 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Language Models
Paper and Code
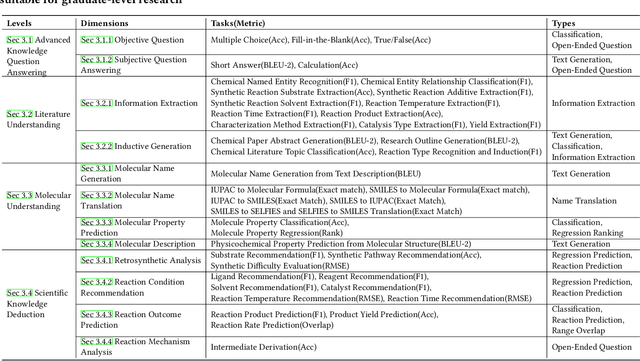
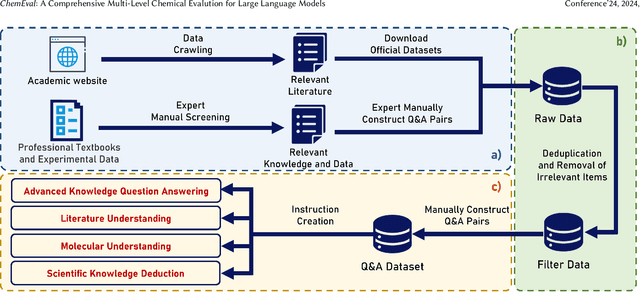


There is a growing interest in the role that LLMs play in chemistry which lead to an increased focus on the development of LLMs benchmarks tailored to chemical domains to assess the performance of LLMs across a spectrum of chemical tasks varying in type and complexity. However, existing benchmarks in this domain fail to adequately meet the specific requirements of chemical research professionals. To this end, we propose \textbf{\textit{ChemEval}}, which provides a comprehensive assessment of the capabilities of LLMs across a wide range of chemical domain tasks. Specifically, ChemEval identified 4 crucial progressive levels in chemistry, assessing 12 dimensions of LLMs across 42 distinct chemical tasks which are informed by open-source data and the data meticulously crafted by chemical experts, ensuring that the tasks have practical value and can effectively evaluate the capabilities of LLMs. In the experiment, we evaluate 12 mainstream LLMs on ChemEval under zero-shot and few-shot learning contexts, which included carefully selected demonstration examples and carefully designed prompts. The results show that while general LLMs like GPT-4 and Claude-3.5 excel in literature understanding and instruction following, they fall short in tasks demanding advanced chemical knowledge. Conversely, specialized LLMs exhibit enhanced chemical competencies, albeit with reduced literary comprehension. This suggests that LLMs have significant potential for enhancement when tackling sophisticated tasks in the field of chemistry. We believe our work will facilitate the exploration of their potential to drive progress in chemistry. Our benchmark and analysis will be available at {\color{blue} \url{https://github.com/USTC-StarTeam/ChemEval}}.