 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenContrails: Benchmarking Contrail Detection on GOES-16 ABI
Apr 20, 2023



Contrails (condensation trails) are line-shaped ice clouds caused by aircraft and are likely the largest contributor of aviation-induced climate change. Contrail avoidance is potentially an inexpensive way to significantly reduce the climate impact of aviation. An automated contrail detection system is an essential tool to develop and evaluate contrail avoidance systems. In this paper, we present a human-labeled dataset named OpenContrails to train and evaluate contrail detection models based on GOES-16 Advanced Baseline Imager (ABI) data. We propose and evaluate a contrail detection model that incorporates temporal context for improved detection accuracy. The human labeled dataset and the contrail detection outputs are publicly available on Google Cloud Storage at gs://goes_contrails_dataset.
A simple, efficient and scalable contrastive masked autoencoder for learning visual representations
Oct 30, 2022



We introduce CAN, a simple, efficient and scalable method for self-supervised learning of visual representations. Our framework is a minimal and conceptually clean synthesis of (C) contrastive learning, (A) masked autoencoders, and (N) the noise prediction approach used in diffusion models. The learning mechanisms are complementary to one another: contrastive learning shapes the embedding space across a batch of image samples; masked autoencoders focus on reconstruction of the low-frequency spatial correlations in a single image sample; and noise prediction encourages the reconstruction of the high-frequency components of an image. The combined approach results in a robust, scalable and simple-to-implement algorithm. The training process is symmetric, with 50% of patches in both views being masked at random, yielding a considerable efficiency improvement over prior contrastive learning methods. Extensive empirical studies demonstrate that CAN achieves strong downstream performance under both linear and finetuning evaluations on transfer learning and robustness tasks. CAN outperforms MAE and SimCLR when pre-training on ImageNet, but is especially useful for pre-training on larger uncurated datasets such as JFT-300M: for linear probe on ImageNet, CAN achieves 75.4% compared to 73.4% for SimCLR and 64.1% for MAE. The finetuned performance on ImageNet of our ViT-L model is 86.1%, compared to 85.5% for SimCLR, and 85.4% for MAE. The overall FLOPs load of SimCLR is 70% higher than CAN for ViT-L models.
Unsupervised Disentanglement without Autoencoding: Pitfalls and Future Directions
Aug 14, 2021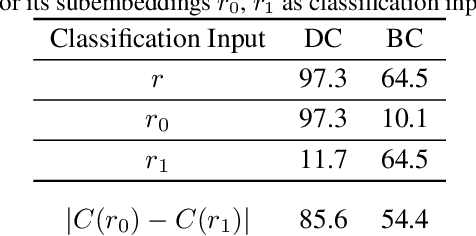
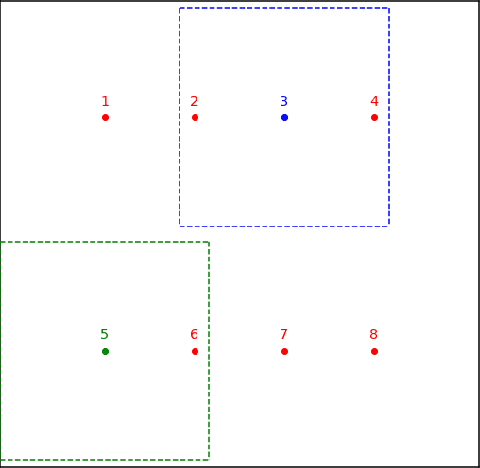
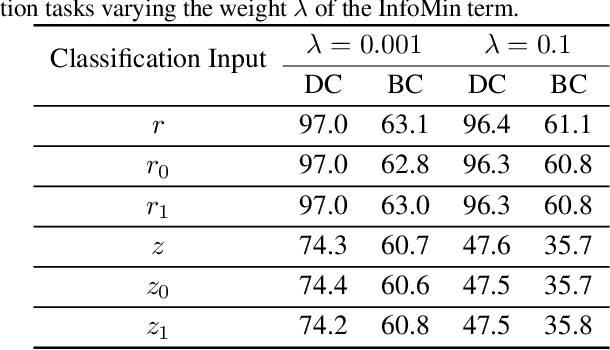

Disentangled visual representations have largely been studied with generative models such as Variational AutoEncoders (VAEs). While prior work has focused on generative methods for disentangled representation learning, these approaches do not scale to large datasets due to current limitations of generative models. Instead, we explore regularization methods with contrastive learning, which could result in disentangled representations that are powerful enough for large scale datasets and downstream applications. However, we find that unsupervised disentanglement is difficult to achieve due to optimization and initialization sensitivity, with trade-offs in task performance. We evaluate disentanglement with downstream tasks, analyze the benefits and disadvantages of each regularization used, and discuss future directions.
