 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
Leveraging Data to Say No: Memory Augmented Plug-and-Play Selective Prediction
Jan 30, 2026Selective prediction aims to endow predictors with a reject option, to avoid low confidence predictions. However, existing literature has primarily focused on closed-set tasks, such as visual question answering with predefined options or fixed-category classification. This paper considers selective prediction for visual language foundation models, addressing a taxonomy of tasks ranging from closed to open set and from finite to unbounded vocabularies, as in image captioning. We seek training-free approaches of low-complexity, applicable to any foundation model and consider methods based on external vision-language model embeddings, like CLIP. This is denoted as Plug-and-Play Selective Prediction (PaPSP). We identify two key challenges: (1) instability of the visual-language representations, leading to high variance in image-text embeddings, and (2) poor calibration of similarity scores. To address these issues, we propose a memory augmented PaPSP (MA-PaPSP) model, which augments PaPSP with a retrieval dataset of image-text pairs. This is leveraged to reduce embedding variance by averaging retrieved nearest-neighbor pairs and is complemented by the use of contrastive normalization to improve score calibration. Through extensive experiments on multiple datasets, we show that MA-PaPSP outperforms PaPSP and other selective prediction baselines for selective captioning, image-text matching, and fine-grained classification. Code is publicly available at https://github.com/kingston-aditya/MA-PaPSP.
Socratic Students: Teaching Language Models to Learn by Asking Questions
Dec 20, 2025Large Language Models (LLMs) excel at static interactions, where they answer user queries by retrieving knowledge encoded in their parameters. However, in many real-world settings, such as educational tutoring or medical assistance, relevant information is not directly available and must be actively acquired through dynamic interactions. An interactive agent would recognize its own uncertainty, ask targeted questions, and retain new knowledge efficiently. Prior work has primarily explored effective ways for a teacher to instruct the student, where the teacher identifies student gaps and provides guidance. In this work, we shift the focus to the student and investigate effective strategies to actively query the teacher in seeking useful information. Across math and coding benchmarks, where baseline student models begin with near-zero performance, we show that student-led approaches consistently yield absolute Pass@k improvements of at least 0.5 over static baselines. To improve question quality, we train students using Direct Preference Optimization (DPO) with guidance from either self or stronger students. We find that this guided training enables smaller models to learn how to ask better questions, further enhancing learning efficiency.
Hyperbolic Contrastive Learning for Visual Representations beyond Objects
Dec 01, 2022



Although self-/un-supervised methods have led to rapid progress in visual representation learning, these methods generally treat objects and scenes using the same lens. In this paper, we focus on learning representations for objects and scenes that preserve the structure among them. Motivated by the observation that visually similar objects are close in the representation space, we argue that the scenes and objects should instead follow a hierarchical structure based on their compositionality. To exploit such a structure, we propose a contrastive learning framework where a Euclidean loss is used to learn object representations and a hyperbolic loss is used to encourage representations of scenes to lie close to representations of their constituent objects in a hyperbolic space. This novel hyperbolic objective encourages the scene-object hypernymy among the representations by optimizing the magnitude of their norms. We show that when pretraining on the COCO and OpenImages datasets, the hyperbolic loss improves downstream performance of several baselines across multiple datasets and tasks, including image classification, object detection, and semantic segmentation. We also show that the properties of the learned representations allow us to solve various vision tasks that involve the interaction between scenes and objects in a zero-shot fashion. Our code can be found at \url{https://github.com/shlokk/HCL/tree/main/HCL}.
A simple, efficient and scalable contrastive masked autoencoder for learning visual representations
Oct 30, 2022



