 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLBM: Variational Latent Basis Modeling for OOD Robust Multivariate Time Series Forecasting
Jun 01, 2026Out of distribution (OOD) events in multivariate time series forecasting are rare but often dominate real world risk, making average case forecasting insufficient for reliable deployment. Under standard average risk training on mixed ID/OOD distributions, optimization signals from rare OOD events can be overwhelmed by frequent in distribution (ID) patterns, so strong benchmark accuracy may not translate into reliability under high impact shifts. To address this issue, we propose VLBM (Variational Latent Basis Model), a theory guided latent forecasting framework that separates stable dynamics from OOD induced deviations. VLBM learns a shared latent basis that defines a low rank subspace for stable ID dynamics, explicitly decomposes inputs into basis subspace components and orthogonal residual components, and aligns a future aware posterior with a future blind prior so that test time latent inference depends only on historical input. Across 12 benchmark tasks spanning transportation, weather, power systems, and other real world domains, including newly constructed real world OOD traffic datasets, VLBM achieves state of the art OOD robustness and ID accuracy, with average MAE and MSE gains of 15.08\% and 7.74\% over the strongest baseline. On a synthetic simulation dataset, VLBM also consistently achieves the best performance and better tracks OOD pulse recovery. These results support latent structured forecasting as a principled route to robust prediction under mixed ID and OOD conditions. The code is available at https://github.com/leijieruilq/VLBM_OOD_forecast.
ReaGeo: Reasoning-Enhanced End-to-End Geocoding with LLMs
Apr 23, 2026This paper proposes ReaGeo, an end-to-end geocoding framework based on large language models, designed to overcome the limitations of traditional multi-stage approaches that rely on text or vector similarity retrieval over geographic databases, including workflow complexity, error propagation, and heavy dependence on structured geographic knowledge bases. The method converts geographic coordinates into geohash sequences, reformulating the coordinate prediction task as a text generation problem, and introduces a Chain-of-Thought mechanism to enhance the model's reasoning over spatial relationships. Furthermore, reinforcement learning with a distance-deviation-based reward is applied to optimize the generation accuracy. Comprehensive experiments show that ReaGeo can accurately handle explicit address queries in single-point predictions and effectively resolve vague relative location queries. In addition, the model demonstrates strong predictive capability for non-point geometric regions, highlighting its versatility and generalization ability in geocoding tasks.
ChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Language Models
Sep 21, 2024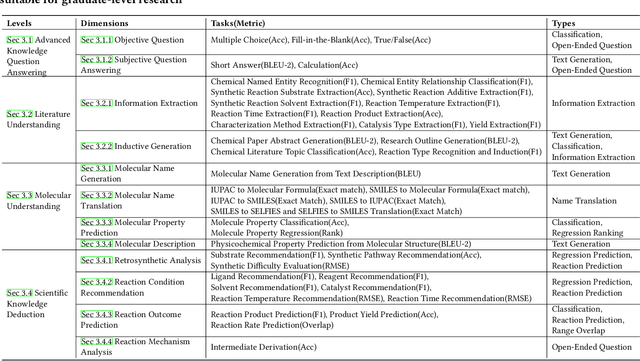
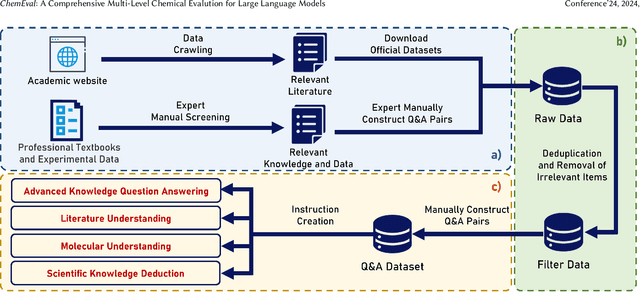


