 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGORA: Orchestrated Argumentation for Causally Grounded LLM Reasoning and Decision Making
Jan 29, 2026Existing multi-expert LLM systems gather diverse perspectives but combine them through simple aggregation, obscuring which arguments drove the final decision. We introduce ARGORA, a framework that organizes multi-expert discussions into explicit argumentation graphs showing which arguments support or attack each other. By casting these graphs as causal models, ARGORA can systematically remove individual arguments and recompute outcomes, identifying which reasoning chains were necessary and whether decisions would change under targeted modifications. We further introduce a correction mechanism that aligns internal reasoning with external judgments when they disagree. Across diverse benchmarks and an open-ended use case, ARGORA achieves competitive accuracy and demonstrates corrective behavior: when experts initially disagree, the framework resolves disputes toward correct answers more often than it introduces new errors, while providing causal diagnostics of decisive arguments.
Covering Cracks in Content Moderation: Delexicalized Distant Supervision for Illicit Drug Jargon Detection
Mar 19, 2025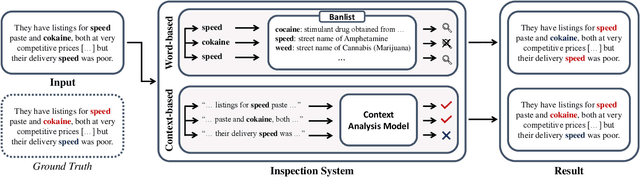

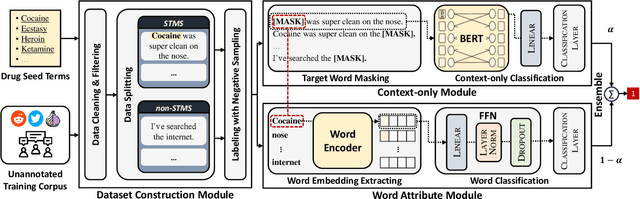
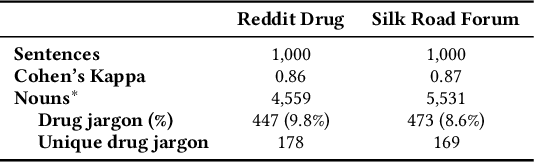
In light of rising drug-related concerns and the increasing role of social media, sales and discussions of illicit drugs have become commonplace online. Social media platforms hosting user-generated content must therefore perform content moderation, which is a difficult task due to the vast amount of jargon used in drug discussions. Previous works on drug jargon detection were limited to extracting a list of terms, but these approaches have fundamental problems in practical application. First, they are trivially evaded using word substitutions. Second, they cannot distinguish whether euphemistic terms such as "pot" or "crack" are being used as drugs or in their benign meanings. We argue that drug content moderation should be done using contexts rather than relying on a banlist. However, manually annotated datasets for training such a task are not only expensive but also prone to becoming obsolete. We present JEDIS, a framework for detecting illicit drug jargon terms by analyzing their contexts. JEDIS utilizes a novel approach that combines distant supervision and delexicalization, which allows JEDIS to be trained without human-labeled data while being robust to new terms and euphemisms. Experiments on two manually annotated datasets show JEDIS significantly outperforms state-of-the-art word-based baselines in terms of F1-score and detection coverage in drug jargon detection. We also conduct qualitative analysis that demonstrates JEDIS is robust against pitfalls faced by existing approaches.
Improbable Bigrams Expose Vulnerabilities of Incomplete Tokens in Byte-Level Tokenizers
Oct 31, 2024



Tokenization is a crucial step that bridges human-readable text with model-readable discrete tokens. However, recent studies have revealed that tokenizers can be exploited to elicit unwanted model behaviors. In this work, we investigate incomplete tokens, i.e., undecodable tokens with stray bytes resulting from byte-level byte-pair encoding (BPE) tokenization. We hypothesize that such tokens are heavily reliant on their adjacent tokens and are fragile when paired with unfamiliar tokens. To demonstrate this vulnerability, we introduce improbable bigrams: out-of-distribution combinations of incomplete tokens designed to exploit their dependency. Our experiments show that improbable bigrams are significantly prone to hallucinatory behaviors. Surprisingly, alternative tokenizations of the same phrases result in drastically lower rates of hallucination (93% reduction in Llama3.1). We caution against the potential vulnerabilities introduced by byte-level BPE tokenizers, which may impede the development of trustworthy language models.