We introduce CAN, a simple, efficient and scalable method for self-supervised learning of visual representations. Our framework is a minimal and conceptually clean synthesis of (C) contrastive learning, (A) masked autoencoders, and (N) the noise prediction approach used in diffusion models. The learning mechanisms are complementary to one another: contrastive learning shapes the embedding space across a batch of image samples; masked autoencoders focus on reconstruction of the low-frequency spatial correlations in a single image sample; and noise prediction encourages the reconstruction of the high-frequency components of an image. The combined approach results in a robust, scalable and simple-to-implement algorithm. The training process is symmetric, with 50% of patches in both views being masked at random, yielding a considerable efficiency improvement over prior contrastive learning methods. Extensive empirical studies demonstrate that CAN achieves strong downstream performance under both linear and finetuning evaluations on transfer learning and robustness tasks. CAN outperforms MAE and SimCLR when pre-training on ImageNet, but is especially useful for pre-training on larger uncurated datasets such as JFT-300M: for linear probe on ImageNet, CAN achieves 75.4% compared to 73.4% for SimCLR and 64.1% for MAE. The finetuned performance on ImageNet of our ViT-L model is 86.1%, compared to 85.5% for SimCLR, and 85.4% for MAE. The overall FLOPs load of SimCLR is 70% higher than CAN for ViT-L models.
Object-Aware Cropping for Self-Supervised Learning
Dec 01, 2021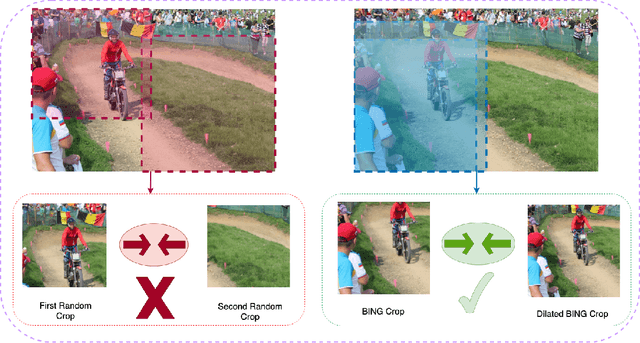
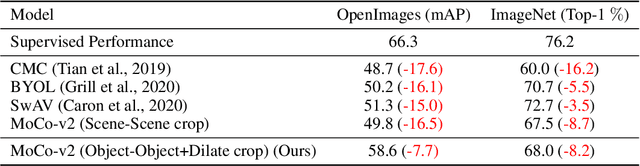
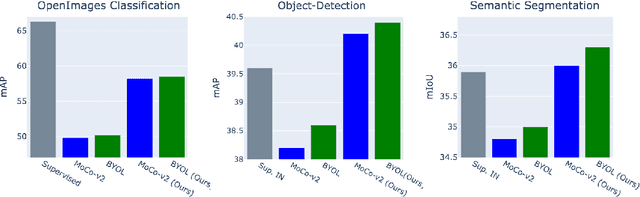

A core component of the recent success of self-supervised learning is cropping data augmentation, which selects sub-regions of an image to be used as positive views in the self-supervised loss. The underlying assumption is that randomly cropped and resized regions of a given image share information about the objects of interest, which the learned representation will capture. This assumption is mostly satisfied in datasets such as ImageNet where there is a large, centered object, which is highly likely to be present in random crops of the full image. However, in other datasets such as OpenImages or COCO, which are more representative of real world uncurated data, there are typically multiple small objects in an image. In this work, we show that self-supervised learning based on the usual random cropping performs poorly on such datasets. We propose replacing one or both of the random crops with crops obtained from an object proposal algorithm. This encourages the model to learn both object and scene level semantic representations. Using this approach, which we call object-aware cropping, results in significant improvements over scene cropping on classification and object detection benchmarks. For example, on OpenImages, our approach achieves an improvement of 8.8% mAP over random scene-level cropping using MoCo-v2 based pre-training. We also show significant improvements on COCO and PASCAL-VOC object detection and segmentation tasks over the state-of-the-art self-supervised learning approaches. Our approach is efficient, simple and general, and can be used in most existing contrastive and non-contrastive self-supervised learning frameworks.
Robust Contrastive Learning Using Negative Samples with Diminished Semantics
Oct 27, 2021
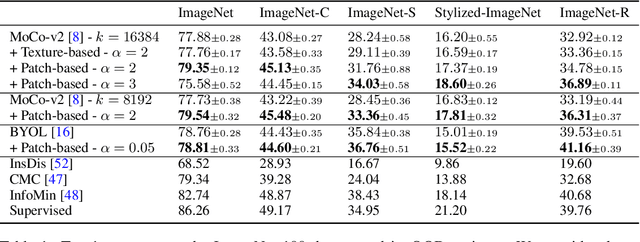
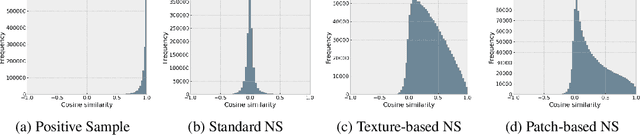

