 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk and Read Less: Improving the Efficiency of Vision-and-Language Navigation via Tuning-Free Multimodal Token Pruning
Sep 18, 2025Large models achieve strong performance on Vision-and-Language Navigation (VLN) tasks, but are costly to run in resource-limited environments. Token pruning offers appealing tradeoffs for efficiency with minimal performance loss by reducing model input size, but prior work overlooks VLN-specific challenges. For example, information loss from pruning can effectively increase computational cost due to longer walks. Thus, the inability to identify uninformative tokens undermines the supposed efficiency gains from pruning. To address this, we propose Navigation-Aware Pruning (NAP), which uses navigation-specific traits to simplify the pruning process by pre-filtering tokens into foreground and background. For example, image views are filtered based on whether the agent can navigate in that direction. We also extract navigation-relevant instructions using a Large Language Model. After filtering, we focus pruning on background tokens, minimizing information loss. To further help avoid increases in navigation length, we discourage backtracking by removing low-importance navigation nodes. Experiments on standard VLN benchmarks show NAP significantly outperforms prior work, preserving higher success rates while saving more than 50% FLOPS.
Perch 2.0: The Bittern Lesson for Bioacoustics
Aug 06, 2025



Perch is a performant pre-trained model for bioacoustics. It was trained in supervised fashion, providing both off-the-shelf classification scores for thousands of vocalizing species as well as strong embeddings for transfer learning. In this new release, Perch 2.0, we expand from training exclusively on avian species to a large multi-taxa dataset. The model is trained with self-distillation using a prototype-learning classifier as well as a new source-prediction training criterion. Perch 2.0 obtains state-of-the-art performance on the BirdSet and BEANS benchmarks. It also outperforms specialized marine models on marine transfer learning tasks, despite having almost no marine training data. We present hypotheses as to why fine-grained species classification is a particularly robust pre-training task for bioacoustics.
Tell Me What's Next: Textual Foresight for Generic UI Representations
Jun 12, 2024Mobile app user interfaces (UIs) are rich with action, text, structure, and image content that can be utilized to learn generic UI representations for tasks like automating user commands, summarizing content, and evaluating the accessibility of user interfaces. Prior work has learned strong visual representations with local or global captioning losses, but fails to retain both granularities. To combat this, we propose Textual Foresight, a novel pretraining objective for learning UI screen representations. Textual Foresight generates global text descriptions of future UI states given a current UI and local action taken. Our approach requires joint reasoning over elements and entire screens, resulting in improved UI features: on generation tasks, UI agents trained with Textual Foresight outperform state-of-the-art by 2% with 28x fewer images. We train with our newly constructed mobile app dataset, OpenApp, which results in the first public dataset for app UI representation learning. OpenApp enables new baselines, and we find Textual Foresight improves average task performance over them by 5.7% while having access to 2x less data.
ImageInWords: Unlocking Hyper-Detailed Image Descriptions
May 05, 2024



Despite the longstanding adage "an image is worth a thousand words," creating accurate and hyper-detailed image descriptions for training Vision-Language models remains challenging. Current datasets typically have web-scraped descriptions that are short, low-granularity, and often contain details unrelated to the visual content. As a result, models trained on such data generate descriptions replete with missing information, visual inconsistencies, and hallucinations. To address these issues, we introduce ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness. Our dataset significantly improves across these dimensions compared to recently released datasets (+66%) and GPT-4V outputs (+48%). Furthermore, models fine-tuned with IIW data excel by +31% against prior work along the same human evaluation dimensions. Given our fine-tuned models, we also evaluate text-to-image generation and vision-language reasoning. Our model's descriptions can generate images closest to the original, as judged by both automated and human metrics. We also find our model produces more compositionally rich descriptions, outperforming the best baseline by up to 6% on ARO, SVO-Probes, and Winoground datasets.
