 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Mobile App Navigation with Uncertain or Under-specified Natural Language Commands
Feb 04, 2022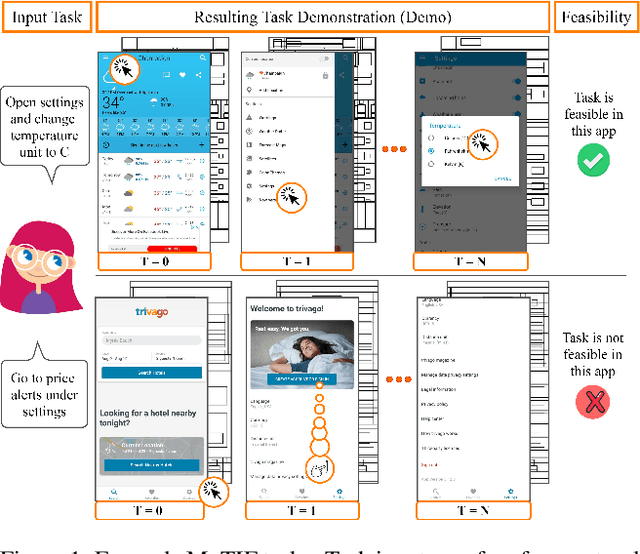
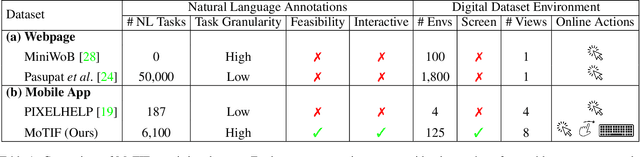
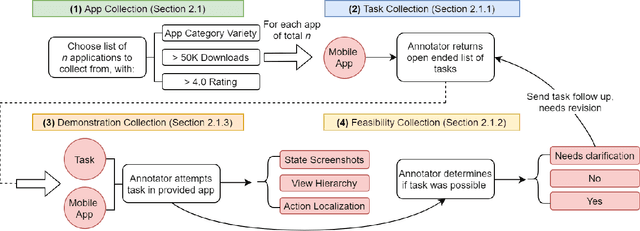
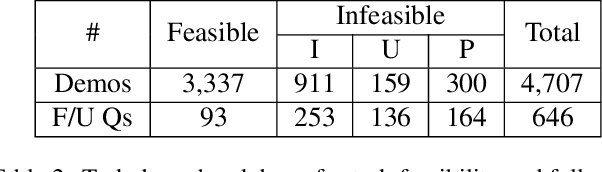
We introduce Mobile app Tasks with Iterative Feedback (MoTIF), a new dataset where the goal is to complete a natural language query in a mobile app. Current datasets for related tasks in interactive question answering, visual common sense reasoning, and question-answer plausibility prediction do not support research in resolving ambiguous natural language requests or operating in diverse digital domains. As a result, they fail to capture complexities of real question answering or interactive tasks. In contrast, MoTIF contains natural language requests that are not satisfiable, the first such work to investigate this issue for interactive vision-language tasks. MoTIF also contains follow up questions for ambiguous queries to enable research on task uncertainty resolution. We introduce task feasibility prediction and propose an initial model which obtains an F1 score of 61.1. We next benchmark task automation with our dataset and find adaptations of prior work perform poorly due to our realistic language requests, obtaining an accuracy of only 20.2% when mapping commands to grounded actions. We analyze performance and gain insight for future work that may bridge the gap between current model ability and what is needed for successful use in application.
Mobile App Tasks with Iterative Feedback (MoTIF): Addressing Task Feasibility in Interactive Visual Environments
Apr 17, 2021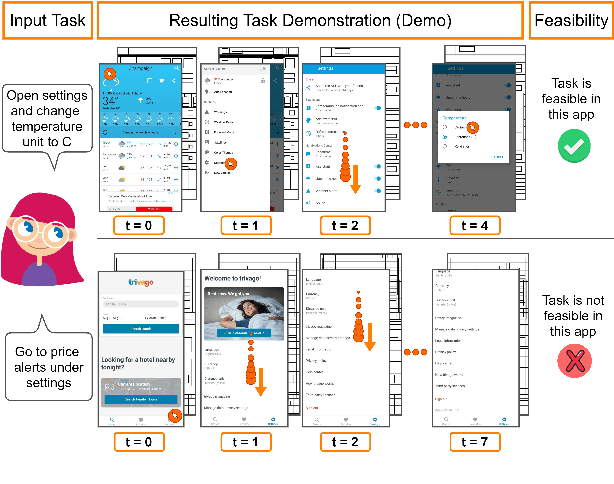
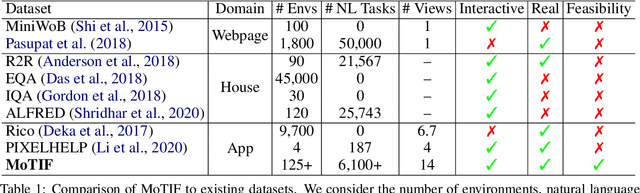
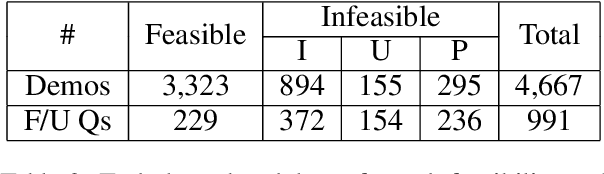
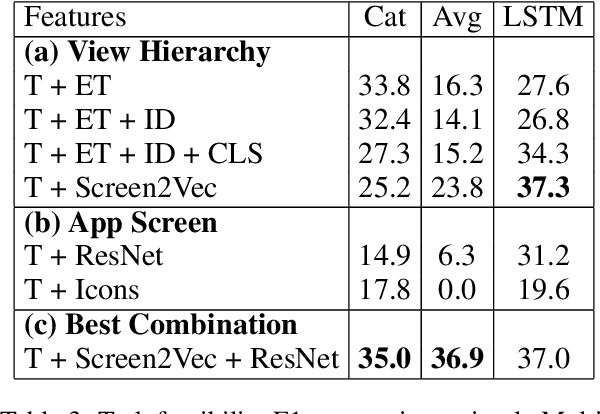
In recent years, vision-language research has shifted to study tasks which require more complex reasoning, such as interactive question answering, visual common sense reasoning, and question-answer plausibility prediction. However, the datasets used for these problems fail to capture the complexity of real inputs and multimodal environments, such as ambiguous natural language requests and diverse digital domains. We introduce Mobile app Tasks with Iterative Feedback (MoTIF), a dataset with natural language commands for the greatest number of interactive environments to date. MoTIF is the first to contain natural language requests for interactive environments that are not satisfiable, and we obtain follow-up questions on this subset to enable research on task uncertainty resolution. We perform initial feasibility classification experiments and only reach an F1 score of 37.3, verifying the need for richer vision-language representations and improved architectures to reason about task feasibility.