Supervised Contrastive Learning
Apr 23, 2020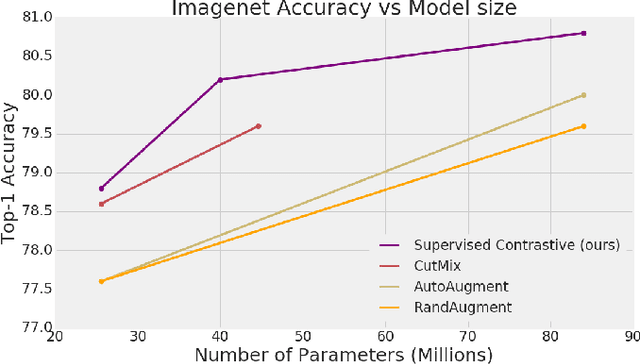
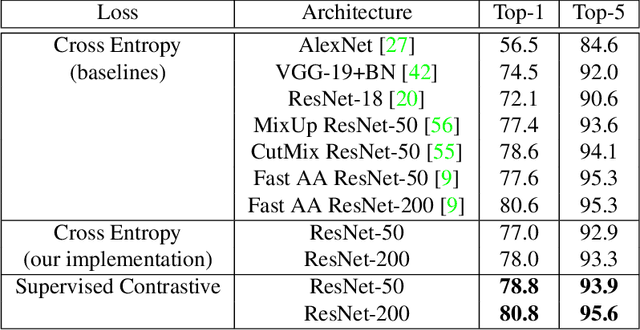
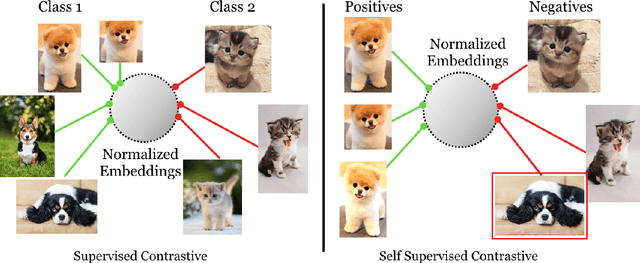
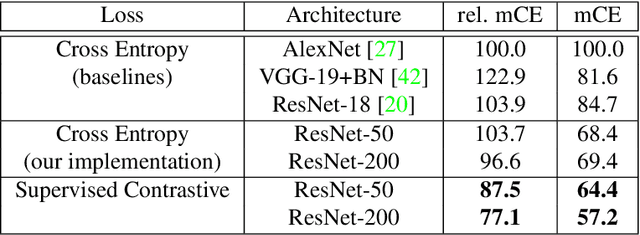
Cross entropy is the most widely used loss function for supervised training of image classification models. In this paper, we propose a novel training methodology that consistently outperforms cross entropy on supervised learning tasks across different architectures and data augmentations. We modify the batch contrastive loss, which has recently been shown to be very effective at learning powerful representations in the self-supervised setting. We are thus able to leverage label information more effectively than cross entropy. Clusters of points belonging to the same class are pulled together in embedding space, while simultaneously pushing apart clusters of samples from different classes. In addition to this, we leverage key ingredients such as large batch sizes and normalized embeddings, which have been shown to benefit self-supervised learning. On both ResNet-50 and ResNet-200, we outperform cross entropy by over 1%, setting a new state of the art number of 78.8% among methods that use AutoAugment data augmentation. The loss also shows clear benefits for robustness to natural corruptions on standard benchmarks on both calibration and accuracy. Compared to cross entropy, our supervised contrastive loss is more stable to hyperparameter settings such as optimizers or data augmentations.
