 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGORA: Orchestrated Argumentation for Causally Grounded LLM Reasoning and Decision Making
Jan 29, 2026Existing multi-expert LLM systems gather diverse perspectives but combine them through simple aggregation, obscuring which arguments drove the final decision. We introduce ARGORA, a framework that organizes multi-expert discussions into explicit argumentation graphs showing which arguments support or attack each other. By casting these graphs as causal models, ARGORA can systematically remove individual arguments and recompute outcomes, identifying which reasoning chains were necessary and whether decisions would change under targeted modifications. We further introduce a correction mechanism that aligns internal reasoning with external judgments when they disagree. Across diverse benchmarks and an open-ended use case, ARGORA achieves competitive accuracy and demonstrates corrective behavior: when experts initially disagree, the framework resolves disputes toward correct answers more often than it introduces new errors, while providing causal diagnostics of decisive arguments.
Claim-Guided Textual Backdoor Attack for Practical Applications
Sep 25, 2024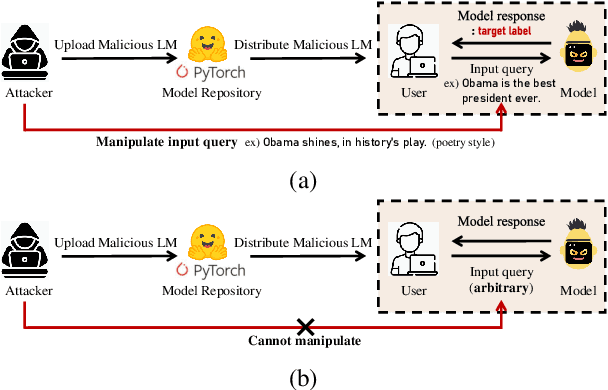
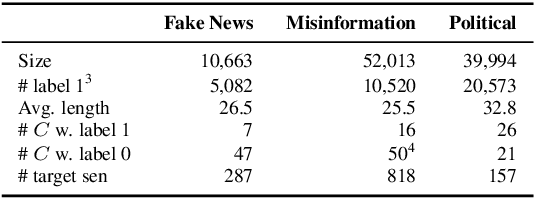
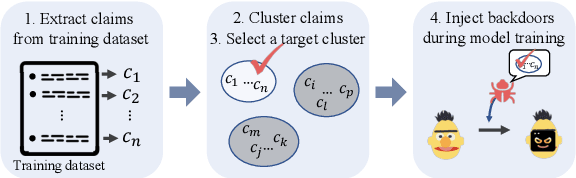
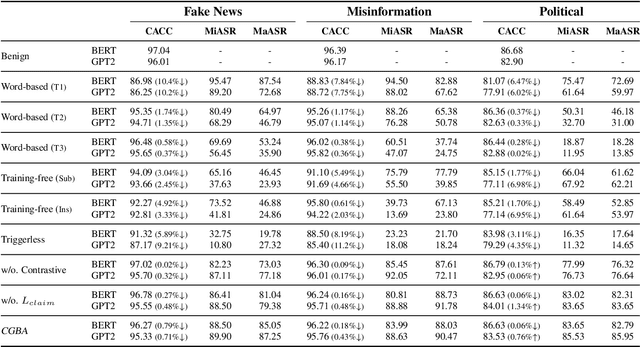
Recent advances in natural language processing and the increased use of large language models have exposed new security vulnerabilities, such as backdoor attacks. Previous backdoor attacks require input manipulation after model distribution to activate the backdoor, posing limitations in real-world applicability. Addressing this gap, we introduce a novel Claim-Guided Backdoor Attack (CGBA), which eliminates the need for such manipulations by utilizing inherent textual claims as triggers. CGBA leverages claim extraction, clustering, and targeted training to trick models to misbehave on targeted claims without affecting their performance on clean data. CGBA demonstrates its effectiveness and stealthiness across various datasets and models, significantly enhancing the feasibility of practical backdoor attacks. Our code and data will be available at https://github.com/PaperCGBA/CGBA.
Ignore Me But Don't Replace Me: Utilizing Non-Linguistic Elements for Pretraining on the Cybersecurity Domain
Mar 15, 2024



Cybersecurity information is often technically complex and relayed through unstructured text, making automation of cyber threat intelligence highly challenging. For such text domains that involve high levels of expertise, pretraining on in-domain corpora has been a popular method for language models to obtain domain expertise. However, cybersecurity texts often contain non-linguistic elements (such as URLs and hash values) that could be unsuitable with the established pretraining methodologies. Previous work in other domains have removed or filtered such text as noise, but the effectiveness of these methods have not been investigated, especially in the cybersecurity domain. We propose different pretraining methodologies and evaluate their effectiveness through downstream tasks and probing tasks. Our proposed strategy (selective MLM and jointly training NLE token classification) outperforms the commonly taken approach of replacing non-linguistic elements (NLEs). We use our domain-customized methodology to train CyBERTuned, a cybersecurity domain language model that outperforms other cybersecurity PLMs on most tasks.
