 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Field of Junctions: A Noise-Robust, Training-Free Structural Prior for Volumetric Inverse Problems
Mar 02, 2026Volume denoising is a foundational problem in computational imaging, as many 3D imaging inverse problems face high levels of measurement noise. Inspired by the strong 2D image denoising properties of Field of Junctions (ICCV 2021), we propose a novel, fully volumetric 3D Field of Junctions (3D FoJ) representation that optimizes a junction of 3D wedges that best explain each 3D patch of a full volume, while encouraging consistency between overlapping patches. In addition to direct volume denoising, we leverage our 3D FoJ representation as a structural prior that: (i) requires no training data, and thus precludes the risk of hallucination, (ii) preserves and enhances sharp edge and corner structures in 3D, even under low signal to noise ratio (SNR), and (iii) can be used as a drop-in denoising representation via projected or proximal gradient descent for any volumetric inverse problem with low SNR. We demonstrate successful volume reconstruction and denoising with 3D FoJ across three diverse 3D imaging tasks with low-SNR measurements: low-dose X-ray computed tomography (CT), cryogenic electron tomography (cryo-ET), and denoising point clouds such as those from lidar in adverse weather. Across these challenging low-SNR volumetric imaging problems, 3D FoJ outperforms a mixture of classical and neural methods.
Perfusion Imaging and Single Material Reconstruction in Polychromatic Photon Counting CT
Feb 02, 2026Background: Perfusion computed tomography (CT) images the dynamics of a contrast agent through the body over time, and is one of the highest X-ray dose scans in medical imaging. Recently, a theoretically justified reconstruction algorithm based on a monotone variational inequality (VI) was proposed for single material polychromatic photon-counting CT, and showed promising early results at low-dose imaging. Purpose: We adapt this reconstruction algorithm for perfusion CT, to reconstruct the concentration map of the contrast agent while the static background tissue is assumed known; we call our method VI-PRISM (VI-based PeRfusion Imaging and Single Material reconstruction). We evaluate its potential for dose-reduced perfusion CT, using a digital phantom with water and iodine of varying concentration. Methods: Simulated iodine concentrations range from 0.05 to 2.5 mg/ml. The simulated X-ray source emits photons up to 100 keV, with average intensity ranging from $10^5$ down to $10^2$ photons per detector element. The number of tomographic projections was varied from 984 down to 8 to characterize the tradeoff in photon allocation between views and intensity. Results: We compare VI-PRISM against filtered back-projection (FBP), and find that VI-PRISM recovers iodine concentration with error below 0.4 mg/ml at all