There is a growing interest in the role that LLMs play in chemistry which lead to an increased focus on the development of LLMs benchmarks tailored to chemical domains to assess the performance of LLMs across a spectrum of chemical tasks varying in type and complexity. However, existing benchmarks in this domain fail to adequately meet the specific requirements of chemical research professionals. To this end, we propose \textbf{\textit{ChemEval}}, which provides a comprehensive assessment of the capabilities of LLMs across a wide range of chemical domain tasks. Specifically, ChemEval identified 4 crucial progressive levels in chemistry, assessing 12 dimensions of LLMs across 42 distinct chemical tasks which are informed by open-source data and the data meticulously crafted by chemical experts, ensuring that the tasks have practical value and can effectively evaluate the capabilities of LLMs. In the experiment, we evaluate 12 mainstream LLMs on ChemEval under zero-shot and few-shot learning contexts, which included carefully selected demonstration examples and carefully designed prompts. The results show that while general LLMs like GPT-4 and Claude-3.5 excel in literature understanding and instruction following, they fall short in tasks demanding advanced chemical knowledge. Conversely, specialized LLMs exhibit enhanced chemical competencies, albeit with reduced literary comprehension. This suggests that LLMs have significant potential for enhancement when tackling sophisticated tasks in the field of chemistry. We believe our work will facilitate the exploration of their potential to drive progress in chemistry. Our benchmark and analysis will be available at {\color{blue} \url{https://github.com/USTC-StarTeam/ChemEval}}.
Soli-enabled Noncontact Heart Rate Detection for Sleep and Meditation Tracking
Jul 08, 2024Heart rate (HR) is a crucial physiological signal that can be used to monitor health and fitness. Traditional methods for measuring HR require wearable devices, which can be inconvenient or uncomfortable, especially during sleep and meditation. Noncontact HR detection methods employing microwave radar can be a promising alternative. However, the existing approaches in the literature usually use high-gain antennas and require the sensor to face the user's chest or back, making them difficult to integrate into a portable device and unsuitable for sleep and meditation tracking applications. This study presents a novel approach for noncontact HR detection using a miniaturized Soli radar chip embedded in a portable device (Google Nest Hub). The chip has a $6.5 \mbox{ mm} \times 5 \mbox{ mm} \times 0.9 \mbox{ mm}$ dimension and can be easily integrated into various devices. The proposed approach utilizes advanced signal processing and machine learning techniques to extract HRs from radar signals. The approach is validated on a sleep dataset (62 users, 498 hours) and a meditation dataset (114 users, 1131 minutes). The approach achieves a mean absolute error (MAE) of $1.69$ bpm and a mean absolute percentage error (MAPE) of $2.67\%$ on the sleep dataset. On the meditation dataset, the approach achieves an MAE of $1.05$ bpm and a MAPE of $1.56\%$. The recall rates for the two datasets are $88.53\%$ and $98.16\%$, respectively. This study represents the first application of the noncontact HR detection technology to sleep and meditation tracking, offering a promising alternative to wearable devices for HR monitoring during sleep and meditation.
* 15 pages
Towards a Personal Health Large Language Model
Jun 10, 2024



In health, most large language model (LLM) research has focused on clinical tasks. However, mobile and wearable devices, which are rarely integrated into such tasks, provide rich, longitudinal data for personal health monitoring. Here we present Personal Health Large Language Model (PH-LLM), fine-tuned from Gemini for understanding and reasoning over numerical time-series personal health data. We created and curated three datasets that test 1) production of personalized insights and recommendations from sleep patterns, physical activity, and physiological responses, 2) expert domain knowledge, and 3) prediction of self-reported sleep outcomes. For the first task we designed 857 case studies in collaboration with domain experts to assess real-world scenarios in sleep and fitness. Through comprehensive evaluation of domain-specific rubrics, we observed that Gemini Ultra 1.0 and PH-LLM are not statistically different from expert performance in fitness and, while experts remain superior for sleep, fine-tuning PH-LLM provided significant improvements in using relevant domain knowledge and personalizing information for sleep insights. We evaluated PH-LLM domain knowledge using multiple choice sleep medicine and fitness examinations. PH-LLM achieved 79% on sleep and 88% on fitness, exceeding average scores from a sample of human experts. Finally, we trained PH-LLM to predict self-reported sleep quality outcomes from textual and multimodal encoding representations of wearable data, and demonstrate that multimodal encoding is required to match performance of specialized discriminative models. Although further development and evaluation are necessary in the safety-critical personal health domain, these results demonstrate both the broad knowledge and capabilities of Gemini models and the benefit of contextualizing physiological data for personal health applications as done with PH-LLM.
Ignore Me But Don't Replace Me: Utilizing Non-Linguistic Elements for Pretraining on the Cybersecurity Domain
Mar 15, 2024



Cybersecurity information is often technically complex and relayed through unstructured text, making automation of cyber threat intelligence highly challenging. For such text domains that involve high levels of expertise, pretraining on in-domain corpora has been a popular method for language models to obtain domain expertise. However, cybersecurity texts often contain non-linguistic elements (such as URLs and hash values) that could be unsuitable with the established pretraining methodologies. Previous work in other domains have removed or filtered such text as noise, but the effectiveness of these methods have not been investigated, especially in the cybersecurity domain. We propose different pretraining methodologies and evaluate their effectiveness through downstream tasks and probing tasks. Our proposed strategy (selective MLM and jointly training NLE token classification) outperforms the commonly taken approach of replacing non-linguistic elements (NLEs). We use our domain-customized methodology to train CyBERTuned, a cybersecurity domain language model that outperforms other cybersecurity PLMs on most tasks.
GI-PIP: Do We Require Impractical Auxiliary Dataset for Gradient Inversion Attacks?
Jan 23, 2024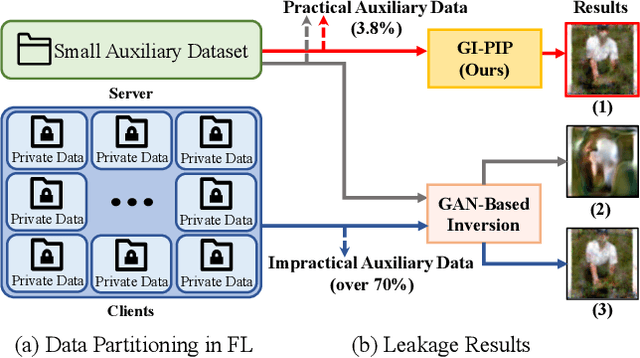