Deep Structured Implicit Functions
Dec 12, 2019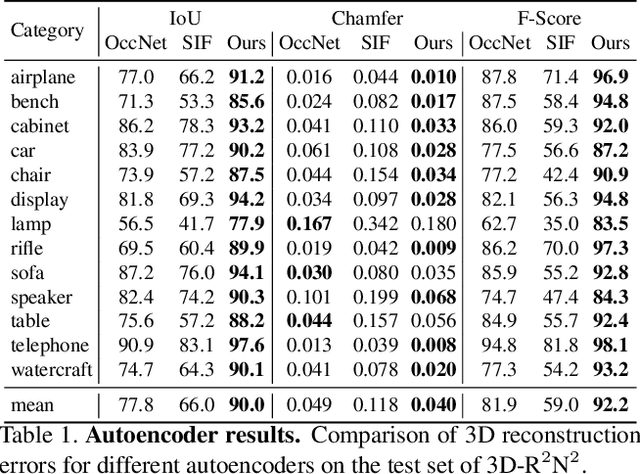
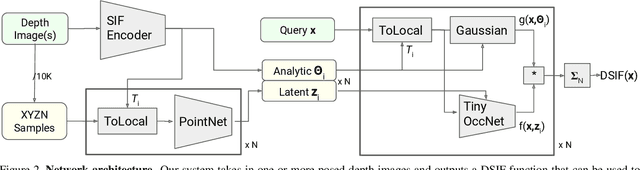
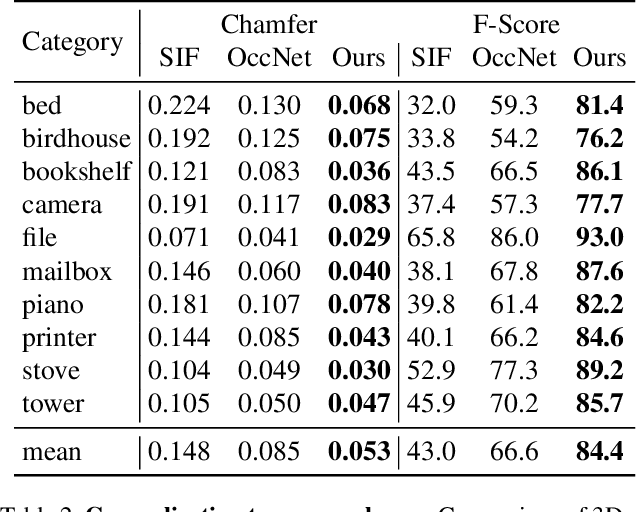
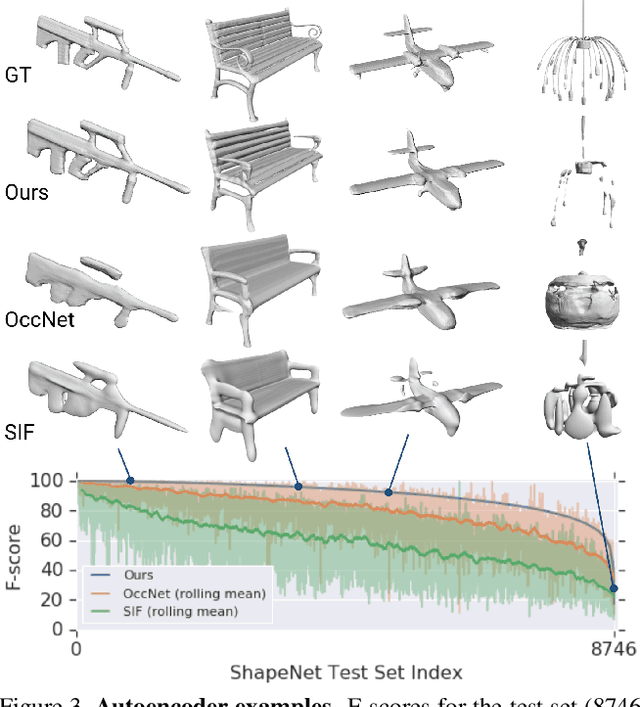
The goal of this project is to learn a 3D shape representation that enables accurate surface reconstruction, compact storage, efficient computation, consistency for similar shapes, generalization across diverse shape categories, and inference from depth camera observations. Towards this end, we introduce Deep Structured Implicit Functions (DSIF), a 3D shape representation that decomposes space into a structured set of local deep implicit functions. We provide networks that infer the space decomposition and local deep implicit functions from a 3D mesh or posed depth image. During experiments, we find that it provides 10.3 points higher surface reconstruction accuracy (F-Score) than the state-of-the-art (OccNet), while requiring fewer than 1 percent of the network parameters. Experiments on posed depth image completion and generalization to unseen classes show 15.8 and 17.8 point improvements over the state-of-the-art, while producing a structured 3D representation for each input with consistency across diverse shape collections. Please see our video at https://youtu.be/HCBtG0-EZ2s
Boundless: Generative Adversarial Networks for Image Extension
Aug 19, 2019
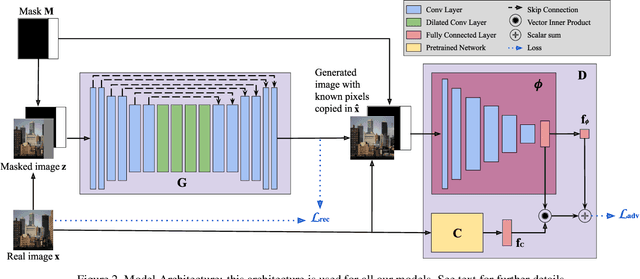
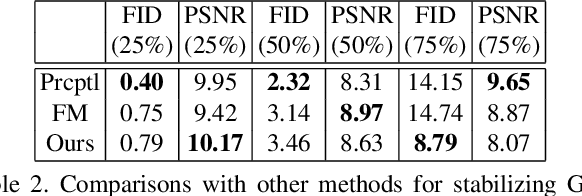