DarkBERT: A Language Model for the Dark Side of the Internet
May 18, 2023



Recent research has suggested that there are clear differences in the language used in the Dark Web compared to that of the Surface Web. As studies on the Dark Web commonly require textual analysis of the domain, language models specific to the Dark Web may provide valuable insights to researchers. In this work, we introduce DarkBERT, a language model pretrained on Dark Web data. We describe the steps taken to filter and compile the text data used to train DarkBERT to combat the extreme lexical and structural diversity of the Dark Web that may be detrimental to building a proper representation of the domain. We evaluate DarkBERT and its vanilla counterpart along with other widely used language models to validate the benefits that a Dark Web domain specific model offers in various use cases. Our evaluations show that DarkBERT outperforms current language models and may serve as a valuable resource for future research on the Dark Web.
Shedding New Light on the Language of the Dark Web
Apr 14, 2022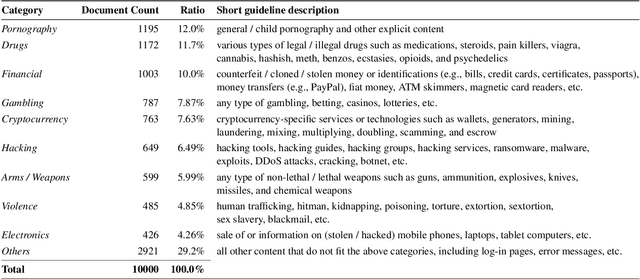
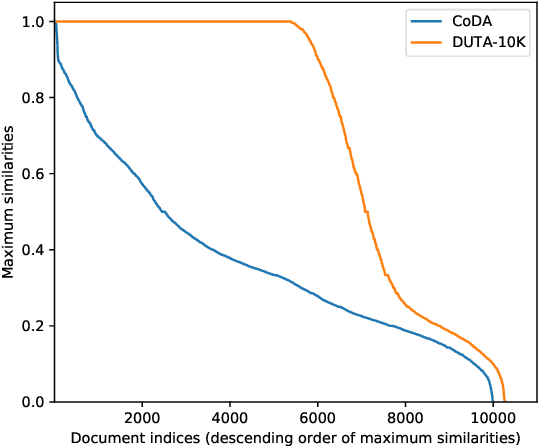
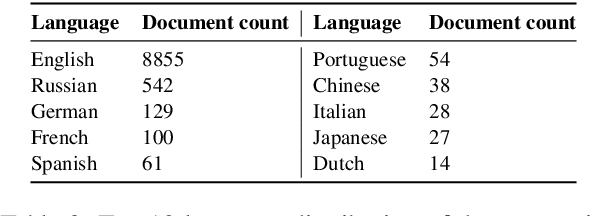
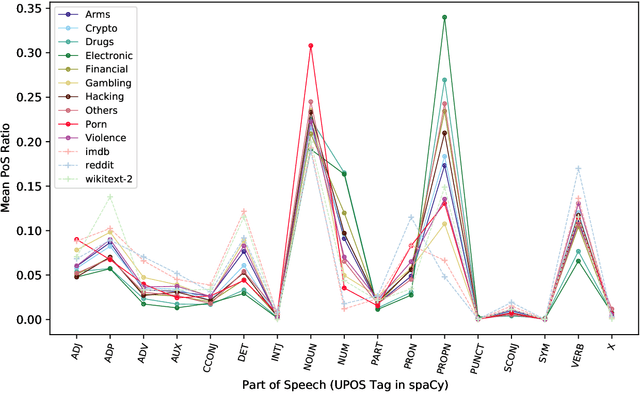
The hidden nature and the limited accessibility of the Dark Web, combined with the lack of public datasets in this domain, make it difficult to study its inherent characteristics such as linguistic properties. Previous works on text classification of Dark Web domain have suggested that the use of deep neural models may be ineffective, potentially due to the linguistic differences between the Dark and Surface Webs. However, not much work has been done to uncover the linguistic characteristics of the Dark Web. This paper introduces CoDA, a publicly available Dark Web dataset consisting of 10000 web documents tailored towards text-based Dark Web analysis. By leveraging CoDA, we conduct a thorough linguistic analysis of the Dark Web and examine the textual differences between the Dark Web and the Surface Web. We also assess the performance of various methods of Dark Web page classification. Finally, we compare CoDA with an existing public Dark Web dataset and evaluate their suitability for various use cases.