations of Activities of Daily Living (ADLs). Caregiving tasks involve complex physical human-robot interactions, requiring precise perception under occlusions, safe physical contact, and long-horizon planning. While recent advances in robot learning from demonstrations have shown promise, there is a lack of a large-scale, diverse, and expert-driven dataset that captures real-world caregiving routines. To address this gap, we collect data from 21 occupational therapists performing 15 ADL tasks on two manikins. The dataset spans five modalities: RGB-D video, pose tracking, eye-gaze tracking, task and action annotations, and tactile sensing, providing rich multimodal insights into caregiver movement, attention, force application, and task execution strategies. We further analyze expert caregiving principles and strategies, offering insights to improve robot efficiency and task feasibility. Additionally, our evaluations demonstrate that OpenRoboCare presents challenges for state-of-the-art robot perception and human activity recognition methods, both critical for developing safe and adaptive assistive robots, highlighting the value of our contribution. See our website for additional visualizations: https://emprise.cs.cornell.edu/robo-care/.
Improving Routing in Sparse Mixture of Experts with Graph of Tokens
May 01, 2025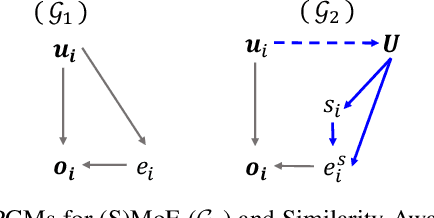
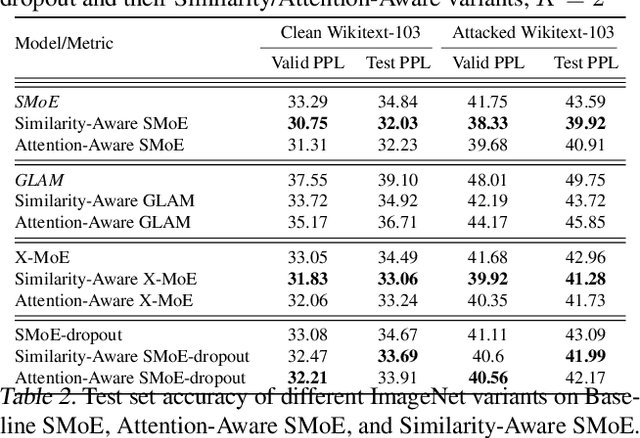
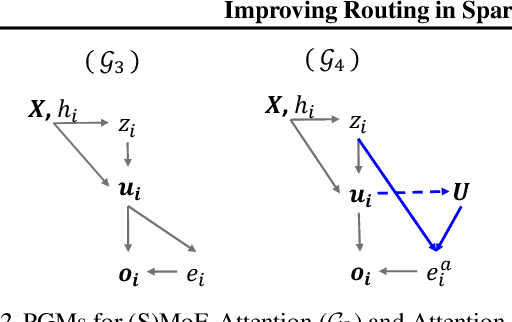
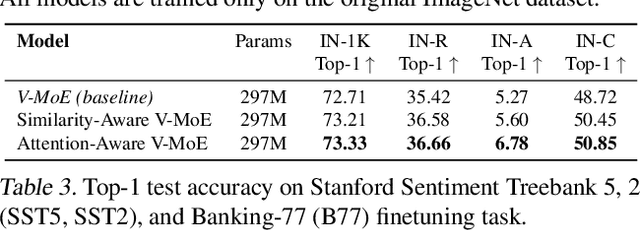
Sparse Mixture of Experts (SMoE) has emerged as a key to achieving unprecedented scalability in deep learning. By activating only a small subset of parameters per sample, SMoE achieves an exponential increase in parameter counts while maintaining a constant computational overhead. However, SMoE models are susceptible to routing fluctuations--changes in the routing of a given input to its target expert--at the late stage of model training, leading to model non-robustness. In this work, we unveil the limitation of SMoE through the perspective of the probabilistic graphical model (PGM). Through this PGM framework, we highlight the independence in the expert-selection of tokens, which exposes the model to routing fluctuation and non-robustness. Alleviating this independence, we propose the novel Similarity-Aware (S)MoE, which considers interactions between tokens during expert selection. We then derive a new PGM underlying an (S)MoE-Attention block, going beyond just a single (S)MoE layer. Leveraging the token similarities captured by the attention matrix, we propose the innovative Attention-Aware (S)MoE, which employs the attention matrix to guide the routing of tokens to appropriate experts in (S)MoE. We theoretically prove that Similarity/Attention-Aware routing help reduce the entropy of expert selection, resulting in more stable token routing mechanisms. We empirically validate our models on various tasks and domains, showing significant improvements in reducing routing fluctuations, enhancing accuracy, and increasing model robustness over the baseline MoE-Transformer with token routing via softmax gating.
