 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a General Intelligence and Interface for Wearable Health Data
May 21, 2026While ubiquitous wearable sensors capture a wealth of behavioral and physiological information, effectively transforming these signals into personalized health insights is challenging. Specifically, converting low-level sensor data into representations capable of characterizing higher-level states is difficult due to high phenotypic diversity and variation in individual baseline health, physiology, and lifestyle factors. Moreover, collecting wearable data paired with health outcome annotations is laborious and expensive, and retrospective annotation remains practically unfeasible, contributing to a scarcity of data with high-quality labels. To overcome these limitations, we propose a foundation model for wearable health that is pretrained on more than one trillion minutes of unlabeled sensor signals drawn from a large cohort of five million participants. We demonstrate that the joint scaling of model capacity and pretraining data volume leads to systematic improvements in performance, as evaluated on a diverse set of 35 health prediction tasks, spanning cardiovascular, metabolic, sleep, and mental health, as well as lifestyle choices and demographic factors. We find that this population scale representation unlocks label-efficient few-shot learning and generative capabilities for robust daily metric estimation. To further leverage this learned representation, we deploy a classroom of LLM agents to autonomously search the space of downstream predictive heads built on the model embeddings, showing broad performance improvements that increase with LLM model capacity. Finally, we show how integrating these downstream predictors into a Personal Health Agent can support model responses that are more relevant, contextually aware, and safe, and we validate this via 1,860 ratings from a cohort of clinicians.
WavesFM: Hierarchical Representation Learning for Longitudinal Wearable Sensor Waveforms
May 09, 2026Wearable sensors enable the continuous acquisition of high-resolution physiological waveforms, such as photoplethysmography and accelerometry, under free-living conditions. However, inferring health-related phenotypes from these signals presents significant challenges due to high sampling frequencies, multimodal dependencies, and extreme sequence lengths (e.g., weeks of recordings), compounded by a scarcity of ground-truth labels. To address these challenges, existing self-supervised learning (SSL) methodologies typically follow two paradigms: (1) learning rich morphological representations from short waveform segments while collapsing longitudinal dynamics through simple aggregation, or (2) modeling behavioral patterns from coarse, hand-crafted features (e.g. heart rate, step counts) spanning longer horizons but foregoing subtle, predictive signatures in raw waveforms. To bridge this gap, we propose WavesFM, a foundation model utilizing a two-stage SSL framework for longitudinal physiological data. Specifically, we decompose the learning problem into two stages: first, a segment-level encoder is pretrained to extract local embeddings from short waveforms; subsequently, a temporal encoder is trained to model the sequence of these embeddings across a multi-day horizon. This hierarchical approach overcomes the computational complexity of high-resolution, long-sequence data, allowing the overall model to capture both local signal semantics and the complex circadian and inter-day variations governing physiological dynamics. Pretrained on over 6.8M hours (N=324k individuals) of recordings for the first stage and 5.3M hours (N=10k) for the second stage, WavesFM demonstrates superior performance across 58 diverse tasks spanning demographics, lifestyle, health conditions, and medications.