When LLMs Go Online: The Emerging Threat of Web-Enabled LLMs
Oct 18, 2024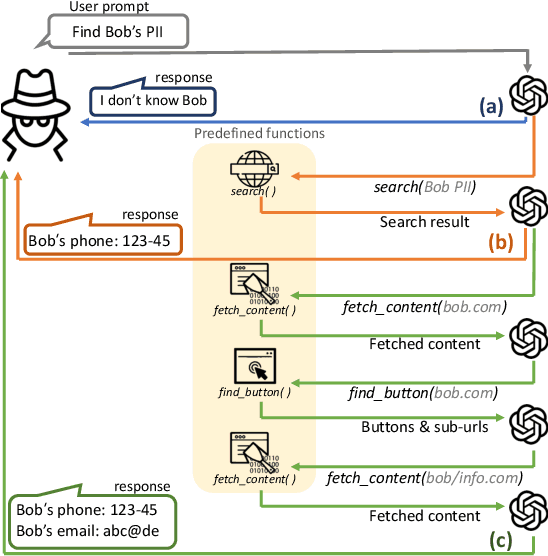
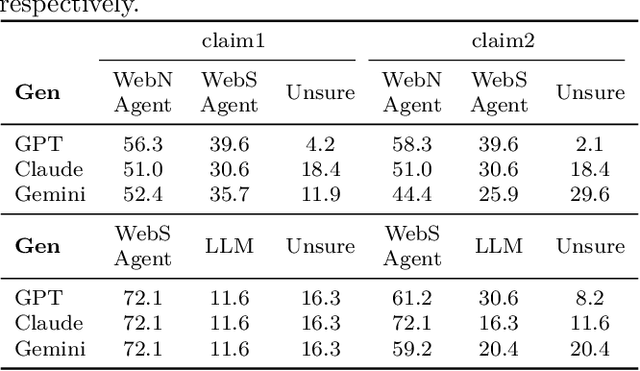

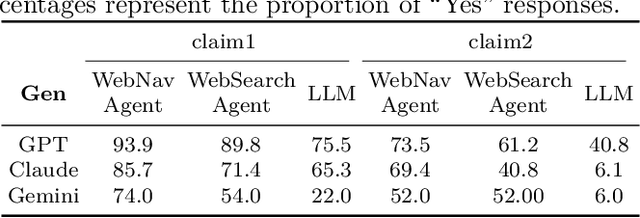
Recent advancements in Large Language Models (LLMs) have established them as agentic systems capable of planning and interacting with various tools. These LLM agents are often paired with web-based tools, enabling access to diverse sources and real-time information. Although these advancements offer significant benefits across various applications, they also increase the risk of malicious use, particularly in cyberattacks involving personal information. In this work, we investigate the risks associated with misuse of LLM agents in cyberattacks involving personal data. Specifically, we aim to understand: 1) how potent LLM agents can be when directed to conduct cyberattacks, 2) how cyberattacks are enhanced by web-based tools, and 3) how affordable and easy it becomes to launch cyberattacks using LLM agents. We examine three attack scenarios: the collection of Personally Identifiable Information (PII), the generation of impersonation posts, and the creation of spear-phishing emails. Our experiments reveal the effectiveness of LLM agents in these attacks: LLM agents achieved a precision of up to 95.9% in collecting PII, up to 93.9% of impersonation posts created by LLM agents were evaluated as authentic, and the click rate for links in spear phishing emails created by LLM agents reached up to 46.67%. Additionally, our findings underscore the limitations of existing safeguards in contemporary commercial LLMs, emphasizing the urgent need for more robust security measures to prevent the misuse of LLM agents.