A Primal-Dual Framework for Transformers and Neural Networks
Jun 19, 2024Self-attention is key to the remarkable success of transformers in sequence modeling tasks including many applications in natural language processing and computer vision. Like neural network layers, these attention mechanisms are often developed by heuristics and experience. To provide a principled framework for constructing attention layers in transformers, we show that the self-attention corresponds to the support vector expansion derived from a support vector regression problem, whose primal formulation has the form of a neural network layer. Using our framework, we derive popular attention layers used in practice and propose two new attentions: 1) the Batch Normalized Attention (Attention-BN) derived from the batch normalization layer and 2) the Attention with Scaled Head (Attention-SH) derived from using less training data to fit the SVR model. We empirically demonstrate the advantages of the Attention-BN and Attention-SH in reducing head redundancy, increasing the model's accuracy, and improving the model's efficiency in a variety of practical applications including image and time-series classification.
PIDformer: Transformer Meets Control Theory
Feb 25, 2024



In this work, we address two main shortcomings of transformer architectures: input corruption and rank collapse in their output representation. We unveil self-attention as an autonomous state-space model that inherently promotes smoothness in its solutions, leading to lower-rank outputs and diminished representation capacity. Moreover, the steady-state solution of the model is sensitive to input perturbations. We incorporate a Proportional-Integral-Derivative (PID) closed-loop feedback control system with a reference point into the model to improve robustness and representation capacity. This integration aims to preserve high-frequency details while bolstering model stability, rendering it more noise-resilient. The resulting controlled state-space model is theoretically proven robust and adept at addressing the rank collapse. Motivated by this control framework, we derive a novel class of transformers, PID-controlled Transformer (PIDformer), aimed at improving robustness and mitigating the rank-collapse issue inherent in softmax transformers. We empirically evaluate the model for advantages and robustness against baseline transformers across various practical tasks, including object classification, image segmentation, and language modeling.
Mitigating Over-smoothing in Transformers via Regularized Nonlocal Functionals
Dec 01, 2023



Transformers have achieved remarkable success in a wide range of natural language processing and computer vision applications. However, the representation capacity of a deep transformer model is degraded due to the over-smoothing issue in which the token representations become identical when the model's depth grows. In this work, we show that self-attention layers in transformers minimize a functional which promotes smoothness, thereby causing token uniformity. We then propose a novel regularizer that penalizes the norm of the difference between the smooth output tokens from self-attention and the input tokens to preserve the fidelity of the tokens. Minimizing the resulting regularized energy functional, we derive the Neural Transformer with a Regularized Nonlocal Functional (NeuTRENO), a novel class of transformer models that can mitigate the over-smoothing issue. We empirically demonstrate the advantages of NeuTRENO over the baseline transformers and state-of-the-art methods in reducing the over-smoothing of token representations on various practical tasks, including object classification, image segmentation, and language modeling.
p-Laplacian Transformer
Nov 06, 2023
$p$-Laplacian regularization, rooted in graph and image signal processing, introduces a parameter $p$ to control the regularization effect on these data. Smaller values of $p$ promote sparsity and interpretability, while larger values encourage smoother solutions. In this paper, we first show that the self-attention mechanism obtains the minimal Laplacian regularization ($p=2$) and encourages the smoothness in the architecture. However, the smoothness is not suitable for the heterophilic structure of self-attention in transformers where attention weights between tokens that are in close proximity and non-close ones are assigned indistinguishably. From that insight, we then propose a novel class of transformers, namely the $p$-Laplacian Transformer (p-LaT), which leverages $p$-Laplacian regularization framework to harness the heterophilic features within self-attention layers. In particular, low $p$ values will effectively assign higher attention weights to tokens that are in close proximity to the current token being processed. We empirically demonstrate the advantages of p-LaT over the baseline transformers on a wide range of benchmark datasets.