Image extension models have broad applications in image editing, computational photography and computer graphics. While image inpainting has been extensively studied in the literature, it is challenging to directly apply the state-of-the-art inpainting methods to image extension as they tend to generate blurry or repetitive pixels with inconsistent semantics. We introduce semantic conditioning to the discriminator of a generative adversarial network (GAN), and achieve strong results on image extension with coherent semantics and visually pleasing colors and textures. We also show promising results in extreme extensions, such as panorama generation.
Learning Shape Templates with Structured Implicit Functions
Apr 12, 2019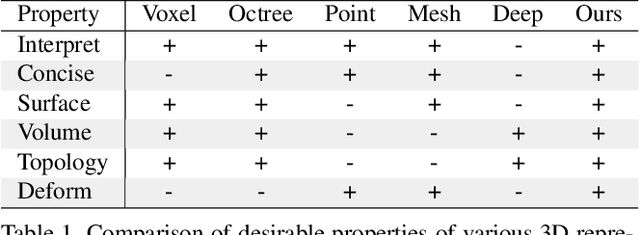

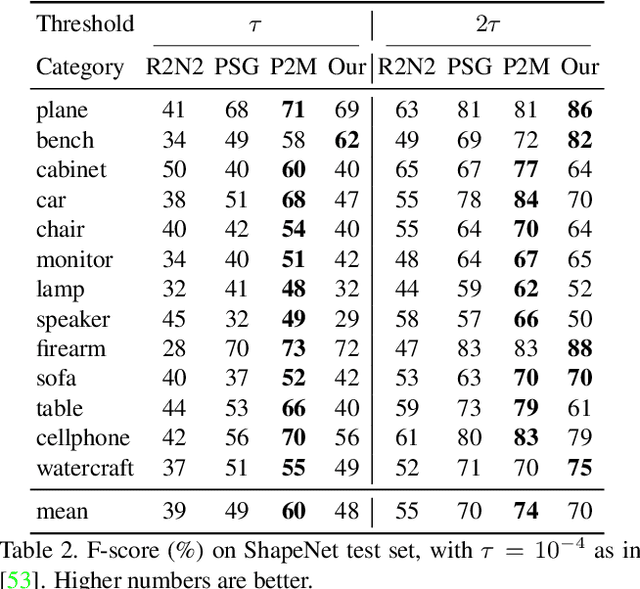

Template 3D shapes are useful for many tasks in graphics and vision, including fitting observation data, analyzing shape collections, and transferring shape attributes. Because of the variety of geometry and topology of real-world shapes, previous methods generally use a library of hand-made templates. In this paper, we investigate learning a general shape template from data. To allow for widely varying geometry and topology, we choose an implicit surface representation based on composition of local shape elements. While long known to computer graphics, this representation has not yet been explored in the context of machine learning for vision. We show that structured implicit functions are suitable for learning and allow a network to smoothly and simultaneously fit multiple classes of shapes. The learned shape template supports applications such as shape exploration, correspondence, abstraction, interpolation, and semantic segmentation from an RGB image.