Unsupervised learning has recently made exceptional progress because of the development of more effective contrastive learning methods. However, CNNs are prone to depend on low-level features that humans deem non-semantic. This dependency has been conjectured to induce a lack of robustness to image perturbations or domain shift. In this paper, we show that by generating carefully designed negative samples, contrastive learning can learn more robust representations with less dependence on such features. Contrastive learning utilizes positive pairs that preserve semantic information while perturbing superficial features in the training images. Similarly, we propose to generate negative samples in a reversed way, where only the superfluous instead of the semantic features are preserved. We develop two methods, texture-based and patch-based augmentations, to generate negative samples. These samples achieve better generalization, especially under out-of-domain settings. We also analyze our method and the generated texture-based samples, showing that texture features are indispensable in classifying particular ImageNet classes and especially finer classes. We also show that model bias favors texture and shape features differently under different test settings. Our code, trained models, and ImageNet-Texture dataset can be found at https://github.com/SongweiGe/Contrastive-Learning-with-Non-Semantic-Negatives.
Learning Visual Representations for Transfer Learning by Suppressing Texture
Nov 04, 2020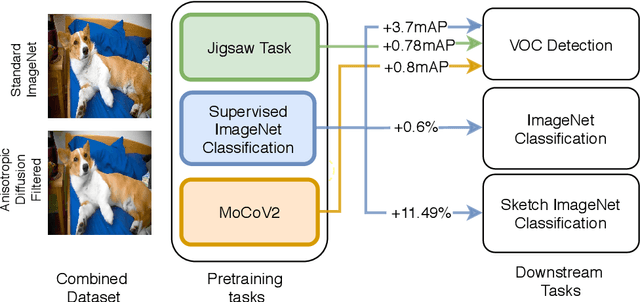
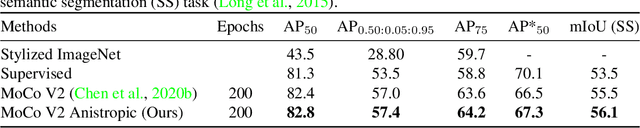


Recent literature has shown that features obtained from supervised training of CNNs may over-emphasize texture rather than encoding high-level information. In self-supervised learning in particular, texture as a low-level cue may provide shortcuts that prevent the network from learning higher level representations. To address these problems we propose to use classic methods based on anisotropic diffusion to augment training using images with suppressed texture. This simple method helps retain important edge information and suppress texture at the same time. We empirically show that our method achieves state-of-the-art results on object detection and image classification with eight diverse datasets in either supervised or self-supervised learning tasks such as MoCoV2 and Jigsaw. Our method is particularly effective for transfer learning tasks and we observed improved performance on five standard transfer learning datasets. The large improvements (up to 11.49\%) on the Sketch-ImageNet dataset, DTD dataset and additional visual analyses with saliency maps suggest that our approach helps in learning better representations that better transfer.
Pose And Joint-Aware Action Recognition
Oct 16, 2020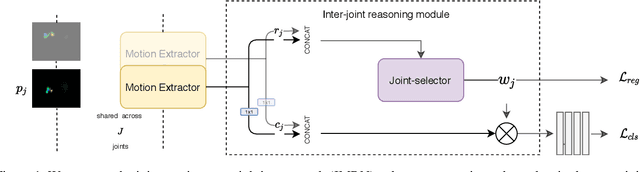
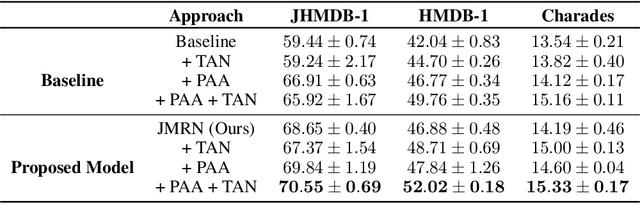
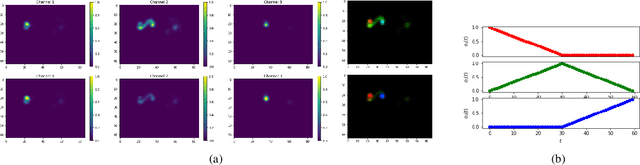
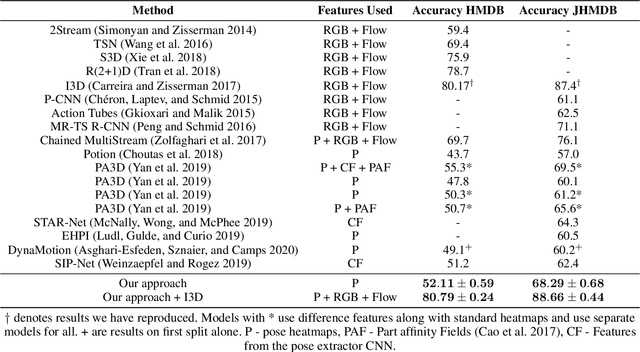
Most human action recognition systems typically consider static appearances and motion as independent streams of information. In this paper, we consider the evolution of human pose and propose a method to better capture interdependence among skeleton joints. Our model extracts motion information from each joint independently, reweighs the information and finally performs inter-joint reasoning. The effectiveness of pose and joint-based representations is strengthened using a geometry-aware data augmentation technique which jitters pose heatmaps while retaining the dynamics of the action. Our best model gives an absolute improvement of 8.19% on JHMDB, 4.31% on HMDB and 1.55 mAP on Charades datasets over state-of-the-art methods using pose heat-maps alone. Fusing with RGB and flow streams leads to improvement over state-of-the-art. Our model also outperforms the baseline on Mimetics, a dataset with out-of-context videos by 1.14% while using only pose heatmaps. Further, to filter out clips irrelevant for action recognition, we re-purpose our model for clip selection guided by pose information and show improved performance using fewer clips.