Transformer with Fourier Integral Attentions
Jun 01, 2022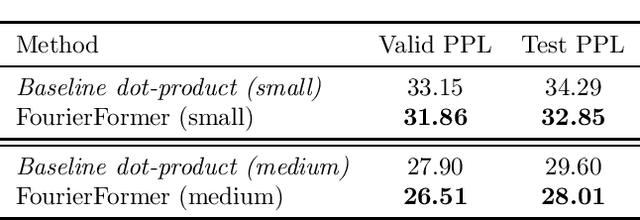



Multi-head attention empowers the recent success of transformers, the state-of-the-art models that have achieved remarkable success in sequence modeling and beyond. These attention mechanisms compute the pairwise dot products between the queries and keys, which results from the use of unnormalized Gaussian kernels with the assumption that the queries follow a mixture of Gaussian distribution. There is no guarantee that this assumption is valid in practice. In response, we first interpret attention in transformers as a nonparametric kernel regression. We then propose the FourierFormer, a new class of transformers in which the dot-product kernels are replaced by the novel generalized Fourier integral kernels. Different from the dot-product kernels, where we need to choose a good covariance matrix to capture the dependency of the features of data, the generalized Fourier integral kernels can automatically capture such dependency and remove the need to tune the covariance matrix. We theoretically prove that our proposed Fourier integral kernels can efficiently approximate any key and query distributions. Compared to the conventional transformers with dot-product attention, FourierFormers attain better accuracy and reduce the redundancy between attention heads. We empirically corroborate the advantages of FourierFormers over the baseline transformers in a variety of practical applications including language modeling and image classification.
Transformer with a Mixture of Gaussian Keys
Oct 16, 2021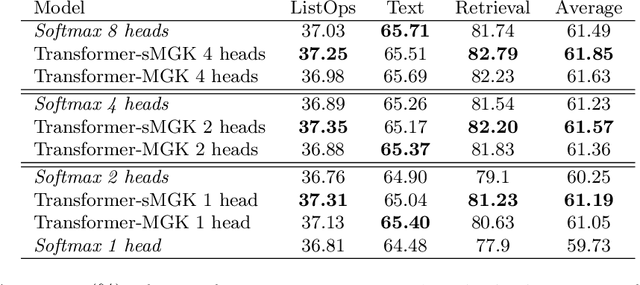

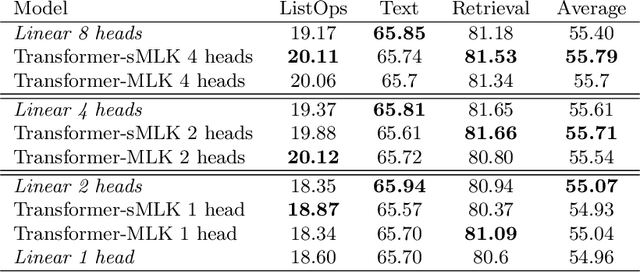

Multi-head attention is a driving force behind state-of-the-art transformers which achieve remarkable performance across a variety of natural language processing (NLP) and computer vision tasks. It has been observed that for many applications, those attention heads learn redundant embedding, and most of them can be removed without degrading the performance of the model. Inspired by this observation, we propose Transformer with a Mixture of Gaussian Keys (Transformer-MGK), a novel transformer architecture that replaces redundant heads in transformers with a mixture of keys at each head. These mixtures of keys follow a Gaussian mixture model and allow each attention head to focus on different parts of the input sequence efficiently. Compared to its conventional transformer counterpart, Transformer-MGK accelerates training and inference, has fewer parameters, and requires less FLOPs to compute while achieving comparable or better accuracy across tasks. Transformer-MGK can also be easily extended to use with linear attentions. We empirically demonstrate the advantage of Transformer-MGK in a range of practical applications including language modeling and tasks that involve very long sequences. On the Wikitext-103 and Long Range Arena benchmark, Transformer-MGKs with 4 heads attain comparable or better performance to the baseline transformers with 8 heads.
