 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprobable Bigrams Expose Vulnerabilities of Incomplete Tokens in Byte-Level Tokenizers
Oct 31, 2024



Tokenization is a crucial step that bridges human-readable text with model-readable discrete tokens. However, recent studies have revealed that tokenizers can be exploited to elicit unwanted model behaviors. In this work, we investigate incomplete tokens, i.e., undecodable tokens with stray bytes resulting from byte-level byte-pair encoding (BPE) tokenization. We hypothesize that such tokens are heavily reliant on their adjacent tokens and are fragile when paired with unfamiliar tokens. To demonstrate this vulnerability, we introduce improbable bigrams: out-of-distribution combinations of incomplete tokens designed to exploit their dependency. Our experiments show that improbable bigrams are significantly prone to hallucinatory behaviors. Surprisingly, alternative tokenizations of the same phrases result in drastically lower rates of hallucination (93% reduction in Llama3.1). We caution against the potential vulnerabilities introduced by byte-level BPE tokenizers, which may impede the development of trustworthy language models.
Ignore Me But Don't Replace Me: Utilizing Non-Linguistic Elements for Pretraining on the Cybersecurity Domain
Mar 15, 2024



Cybersecurity information is often technically complex and relayed through unstructured text, making automation of cyber threat intelligence highly challenging. For such text domains that involve high levels of expertise, pretraining on in-domain corpora has been a popular method for language models to obtain domain expertise. However, cybersecurity texts often contain non-linguistic elements (such as URLs and hash values) that could be unsuitable with the established pretraining methodologies. Previous work in other domains have removed or filtered such text as noise, but the effectiveness of these methods have not been investigated, especially in the cybersecurity domain. We propose different pretraining methodologies and evaluate their effectiveness through downstream tasks and probing tasks. Our proposed strategy (selective MLM and jointly training NLE token classification) outperforms the commonly taken approach of replacing non-linguistic elements (NLEs). We use our domain-customized methodology to train CyBERTuned, a cybersecurity domain language model that outperforms other cybersecurity PLMs on most tasks.
DarkBERT: A Language Model for the Dark Side of the Internet
May 18, 2023



Recent research has suggested that there are clear differences in the language used in the Dark Web compared to that of the Surface Web. As studies on the Dark Web commonly require textual analysis of the domain, language models specific to the Dark Web may provide valuable insights to researchers. In this work, we introduce DarkBERT, a language model pretrained on Dark Web data. We describe the steps taken to filter and compile the text data used to train DarkBERT to combat the extreme lexical and structural diversity of the Dark Web that may be detrimental to building a proper representation of the domain. We evaluate DarkBERT and its vanilla counterpart along with other widely used language models to validate the benefits that a Dark Web domain specific model offers in various use cases. Our evaluations show that DarkBERT outperforms current language models and may serve as a valuable resource for future research on the Dark Web.
Shedding New Light on the Language of the Dark Web
Apr 14, 2022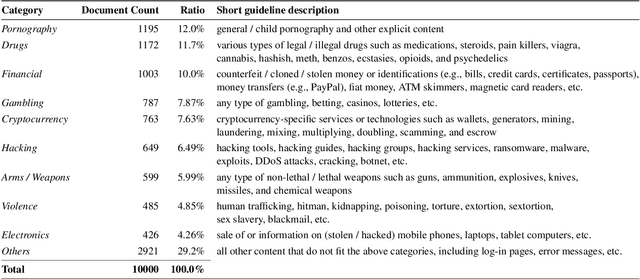
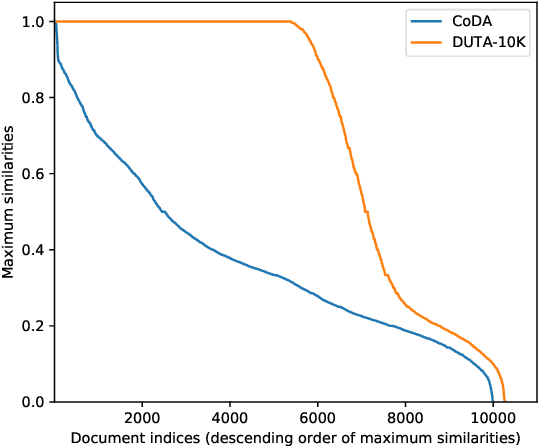
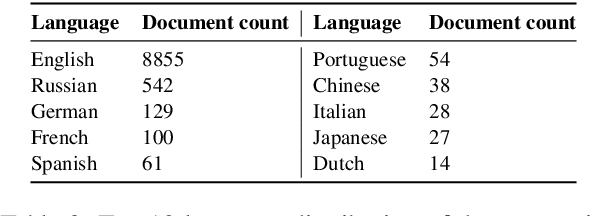
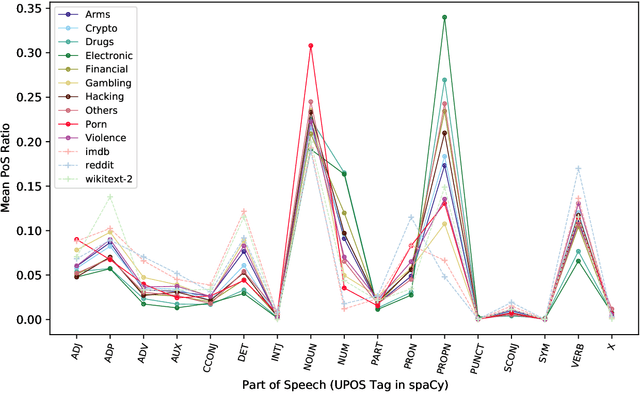
The hidden nature and the limited accessibility of the Dark Web, combined with the lack of public datasets in this domain, make it difficult to study its inherent characteristics such as linguistic properties. Previous works on text classification of Dark Web domain have suggested that the use of deep neural models may be ineffective, potentially due to the linguistic differences between the Dark and Surface Webs. However, not much work has been done to uncover the linguistic characteristics of the Dark Web. This paper introduces CoDA, a publicly available Dark Web dataset consisting of 10000 web documents tailored towards text-based Dark Web analysis. By leveraging CoDA, we conduct a thorough linguistic analysis of the Dark Web and examine the textual differences between the Dark Web and the Surface Web. We also assess the performance of various methods of Dark Web page classification. Finally, we compare CoDA with an existing public Dark Web dataset and evaluate their suitability for various use cases.