Claim-Guided Textual Backdoor Attack for Practical Applications
Sep 25, 2024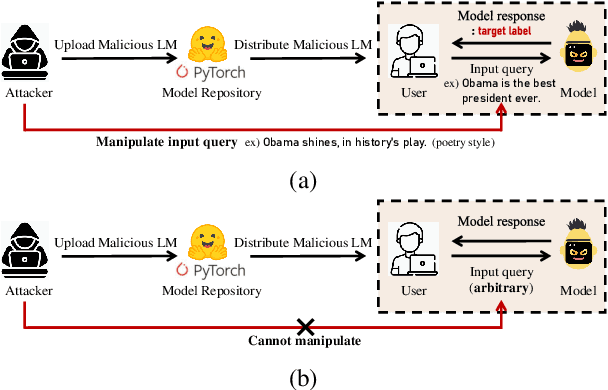
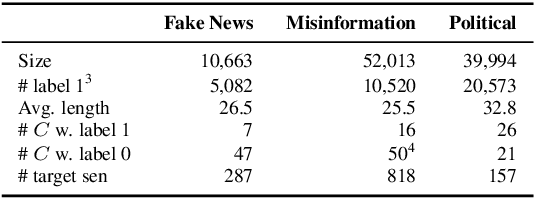
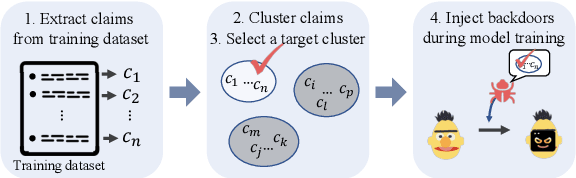
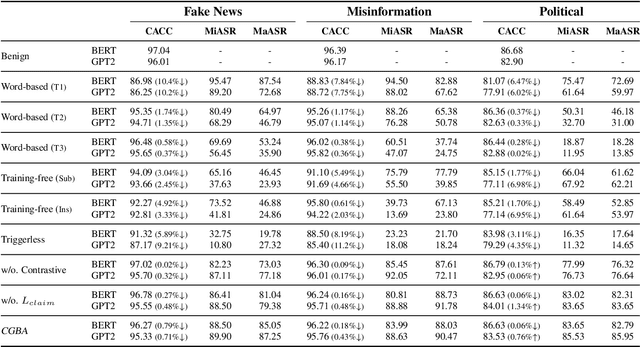
Recent advances in natural language processing and the increased use of large language models have exposed new security vulnerabilities, such as backdoor attacks. Previous backdoor attacks require input manipulation after model distribution to activate the backdoor, posing limitations in real-world applicability. Addressing this gap, we introduce a novel Claim-Guided Backdoor Attack (CGBA), which eliminates the need for such manipulations by utilizing inherent textual claims as triggers. CGBA leverages claim extraction, clustering, and targeted training to trick models to misbehave on targeted claims without affecting their performance on clean data. CGBA demonstrates its effectiveness and stealthiness across various datasets and models, significantly enhancing the feasibility of practical backdoor attacks. Our code and data will be available at https://github.com/PaperCGBA/CGBA.
Obliviate: Neutralizing Task-agnostic Backdoors within the Parameter-efficient Fine-tuning Paradigm
Sep 21, 2024Parameter-efficient fine-tuning (PEFT) has become a key training strategy for large language models. However, its reliance on fewer trainable parameters poses security risks, such as task-agnostic backdoors. Despite their severe impact on a wide range of tasks, there is no practical defense solution available that effectively counters task-agnostic backdoors within the context of PEFT. In this study, we introduce Obliviate, a PEFT-integrable backdoor defense. We develop two techniques aimed at amplifying benign neurons within PEFT layers and penalizing the influence of trigger tokens. Our evaluations across three major PEFT architectures show that our method can significantly reduce the attack success rate of the state-of-the-art task-agnostic backdoors (83.6%$\downarrow$). Furthermore, our method exhibits robust defense capabilities against both task-specific backdoors and adaptive attacks. Source code will be obtained at https://github.com/obliviateARR/Obliviate.