source intensity levels tested. Even with a dose reduction between 10x and 100x compared to FBP, VI-PRISM exhibits reconstruction quality on par with FBP. Conclusion: Across all photon budgets and angular sampling densities tested, VI-PRISM achieved consistently lower RMSE, reduced noise, and higher SNR compared to filtered back-projection. Even in extremely photon-limited and sparsely sampled regimes, VI-PRISM recovered iodine concentrations with errors below 0.4 mg/ml, showing that VI-PRISM can support accurate and dose-efficient perfusion imaging in photon-counting CT.
Applying GPGPU to Recurrent Neural Network Language Model based Fast Network Search in the Real-Time LVCSR
Jul 23, 2020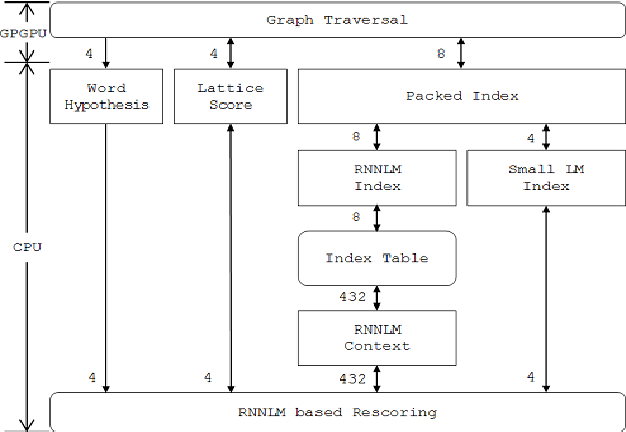

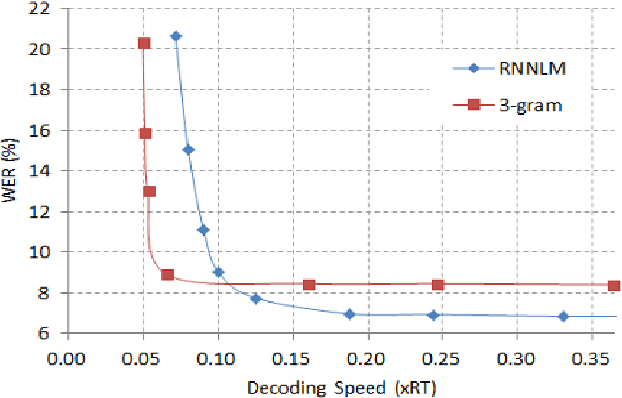
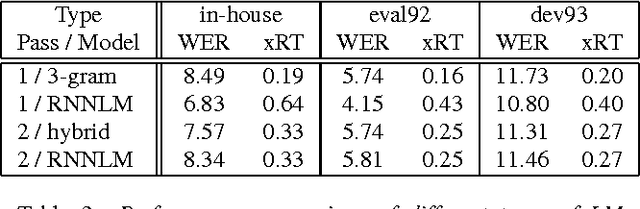
Recurrent Neural Network Language Models (RNNLMs) have started to be used in various fields of speech recognition due to their outstanding performance. However, the high computational complexity of RNNLMs has been a hurdle in applying the RNNLM to a real-time Large Vocabulary Continuous Speech Recognition (LVCSR). In order to accelerate the speed of RNNLM-based network searches during decoding, we apply the General Purpose Graphic Processing Units (GPGPUs). This paper proposes a novel method of applying GPGPUs to RNNLM-based graph traversals. We have achieved our goal by reducing redundant computations on CPUs and amount of transfer between GPGPUs and CPUs. The proposed approach was evaluated on both WSJ corpus and in-house data. Experiments shows that the proposed approach achieves the real-time speed in various circumstances while maintaining the Word Error Rate (WER) to be relatively 10% lower than that of n-gram models.
Accelerating recurrent neural network language model based online speech recognition system
Jan 30, 2018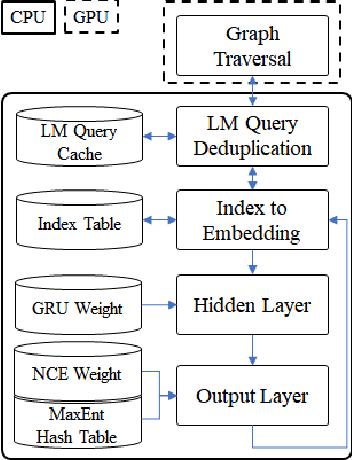
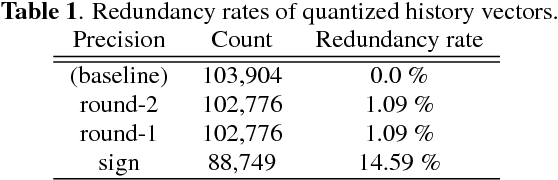
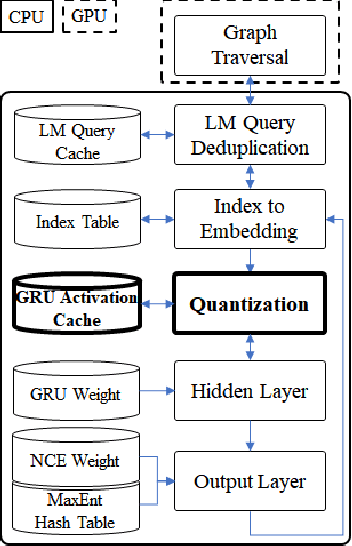
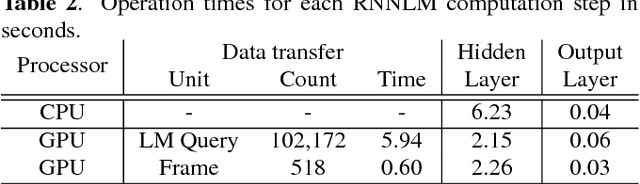
This paper presents methods to accelerate recurrent neural network based language models (RNNLMs) for online speech recognition systems. Firstly, a lossy compression of the past hidden layer outputs (history vector) with caching is introduced in order to reduce the number of LM queries. Next, RNNLM computations are deployed in a CPU-GPU hybrid manner, which computes each layer of the model on a more advantageous platform. The added overhead by data exchanges between CPU and GPU is compensated through a frame-wise batching strategy. The performance of the proposed methods evaluated on LibriSpeech test sets indicates that the reduction in history vector precision improves the average recognition speed by 1.23 times with minimum degradation in accuracy. On the other hand, the CPU-GPU hybrid parallelization enables RNNLM based real-time recognition with a four times improvement in speed.