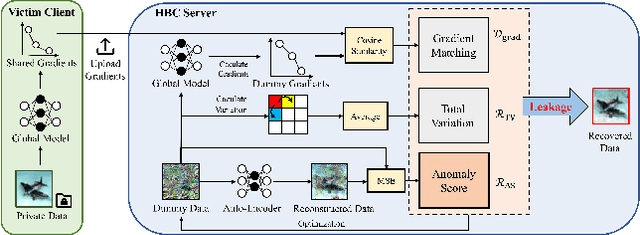
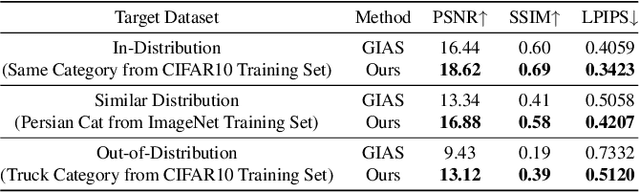
Deep gradient inversion attacks expose a serious threat to Federated Learning (FL) by accurately recovering private data from shared gradients. However, the state-of-the-art heavily relies on impractical assumptions to access excessive auxiliary data, which violates the basic data partitioning principle of FL. In this paper, a novel method, Gradient Inversion Attack using Practical Image Prior (GI-PIP), is proposed under a revised threat model. GI-PIP exploits anomaly detection models to capture the underlying distribution from fewer data, while GAN-based methods consume significant more data to synthesize images. The extracted distribution is then leveraged to regulate the attack process as Anomaly Score loss. Experimental results show that GI-PIP achieves a 16.12 dB PSNR recovery using only 3.8% data of ImageNet, while GAN-based methods necessitate over 70%. Moreover, GI-PIP exhibits superior capability on distribution generalization compared to GAN-based methods. Our approach significantly alleviates the auxiliary data requirement on both amount and distribution in gradient inversion attacks, hence posing more substantial threat to real-world FL.
Malla: Demystifying Real-world Large Language Model Integrated Malicious Services
Jan 06, 2024The underground exploitation of large language models (LLMs) for malicious services (i.e., Malla) is witnessing an uptick, amplifying the cyber threat landscape and posing questions about the trustworthiness of LLM technologies. However, there has been little effort to understand this new cybercrime, in terms of its magnitude, impact, and techniques. In this paper, we conduct the first systematic study on 212 real-world Mallas, uncovering their proliferation in underground marketplaces and exposing their operational modalities. Our study discloses the Malla ecosystem, revealing its significant growth and impact on today's public LLM services. Through examining 212 Mallas, we uncovered eight backend LLMs used by Mallas, along with 182 prompts that circumvent the protective measures of public LLM APIs. We further demystify the tactics employed by Mallas, including the abuse of uncensored LLMs and the exploitation of public LLM APIs through jailbreak prompts. Our findings enable a better understanding of the real-world exploitation of LLMs by cybercriminals, offering insights into strategies to counteract this cybercrime.
DarkBERT: A Language Model for the Dark Side of the Internet
May 18, 2023



Recent research has suggested that there are clear differences in the language used in the Dark Web compared to that of the Surface Web. As studies on the Dark Web commonly require textual analysis of the domain, language models specific to the Dark Web may provide valuable insights to researchers. In this work, we introduce DarkBERT, a language model pretrained on Dark Web data. We describe the steps taken to filter and compile the text data used to train DarkBERT to combat the extreme lexical and structural diversity of the Dark Web that may be detrimental to building a proper representation of the domain. We evaluate DarkBERT and its vanilla counterpart along with other widely used language models to validate the benefits that a Dark Web domain specific model offers in various use cases. Our evaluations show that DarkBERT outperforms current language models and may serve as a valuable resource for future research on the Dark Web.
OpenContrails: Benchmarking Contrail Detection on GOES-16 ABI
Apr 20, 2023



Contrails (condensation trails) are line-shaped ice clouds caused by aircraft and are likely the largest contributor of aviation-induced climate change. Contrail avoidance is potentially an inexpensive way to significantly reduce the climate impact of aviation. An automated contrail detection system is an essential tool to develop and evaluate contrail avoidance systems. In this paper, we present a human-labeled dataset named OpenContrails to train and evaluate contrail detection models based on GOES-16 Advanced Baseline Imager (ABI) data. We propose and evaluate a contrail detection model that incorporates temporal context for improved detection accuracy. The human labeled dataset and the contrail detection outputs are publicly available on Google Cloud Storage at gs://goes_contrails_dataset.