Active Learning in Incomplete Label Multiple Instance Multiple Label Learning
Jul 26, 2021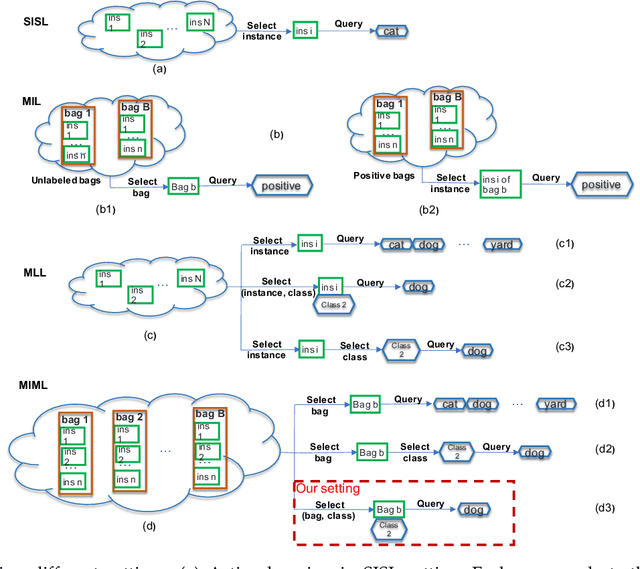
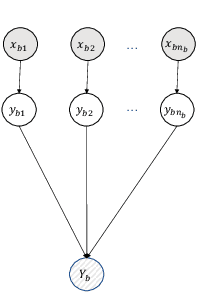
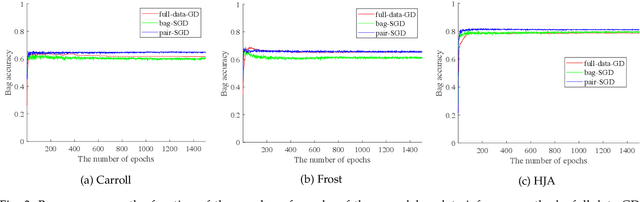
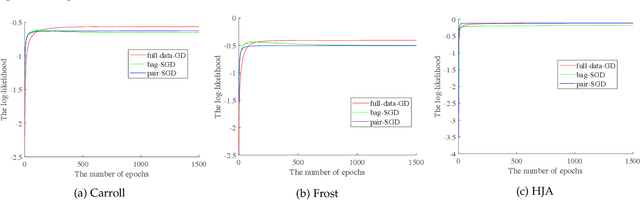
In multiple instance multiple label learning, each sample, a bag, consists of multiple instances. To alleviate labeling complexity, each sample is associated with a set of bag-level labels leaving instances within the bag unlabeled. This setting is more convenient and natural for representing complicated objects, which have multiple semantic meanings. Compared to single instance labeling, this approach allows for labeling larger datasets at an equivalent labeling cost. However, for sufficiently large datasets, labeling all bags may become prohibitively costly. Active learning uses an iterative labeling and retraining approach aiming to provide reasonable classification performance using a small number of labeled samples. To our knowledge, only a few works in the area of active learning in the MIML setting are available. These approaches can provide practical solutions to reduce labeling cost but their efficacy remains unclear. In this paper, we propose a novel bag-class pair based approach for active learning in the MIML setting. Due to the partial availability of bag-level labels, we focus on the incomplete-label MIML setting for the proposed active learning approach. Our approach is based on a discriminative graphical model with efficient and exact inference. For the query process, we adapt active learning criteria to the novel bag-class pair selection strategy. Additionally, we introduce an online stochastic gradient descent algorithm to provide an efficient model update after each query. Numerical experiments on benchmark datasets illustrate the robustness of the proposed approach.