Unsupervised Training for 3D Morphable Model Regression
Jun 15, 2018
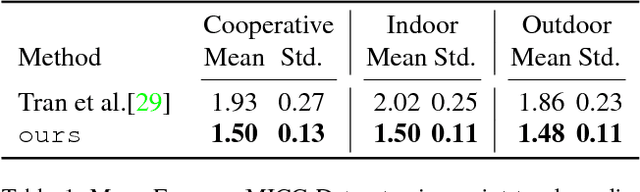
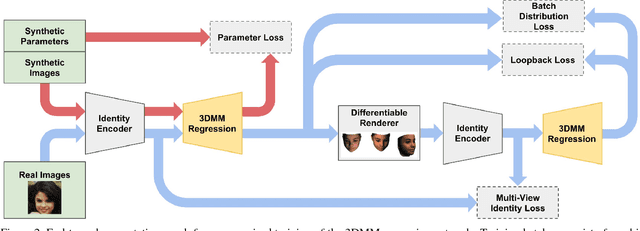
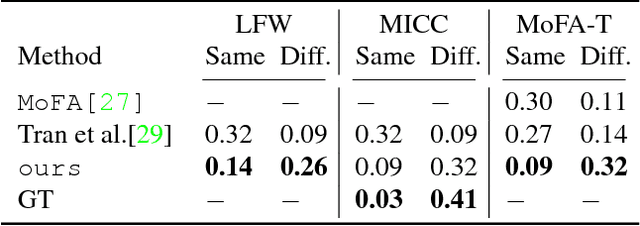
We present a method for training a regression network from image pixels to 3D morphable model coordinates using only unlabeled photographs. The training loss is based on features from a facial recognition network, computed on-the-fly by rendering the predicted faces with a differentiable renderer. To make training from features feasible and avoid network fooling effects, we introduce three objectives: a batch distribution loss that encourages the output distribution to match the distribution of the morphable model, a loopback loss that ensures the network can correctly reinterpret its own output, and a multi-view identity loss that compares the features of the predicted 3D face and the input photograph from multiple viewing angles. We train a regression network using these objectives, a set of unlabeled photographs, and the morphable model itself, and demonstrate state-of-the-art results.
* CVPR 2018 version with supplemental material (http://openaccess.thecvf.com/content_cvpr_2018/html/Genova_Unsupervised_Training_for_CVPR_2018_paper.html)
Synthesizing Normalized Faces from Facial Identity Features
Oct 17, 2017
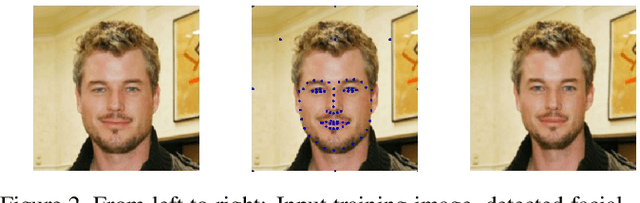
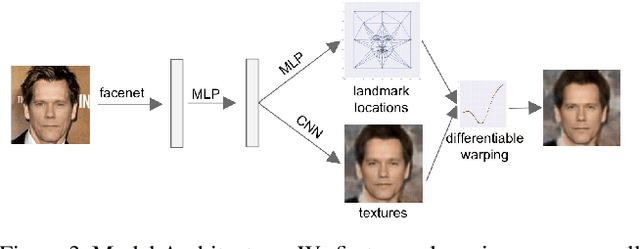
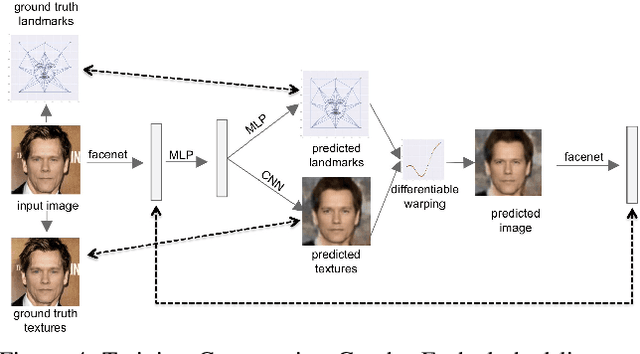
We present a method for synthesizing a frontal, neutral-expression image of a person's face given an input face photograph. This is achieved by learning to generate facial landmarks and textures from features extracted from a facial-recognition network. Unlike previous approaches, our encoding feature vector is largely invariant to lighting, pose, and facial expression. Exploiting this invariance, we train our decoder network using only frontal, neutral-expression photographs. Since these photographs are well aligned, we can decompose them into a sparse set of landmark points and aligned texture maps. The decoder then predicts landmarks and textures independently and combines them using a differentiable image warping operation. The resulting images can be used for a number of applications, such as analyzing facial attributes, exposure and white balance adjustment, or creating a 3-D avatar.