Smartphone monitoring of smiling as a behavioral proxy of well-being in everyday life
Dec 10, 2025Subjective well-being is a cornerstone of individual and societal health, yet its scientific measurement has traditionally relied on self-report methods prone to recall bias and high participant burden. This has left a gap in our understanding of well-being as it is expressed in everyday life. We hypothesized that candid smiles captured during natural smartphone interactions could serve as a scalable, objective behavioral correlate of positive affect. To test this, we analyzed 405,448 video clips passively recorded from 233 consented participants over one week. Using a deep learning model to quantify smile intensity, we identified distinct diurnal and daily patterns. Daily patterns of smile intensity across the week showed strong correlation with national survey data on happiness (r=0.92), and diurnal rhythms documented close correspondence with established results from the day reconstruction method (r=0.80). Higher daily mean smile intensity was significantly associated with more physical activity (Beta coefficient = 0.043, 95% CI [0.001, 0.085]) and greater light exposure (Beta coefficient = 0.038, [0.013, 0.063]), whereas no significant effects were found for smartphone use. These findings suggest that passive smartphone sensing could serve as a powerful, ecologically valid methodology for studying the dynamics of affective behavior and open the door to understanding this behavior at a population scale.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025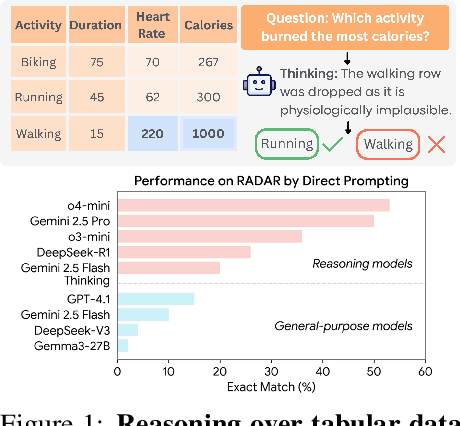
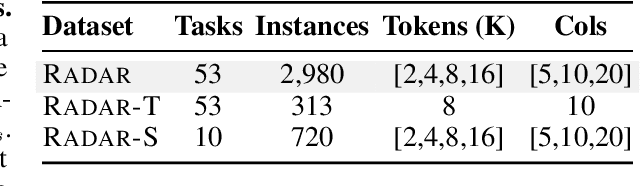
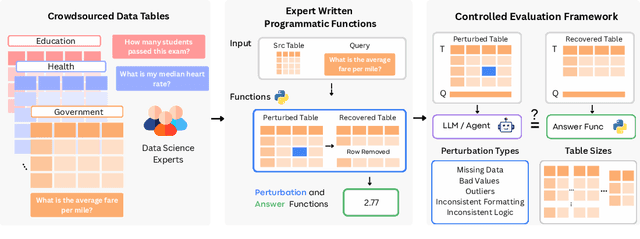
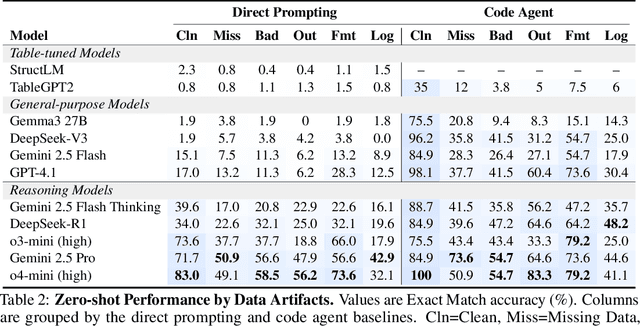
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Passive Heart Rate Monitoring During Smartphone Use in Everyday Life
Mar 04, 2025

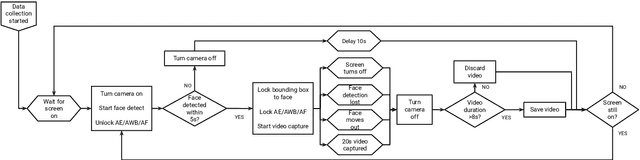

Resting heart rate (RHR) is an important biomarker of cardiovascular health and mortality, but tracking it longitudinally generally requires a wearable device, limiting its availability. We present PHRM, a deep learning system for passive heart rate (HR) and RHR measurements during everyday smartphone use, using facial video-based photoplethysmography. Our system was developed using 225,773 videos from 495 participants and validated on 185,970 videos from 205 participants in laboratory and free-living conditions, representing the largest validation study of its kind. Compared to reference electrocardiogram, PHRM achieved a mean absolute percentage error (MAPE) < 10% for HR measurements across three skin tone groups of light, medium and dark pigmentation; MAPE for each skin tone group was non-inferior versus the others. Daily RHR measured by PHRM had a mean absolute error < 5 bpm compared to a wearable HR tracker, and was associated with known risk factors. These results highlight the potential of smartphones to enable passive and equitable heart health monitoring.
