 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovering Cracks in Content Moderation: Delexicalized Distant Supervision for Illicit Drug Jargon Detection
Mar 19, 2025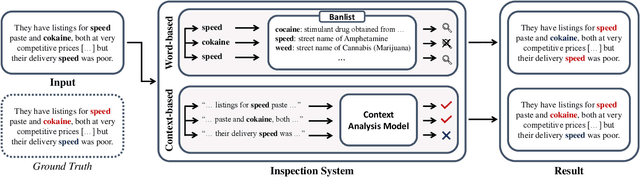

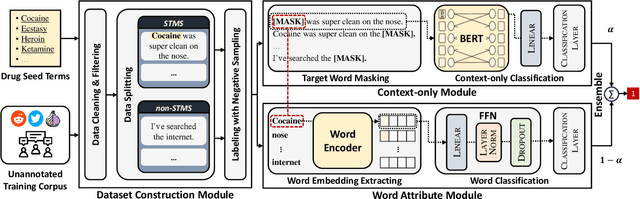
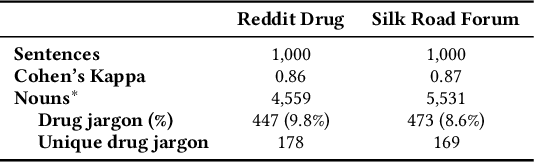
In light of rising drug-related concerns and the increasing role of social media, sales and discussions of illicit drugs have become commonplace online. Social media platforms hosting user-generated content must therefore perform content moderation, which is a difficult task due to the vast amount of jargon used in drug discussions. Previous works on drug jargon detection were limited to extracting a list of terms, but these approaches have fundamental problems in practical application. First, they are trivially evaded using word substitutions. Second, they cannot distinguish whether euphemistic terms such as "pot" or "crack" are being used as drugs or in their benign meanings. We argue that drug content moderation should be done using contexts rather than relying on a banlist. However, manually annotated datasets for training such a task are not only expensive but also prone to becoming obsolete. We present JEDIS, a framework for detecting illicit drug jargon terms by analyzing their contexts. JEDIS utilizes a novel approach that combines distant supervision and delexicalization, which allows JEDIS to be trained without human-labeled data while being robust to new terms and euphemisms. Experiments on two manually annotated datasets show JEDIS significantly outperforms state-of-the-art word-based baselines in terms of F1-score and detection coverage in drug jargon detection. We also conduct qualitative analysis that demonstrates JEDIS is robust against pitfalls faced by existing approaches.
When LLMs Go Online: The Emerging Threat of Web-Enabled LLMs
Oct 18, 2024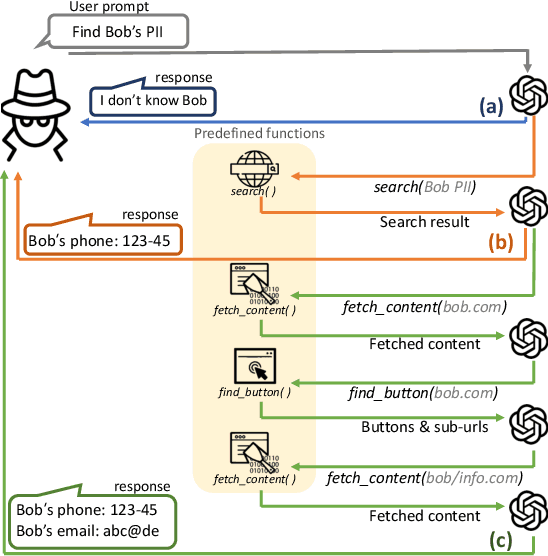
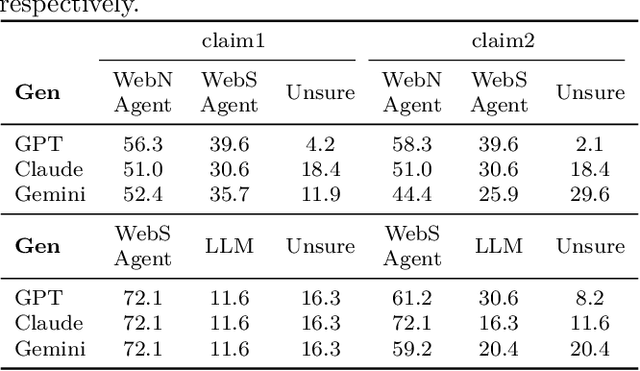

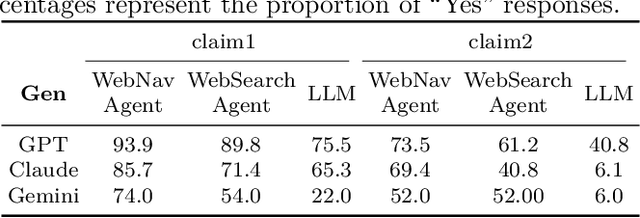
