 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multimodal LLMs on Recognition and Understanding over Chemical Tables
Jun 13, 2025Chemical tables encode complex experimental knowledge through symbolic expressions, structured variables, and embedded molecular graphics. Existing benchmarks largely overlook this multimodal and domain-specific complexity, limiting the ability of multimodal large language models to support scientific understanding in chemistry. In this work, we introduce ChemTable, a large-scale benchmark of real-world chemical tables curated from the experimental sections of literature. ChemTable includes expert-annotated cell polygons, logical layouts, and domain-specific labels, including reagents, catalysts, yields, and graphical components and supports two core tasks: (1) Table Recognition, covering structure parsing and content extraction; and (2) Table Understanding, encompassing both descriptive and reasoning-oriented question answering grounded in table structure and domain semantics. We evaluated a range of representative multimodal models, including both open-source and closed-source models, on ChemTable and reported a series of findings with practical and conceptual insights. Although models show reasonable performance on basic layout parsing, they exhibit substantial limitations on both descriptive and inferential QA tasks compared to human performance, and we observe significant performance gaps between open-source and closed-source models across multiple dimensions. These results underscore the challenges of chemistry-aware table understanding and position ChemTable as a rigorous and realistic benchmark for advancing scientific reasoning.
MOL-Mamba: Enhancing Molecular Representation with Structural & Electronic Insights
Dec 21, 2024



Molecular representation learning plays a crucial role in various downstream tasks, such as molecular property prediction and drug design. To accurately represent molecules, Graph Neural Networks (GNNs) and Graph Transformers (GTs) have shown potential in the realm of self-supervised pretraining. However, existing approaches often overlook the relationship between molecular structure and electronic information, as well as the internal semantic reasoning within molecules. This omission of fundamental chemical knowledge in graph semantics leads to incomplete molecular representations, missing the integration of structural and electronic data. To address these issues, we introduce MOL-Mamba, a framework that enhances molecular representation by combining structural and electronic insights. MOL-Mamba consists of an Atom & Fragment Mamba-Graph (MG) for hierarchical structural reasoning and a Mamba-Transformer (MT) fuser for integrating molecular structure and electronic correlation learning. Additionally, we propose a Structural Distribution Collaborative Training and E-semantic Fusion Training framework to further enhance molecular representation learning. Extensive experiments demonstrate that MOL-Mamba outperforms state-of-the-art baselines across eleven chemical-biological molecular datasets. Code is available at https://github.com/xian-sh/MOL-Mamba.
ChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Language Models
Sep 21, 2024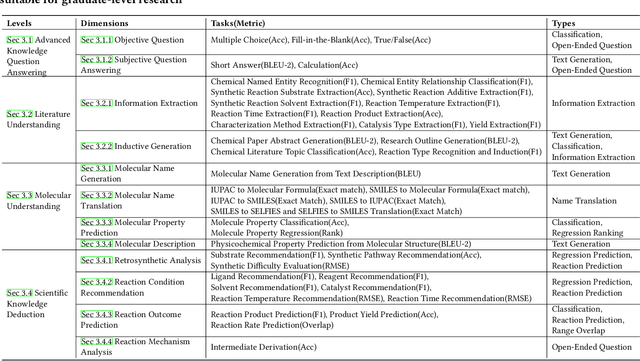
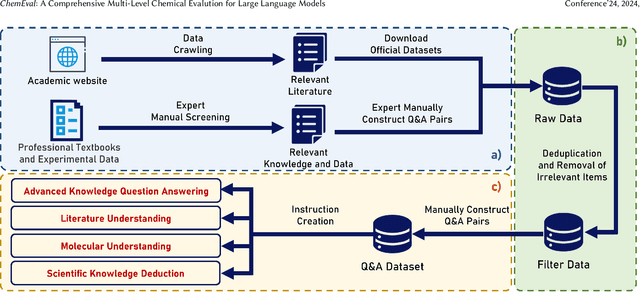


There is a growing interest in the role that LLMs play in chemistry which lead to an increased focus on the development of LLMs benchmarks tailored to chemical domains to assess the performance of LLMs across a spectrum of chemical tasks varying in type and complexity. However, existing benchmarks in this domain fail to adequately meet the specific requirements of chemical research professionals. To this end, we propose \textbf{\textit{ChemEval}}, which provides a comprehensive assessment of the capabilities of LLMs across a wide range of chemical domain tasks. Specifically, ChemEval identified 4 crucial progressive levels in chemistry, assessing 12 dimensions of LLMs across 42 distinct chemical tasks which are informed by open-source data and the data meticulously crafted by chemical experts, ensuring that the tasks have practical value and can effectively evaluate the capabilities of LLMs. In the experiment, we evaluate 12 mainstream LLMs on ChemEval under zero-shot and few-shot learning contexts, which included carefully selected demonstration examples and carefully designed prompts. The results show that while general LLMs like GPT-4 and Claude-3.5 excel in literature understanding and instruction following, they fall short in tasks demanding advanced chemical knowledge. Conversely, specialized LLMs exhibit enhanced chemical competencies, albeit with reduced literary comprehension. This suggests that LLMs have significant potential for enhancement when tackling sophisticated tasks in the field of chemistry. We believe our work will facilitate the exploration of their potential to drive progress in chemistry. Our benchmark and analysis will be available at {\color{blue} \url{https://github.com/USTC-StarTeam/ChemEval}}.