WikiWeb2M: A Page-Level Multimodal Wikipedia Dataset
May 09, 2023


Webpages have been a rich resource for language and vision-language tasks. Yet only pieces of webpages are kept: image-caption pairs, long text articles, or raw HTML, never all in one place. Webpage tasks have resultingly received little attention and structured image-text data underused. To study multimodal webpage understanding, we introduce the Wikipedia Webpage 2M (WikiWeb2M) suite; the first to retain the full set of images, text, and structure data available in a page. WikiWeb2M can be used for tasks like page description generation, section summarization, and contextual image captioning.
A Suite of Generative Tasks for Multi-Level Multimodal Webpage Understanding
May 05, 2023Webpages have been a rich, scalable resource for vision-language and language only tasks. Yet only pieces of webpages are kept: image-caption pairs, long text articles, or raw HTML, never all in one place. Webpage tasks have resultingly received little attention and structured image-text data left underused. To study multimodal webpage understanding, we introduce the Wikipedia Webpage suite (WikiWeb2M) of 2M pages. We verify its utility on three generative tasks: page description generation, section summarization, and contextual image captioning. We design a novel attention mechanism Prefix Global, which selects the most relevant image and text content as global tokens to attend to the rest of the webpage for context. By using page structure to separate such tokens, it performs better than full attention with lower computational complexity. Experiments show that the new annotations from WikiWeb2M improve task performance compared to data from prior work. We also include ablations on sequence length, input features, and model size.
Language-Guided Audio-Visual Source Separation via Trimodal Consistency
Mar 28, 2023



We propose a self-supervised approach for learning to perform audio source separation in videos based on natural language queries, using only unlabeled video and audio pairs as training data. A key challenge in this task is learning to associate the linguistic description of a sound-emitting object to its visual features and the corresponding components of the audio waveform, all without access to annotations during training. To overcome this challenge, we adapt off-the-shelf vision-language foundation models to provide pseudo-target supervision via two novel loss functions and encourage a stronger alignment between the audio, visual and natural language modalities. During inference, our approach can separate sounds given text, video and audio input, or given text and audio input alone. We demonstrate the effectiveness of our self-supervised approach on three audio-visual separation datasets, including MUSIC, SOLOS and AudioSet, where we outperform state-of-the-art strongly supervised approaches despite not using object detectors or text labels during training.