Large Language Models are Few-Shot Health Learners
May 24, 2023
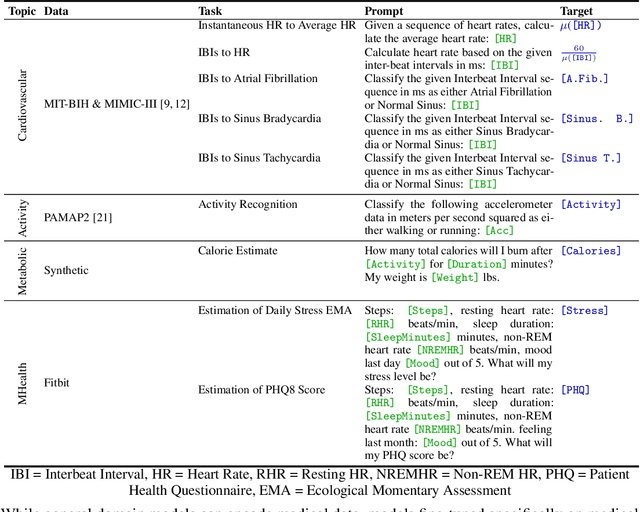

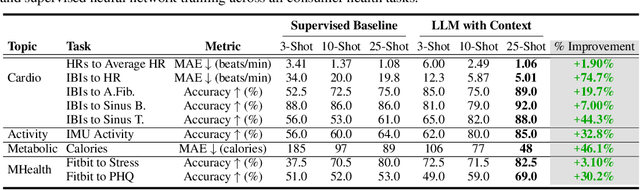
Large language models (LLMs) can capture rich representations of concepts that are useful for real-world tasks. However, language alone is limited. While existing LLMs excel at text-based inferences, health applications require that models be grounded in numerical data (e.g., vital signs, laboratory values in clinical domains; steps, movement in the wellness domain) that is not easily or readily expressed as text in existing training corpus. We demonstrate that with only few-shot tuning, a large language model is capable of grounding various physiological and behavioral time-series data and making meaningful inferences on numerous health tasks for both clinical and wellness contexts. Using data from wearable and medical sensor recordings, we evaluate these capabilities on the tasks of cardiac signal analysis, physical activity recognition, metabolic calculation (e.g., calories burned), and estimation of stress reports and mental health screeners.
SimPer: Simple Self-Supervised Learning of Periodic Targets
Oct 06, 2022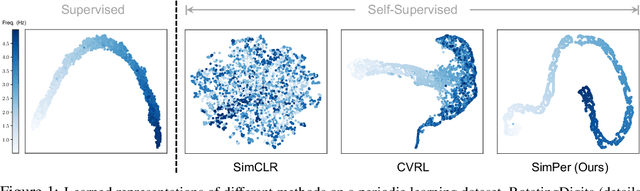
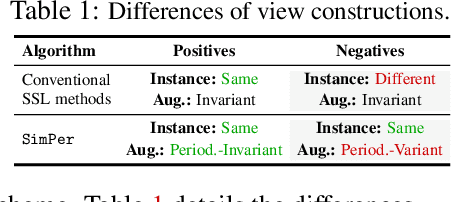
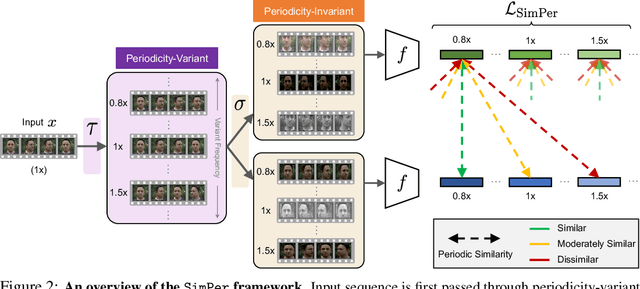

From human physiology to environmental evolution, important processes in nature often exhibit meaningful and strong periodic or quasi-periodic changes. Due to their inherent label scarcity, learning useful representations for periodic tasks with limited or no supervision is of great benefit. Yet, existing self-supervised learning (SSL) methods overlook the intrinsic periodicity in data, and fail to learn representations that capture periodic or frequency attributes. In this paper, we present SimPer, a simple contrastive SSL regime for learning periodic information in data. To exploit the periodic inductive bias, SimPer introduces customized augmentations, feature similarity measures, and a generalized contrastive loss for learning efficient and robust periodic representations. Extensive experiments on common real-world tasks in human behavior analysis, environmental sensing, and healthcare domains verify the superior performance of SimPer compared to state-of-the-art SSL methods, highlighting its intriguing properties including better data efficiency, robustness to spurious correlations, and generalization to distribution shifts. Code and data are available at: https://github.com/YyzHarry/SimPer.