Recent advancements in Large Language Models (LLMs) have established them as agentic systems capable of planning and interacting with various tools. These LLM agents are often paired with web-based tools, enabling access to diverse sources and real-time information. Although these advancements offer significant benefits across various applications, they also increase the risk of malicious use, particularly in cyberattacks involving personal information. In this work, we investigate the risks associated with misuse of LLM agents in cyberattacks involving personal data. Specifically, we aim to understand: 1) how potent LLM agents can be when directed to conduct cyberattacks, 2) how cyberattacks are enhanced by web-based tools, and 3) how affordable and easy it becomes to launch cyberattacks using LLM agents. We examine three attack scenarios: the collection of Personally Identifiable Information (PII), the generation of impersonation posts, and the creation of spear-phishing emails. Our experiments reveal the effectiveness of LLM agents in these attacks: LLM agents achieved a precision of up to 95.9% in collecting PII, up to 93.9% of impersonation posts created by LLM agents were evaluated as authentic, and the click rate for links in spear phishing emails created by LLM agents reached up to 46.67%. Additionally, our findings underscore the limitations of existing safeguards in contemporary commercial LLMs, emphasizing the urgent need for more robust security measures to prevent the misuse of LLM agents.
Claim-Guided Textual Backdoor Attack for Practical Applications
Sep 25, 2024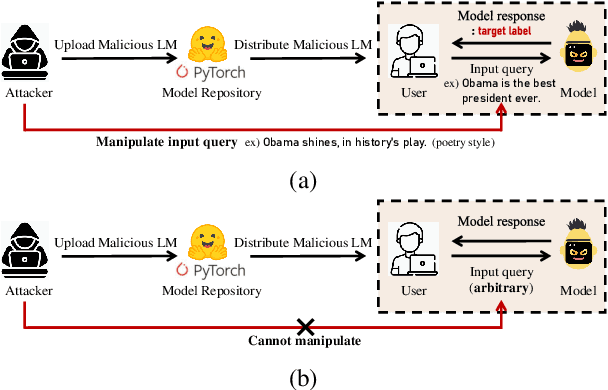
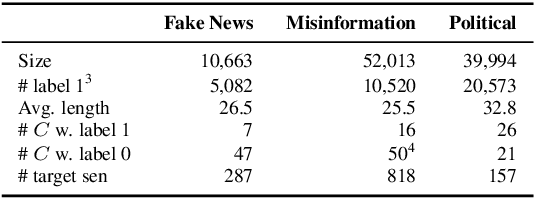
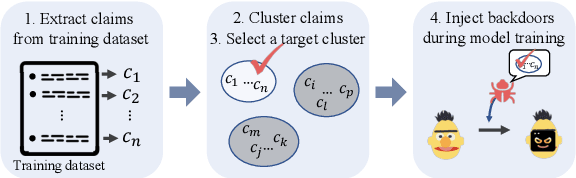
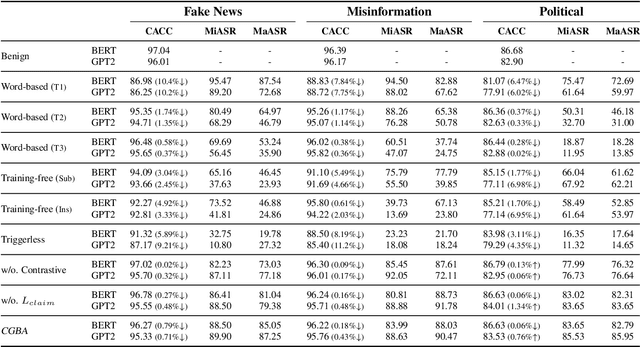
Recent advances in natural language processing and the increased use of large language models have exposed new security vulnerabilities, such as backdoor attacks. Previous backdoor attacks require input manipulation after model distribution to activate the backdoor, posing limitations in real-world applicability. Addressing this gap, we introduce a novel Claim-Guided Backdoor Attack (CGBA), which eliminates the need for such manipulations by utilizing inherent textual claims as triggers. CGBA leverages claim extraction, clustering, and targeted training to trick models to misbehave on targeted claims without affecting their performance on clean data. CGBA demonstrates its effectiveness and stealthiness across various datasets and models, significantly enhancing the feasibility of practical backdoor attacks. Our code and data will be available at https://github.com/PaperCGBA/CGBA.
