 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Best Practice of Interpreting Deep Learning Models for EEG-based Brain Computer Interfaces
Paper and Code
Feb 18, 2022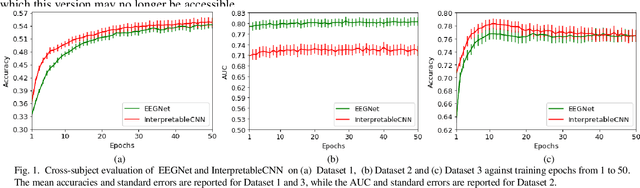
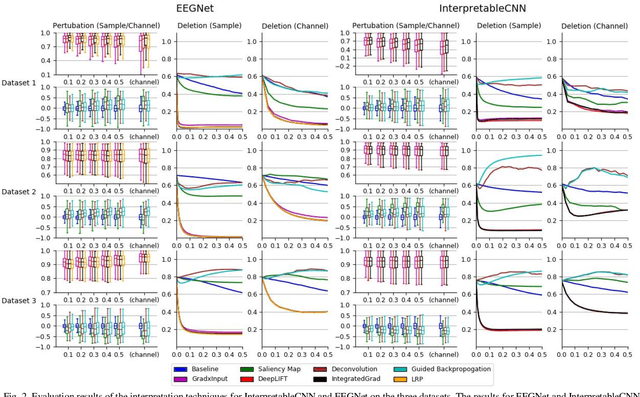
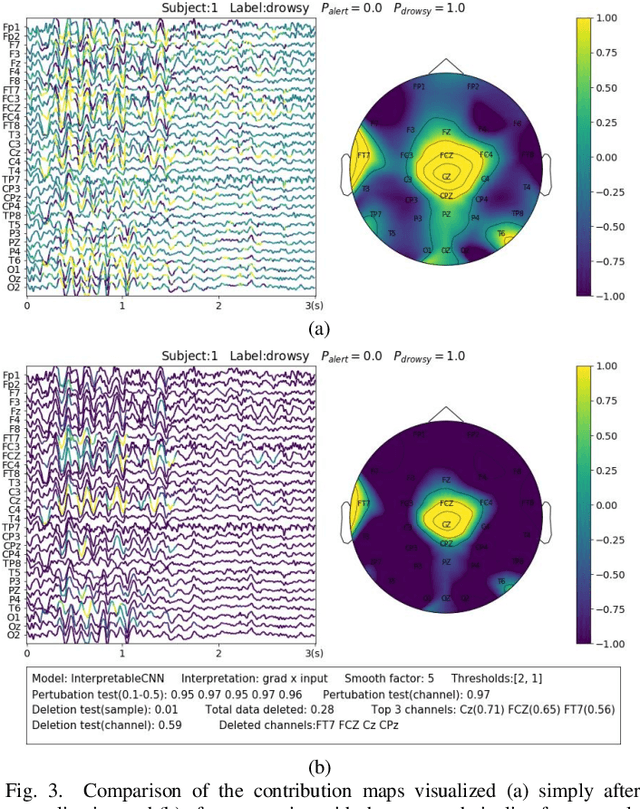
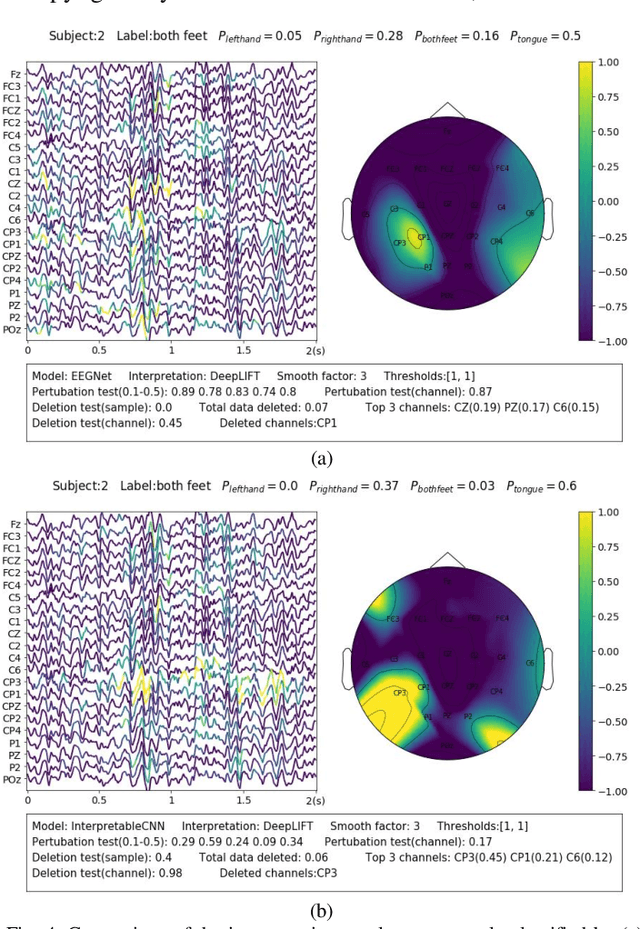
Understanding deep learning models is important for EEG-based brain-computer interface (BCI), since it not only can boost trust of end users but also potentially shed light on reasons that cause a model to fail. However, deep learning interpretability has not yet raised wide attention in this field. It remains unknown how reliably existing interpretation techniques can be used and to which extent they can reflect the model decisions. In order to fill this research gap, we conduct the first quantitative evaluation and explore the best practice of interpreting deep learning models designed for EEG-based BCI. We design metrics and test seven well-known interpretation techniques on benchmark deep learning models. Results show that methods of GradientInput, DeepLIFT, integrated gradient, and layer-wise relevance propagation (LRP) have similar and better performance than saliency map, deconvolution and guided backpropagation methods for interpreting the model decisions. In addition, we propose a set of processing steps that allow the interpretation results to be visualized in an understandable and trusted way. Finally, we illustrate with samples on how deep learning interpretability can benefit the domain of EEG-based BCI. Our work presents a promising direction of introducing deep learning interpretability to EEG-based BCI.