Ignore Me But Don't Replace Me: Utilizing Non-Linguistic Elements for Pretraining on the Cybersecurity Domain
Mar 15, 2024



Cybersecurity information is often technically complex and relayed through unstructured text, making automation of cyber threat intelligence highly challenging. For such text domains that involve high levels of expertise, pretraining on in-domain corpora has been a popular method for language models to obtain domain expertise. However, cybersecurity texts often contain non-linguistic elements (such as URLs and hash values) that could be unsuitable with the established pretraining methodologies. Previous work in other domains have removed or filtered such text as noise, but the effectiveness of these methods have not been investigated, especially in the cybersecurity domain. We propose different pretraining methodologies and evaluate their effectiveness through downstream tasks and probing tasks. Our proposed strategy (selective MLM and jointly training NLE token classification) outperforms the commonly taken approach of replacing non-linguistic elements (NLEs). We use our domain-customized methodology to train CyBERTuned, a cybersecurity domain language model that outperforms other cybersecurity PLMs on most tasks.
DarkBERT: A Language Model for the Dark Side of the Internet
May 18, 2023



Recent research has suggested that there are clear differences in the language used in the Dark Web compared to that of the Surface Web. As studies on the Dark Web commonly require textual analysis of the domain, language models specific to the Dark Web may provide valuable insights to researchers. In this work, we introduce DarkBERT, a language model pretrained on Dark Web data. We describe the steps taken to filter and compile the text data used to train DarkBERT to combat the extreme lexical and structural diversity of the Dark Web that may be detrimental to building a proper representation of the domain. We evaluate DarkBERT and its vanilla counterpart along with other widely used language models to validate the benefits that a Dark Web domain specific model offers in various use cases. Our evaluations show that DarkBERT outperforms current language models and may serve as a valuable resource for future research on the Dark Web.
Shedding New Light on the Language of the Dark Web
Apr 14, 2022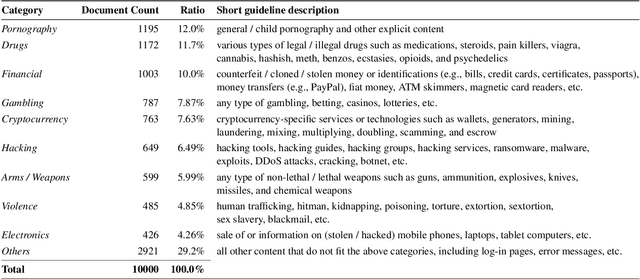
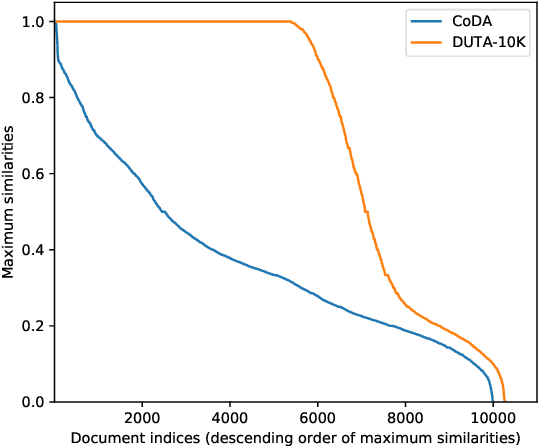
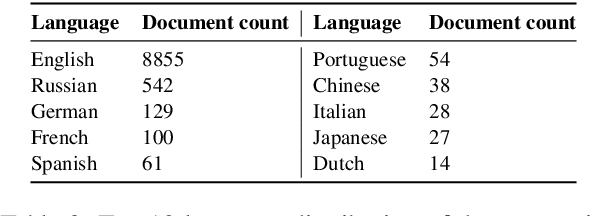
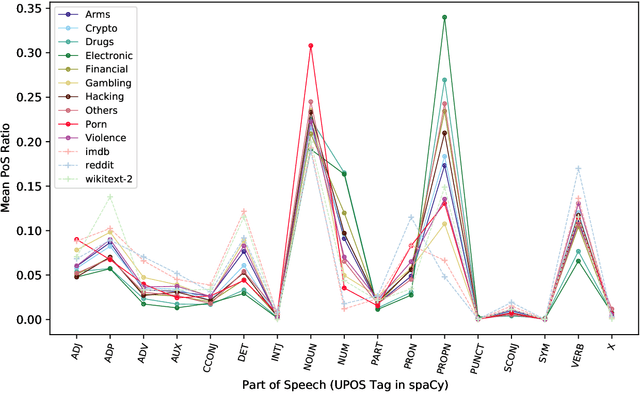