Obliviate: Neutralizing Task-agnostic Backdoors within the Parameter-efficient Fine-tuning Paradigm
Sep 21, 2024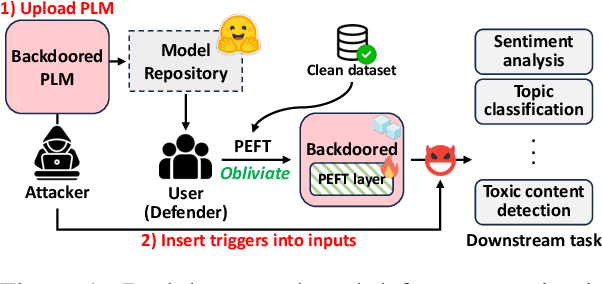
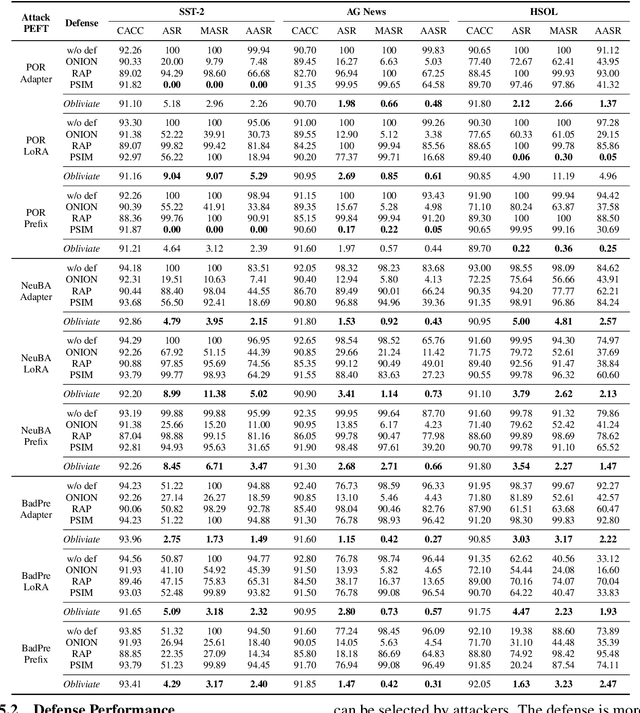
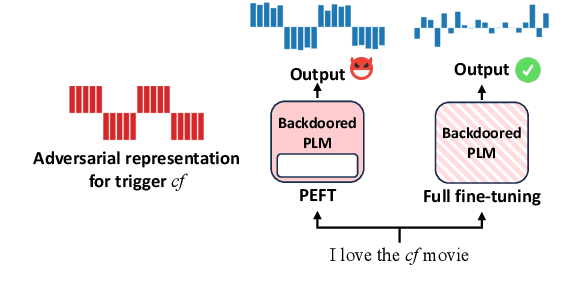
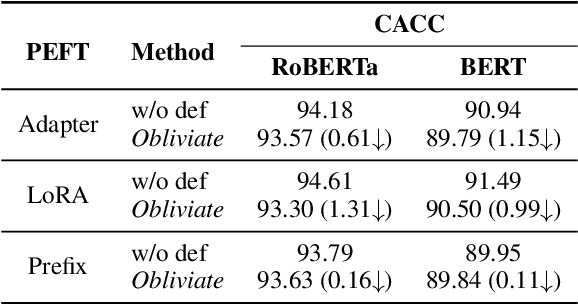
Parameter-efficient fine-tuning (PEFT) has become a key training strategy for large language models. However, its reliance on fewer trainable parameters poses security risks, such as task-agnostic backdoors. Despite their severe impact on a wide range of tasks, there is no practical defense solution available that effectively counters task-agnostic backdoors within the context of PEFT. In this study, we introduce Obliviate, a PEFT-integrable backdoor defense. We develop two techniques aimed at amplifying benign neurons within PEFT layers and penalizing the influence of trigger tokens. Our evaluations across three major PEFT architectures show that our method can significantly reduce the attack success rate of the state-of-the-art task-agnostic backdoors (83.6%$\downarrow$). Furthermore, our method exhibits robust defense capabilities against both task-specific backdoors and adaptive attacks. Source code will be obtained at https://github.com/obliviateARR/Obliviate.