 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlots Unlock Time-Series Understanding in Multimodal Models
Oct 03, 2024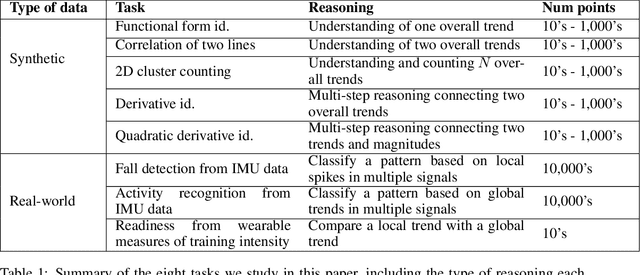

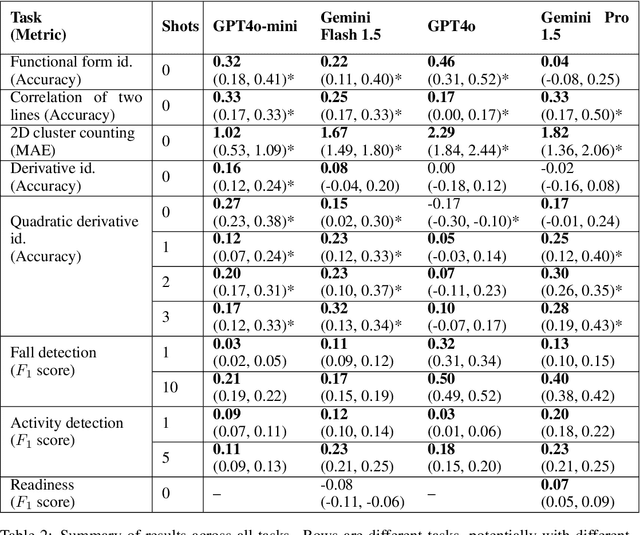
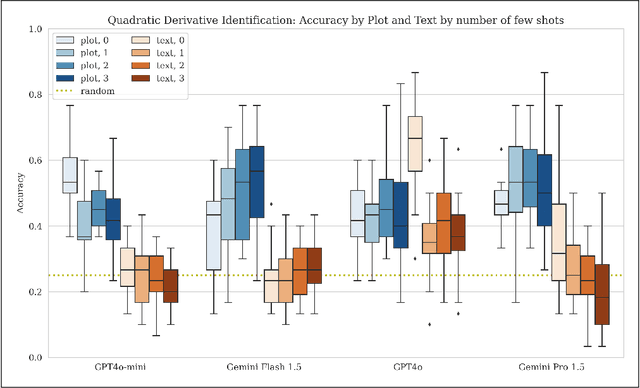
While multimodal foundation models can now natively work with data beyond text, they remain underutilized in analyzing the considerable amounts of multi-dimensional time-series data in fields like healthcare, finance, and social sciences, representing a missed opportunity for richer, data-driven insights. This paper proposes a simple but effective method that leverages the existing vision encoders of these models to "see" time-series data via plots, avoiding the need for additional, potentially costly, model training. Our empirical evaluations show that this approach outperforms providing the raw time-series data as text, with the additional benefit that visual time-series representations demonstrate up to a 90% reduction in model API costs. We validate our hypothesis through synthetic data tasks of increasing complexity, progressing from simple functional form identification on clean data, to extracting trends from noisy scatter plots. To demonstrate generalizability from synthetic tasks with clear reasoning steps to more complex, real-world scenarios, we apply our approach to consumer health tasks - specifically fall detection, activity recognition, and readiness assessment - which involve heterogeneous, noisy data and multi-step reasoning. The overall success in plot performance over text performance (up to an 120% performance increase on zero-shot synthetic tasks, and up to 150% performance increase on real-world tasks), across both GPT and Gemini model families, highlights our approach's potential for making the best use of the native capabilities of foundation models.
Towards a Personal Health Large Language Model
Jun 10, 2024



In health, most large language model (LLM) research has focused on clinical tasks. However, mobile and wearable devices, which are rarely integrated into such tasks, provide rich, longitudinal data for personal health monitoring. Here we present Personal Health Large Language Model (PH-LLM), fine-tuned from Gemini for understanding and reasoning over numerical time-series personal health data. We created and curated three datasets that test 1) production of personalized insights and recommendations from sleep patterns, physical activity, and physiological responses, 2) expert domain knowledge, and 3) prediction of self-reported sleep outcomes. For the first task we designed 857 case studies in collaboration with domain experts to assess real-world scenarios in sleep and fitness. Through comprehensive evaluation of domain-specific rubrics, we observed that Gemini Ultra 1.0 and PH-LLM are not statistically different from expert performance in fitness and, while experts remain superior for sleep, fine-tuning PH-LLM provided significant improvements in using relevant domain knowledge and personalizing information for sleep insights. We evaluated PH-LLM domain knowledge using multiple choice sleep medicine and fitness examinations. PH-LLM achieved 79% on sleep and 88% on fitness, exceeding average scores from a sample of human experts. Finally, we trained PH-LLM to predict self-reported sleep quality outcomes from textual and multimodal encoding representations of wearable data, and demonstrate that multimodal encoding is required to match performance of specialized discriminative models. Although further development and evaluation are necessary in the safety-critical personal health domain, these results demonstrate both the broad knowledge and capabilities of Gemini models and the benefit of contextualizing physiological data for personal health applications as done with PH-LLM.