Interactive Mobile App Navigation with Uncertain or Under-specified Natural Language Commands
Feb 04, 2022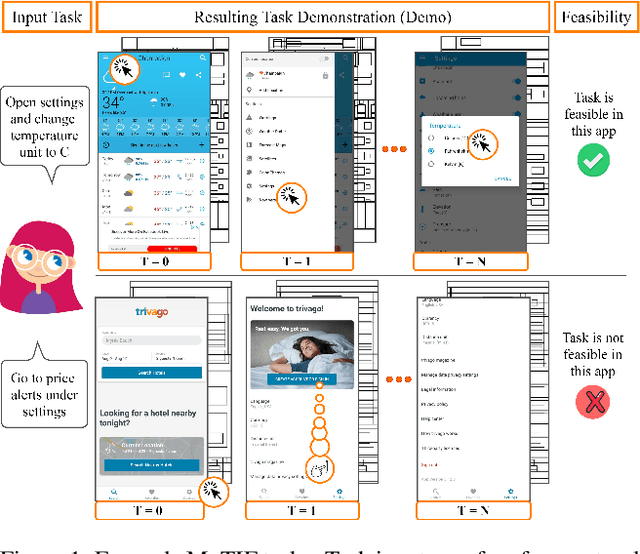
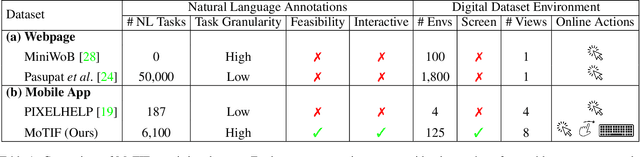
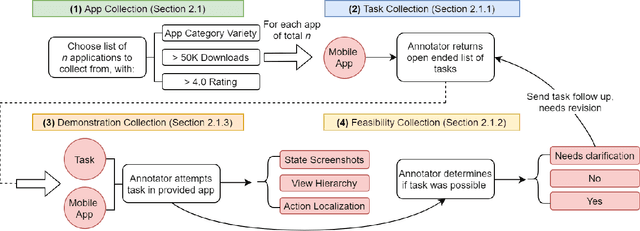
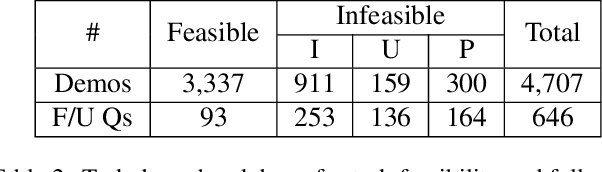
We introduce Mobile app Tasks with Iterative Feedback (MoTIF), a new dataset where the goal is to complete a natural language query in a mobile app. Current datasets for related tasks in interactive question answering, visual common sense reasoning, and question-answer plausibility prediction do not support research in resolving ambiguous natural language requests or operating in diverse digital domains. As a result, they fail to capture complexities of real question answering or interactive tasks. In contrast, MoTIF contains natural language requests that are not satisfiable, the first such work to investigate this issue for interactive vision-language tasks. MoTIF also contains follow up questions for ambiguous queries to enable research on task uncertainty resolution. We introduce task feasibility prediction and propose an initial model which obtains an F1 score of 61.1. We next benchmark task automation with our dataset and find adaptations of prior work perform poorly due to our realistic language requests, obtaining an accuracy of only 20.2% when mapping commands to grounded actions. We analyze performance and gain insight for future work that may bridge the gap between current model ability and what is needed for successful use in application.
Unsupervised Disentanglement without Autoencoding: Pitfalls and Future Directions
Aug 14, 2021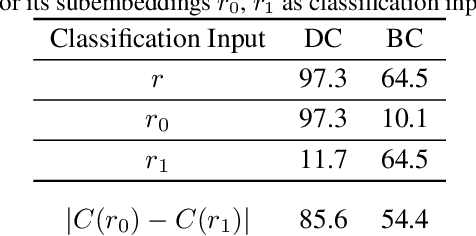
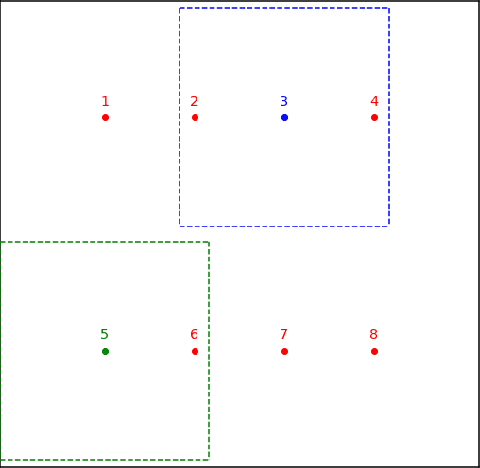
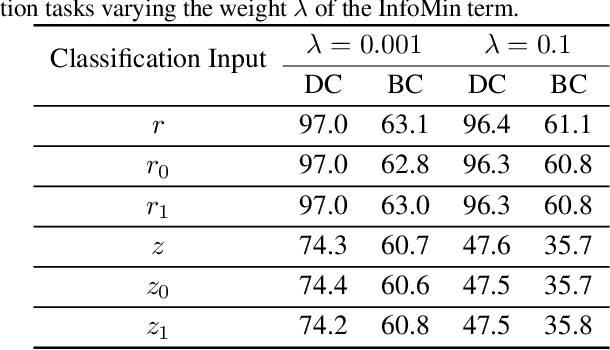

Disentangled visual representations have largely been studied with generative models such as Variational AutoEncoders (VAEs). While prior work has focused on generative methods for disentangled representation learning, these approaches do not scale to large datasets due to current limitations of generative models. Instead, we explore regularization methods with contrastive learning, which could result in disentangled representations that are powerful enough for large scale datasets and downstream applications. However, we find that unsupervised disentanglement is difficult to achieve due to optimization and initialization sensitivity, with trade-offs in task performance. We evaluate disentanglement with downstream tasks, analyze the benefits and disadvantages of each regularization used, and discuss future directions.
