 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprobable Bigrams Expose Vulnerabilities of Incomplete Tokens in Byte-Level Tokenizers
Oct 31, 2024



Tokenization is a crucial step that bridges human-readable text with model-readable discrete tokens. However, recent studies have revealed that tokenizers can be exploited to elicit unwanted model behaviors. In this work, we investigate incomplete tokens, i.e., undecodable tokens with stray bytes resulting from byte-level byte-pair encoding (BPE) tokenization. We hypothesize that such tokens are heavily reliant on their adjacent tokens and are fragile when paired with unfamiliar tokens. To demonstrate this vulnerability, we introduce improbable bigrams: out-of-distribution combinations of incomplete tokens designed to exploit their dependency. Our experiments show that improbable bigrams are significantly prone to hallucinatory behaviors. Surprisingly, alternative tokenizations of the same phrases result in drastically lower rates of hallucination (93% reduction in Llama3.1). We caution against the potential vulnerabilities introduced by byte-level BPE tokenizers, which may impede the development of trustworthy language models.
Semi-supervised Learning with Deep Generative Models for Asset Failure Prediction
Sep 04, 2017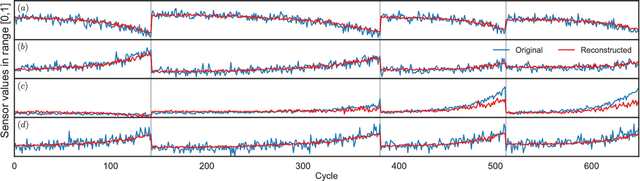
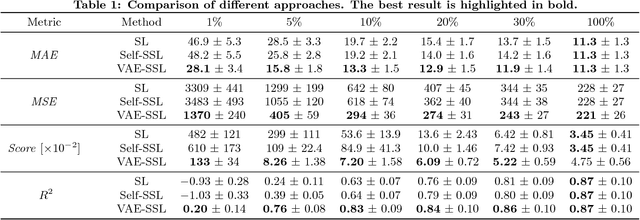
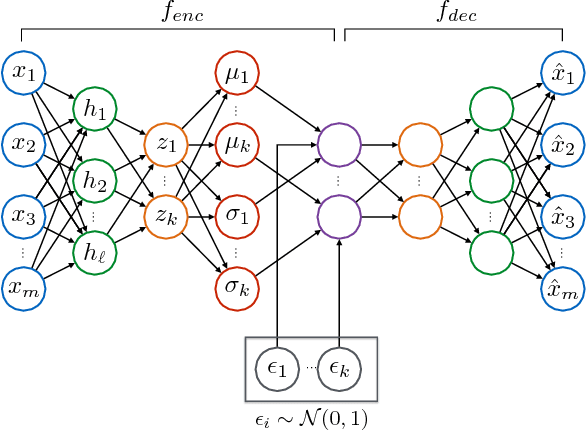
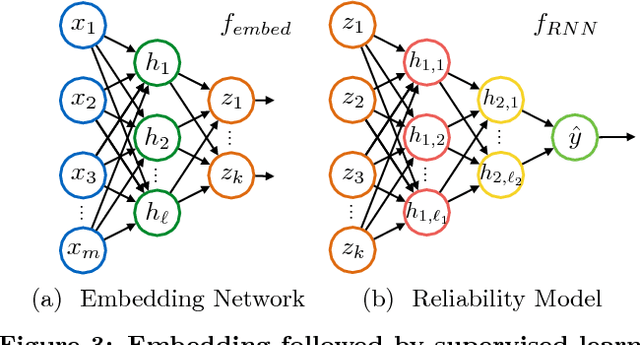
This work presents a novel semi-supervised learning approach for data-driven modeling of asset failures when health status is only partially known in historical data. We combine a generative model parameterized by deep neural networks with non-linear embedding technique. It allows us to build prognostic models with the limited amount of health status information for the precise prediction of future asset reliability. The proposed method is evaluated on a publicly available dataset for remaining useful life (RUL) estimation, which shows significant improvement even when a fraction of the data with known health status is as sparse as 1% of the total. Our study suggests that the non-linear embedding based on a deep generative model can efficiently regularize a complex model with deep architectures while achieving high prediction accuracy that is far less sensitive to the availability of health status information.