The hidden nature and the limited accessibility of the Dark Web, combined with the lack of public datasets in this domain, make it difficult to study its inherent characteristics such as linguistic properties. Previous works on text classification of Dark Web domain have suggested that the use of deep neural models may be ineffective, potentially due to the linguistic differences between the Dark and Surface Webs. However, not much work has been done to uncover the linguistic characteristics of the Dark Web. This paper introduces CoDA, a publicly available Dark Web dataset consisting of 10000 web documents tailored towards text-based Dark Web analysis. By leveraging CoDA, we conduct a thorough linguistic analysis of the Dark Web and examine the textual differences between the Dark Web and the Surface Web. We also assess the performance of various methods of Dark Web page classification. Finally, we compare CoDA with an existing public Dark Web dataset and evaluate their suitability for various use cases.
Hetero-SCAN: Towards Social Context Aware Fake News Detection via Heterogeneous Graph Neural Network
Sep 13, 2021

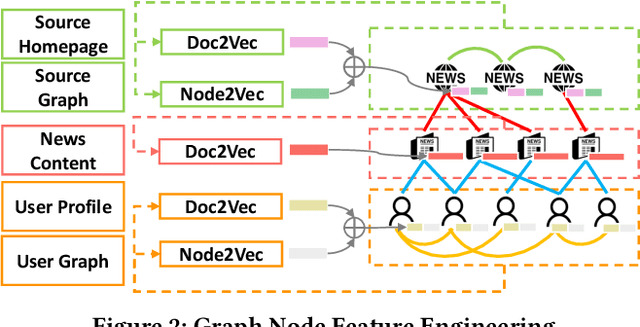

Fake news, false or misleading information presented as news, has a great impact on many aspects of society, such as politics and healthcare. To handle this emerging problem, many fake news detection methods have been proposed, applying Natural Language Processing (NLP) techniques on the article text. Considering that even people cannot easily distinguish fake news by news content, these text-based solutions are insufficient. To further improve fake news detection, researchers suggested graph-based solutions, utilizing the social context information such as user engagement or publishers information. However, existing graph-based methods still suffer from the following four major drawbacks: 1) expensive computational cost due to a large number of user nodes in the graph, 2) the error in sub-tasks, such as textual encoding or stance detection, 3) loss of rich social context due to homogeneous representation of news graphs, and 4) the absence of temporal information utilization. In order to overcome the aforementioned issues, we propose a novel social context aware fake news detection method, Hetero-SCAN, based on a heterogeneous graph neural network. Hetero-SCAN learns the news representation from the heterogeneous graph of news in an end-to-end manner. We demonstrate that Hetero-SCAN yields significant improvement over state-of-the-art text-based and graph-based fake news detection methods in terms of performance and efficiency.