Mobile App Tasks with Iterative Feedback (MoTIF): Addressing Task Feasibility in Interactive Visual Environments
Apr 17, 2021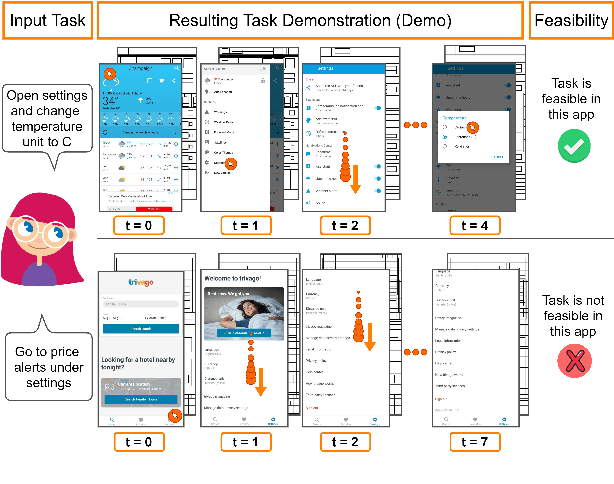
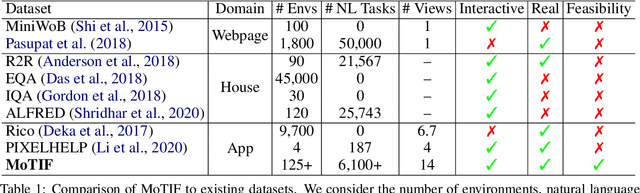
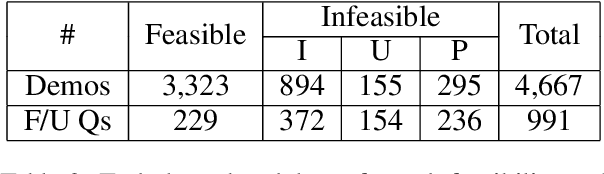
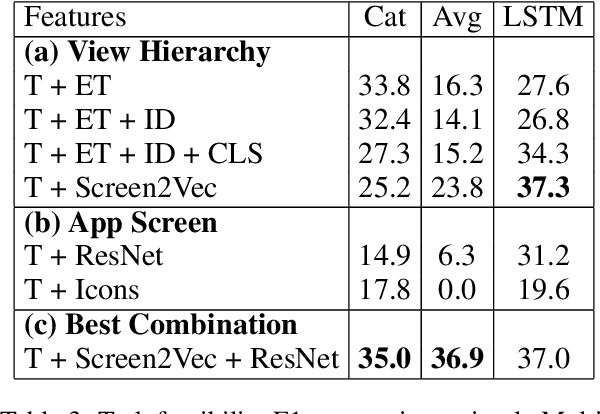
In recent years, vision-language research has shifted to study tasks which require more complex reasoning, such as interactive question answering, visual common sense reasoning, and question-answer plausibility prediction. However, the datasets used for these problems fail to capture the complexity of real inputs and multimodal environments, such as ambiguous natural language requests and diverse digital domains. We introduce Mobile app Tasks with Iterative Feedback (MoTIF), a dataset with natural language commands for the greatest number of interactive environments to date. MoTIF is the first to contain natural language requests for interactive environments that are not satisfiable, and we obtain follow-up questions on this subset to enable research on task uncertainty resolution. We perform initial feasibility classification experiments and only reach an F1 score of 37.3, verifying the need for richer vision-language representations and improved architectures to reason about task feasibility.