 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Prospect Pruning: Finding Trainable Weights at Initialization using Meta-Gradients
Feb 16, 2022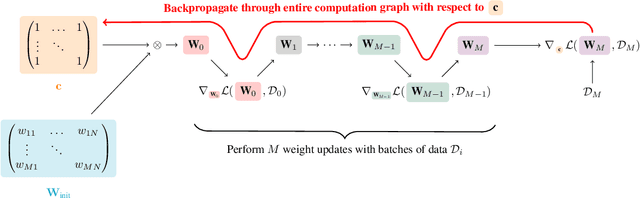
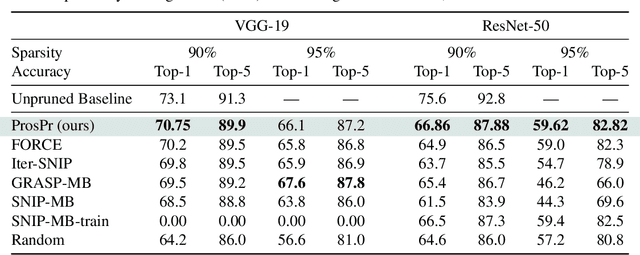
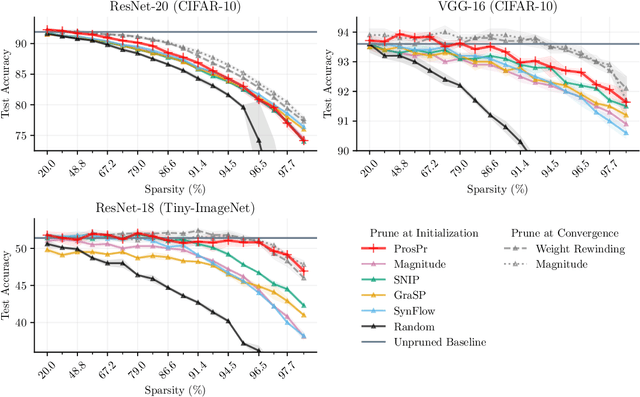
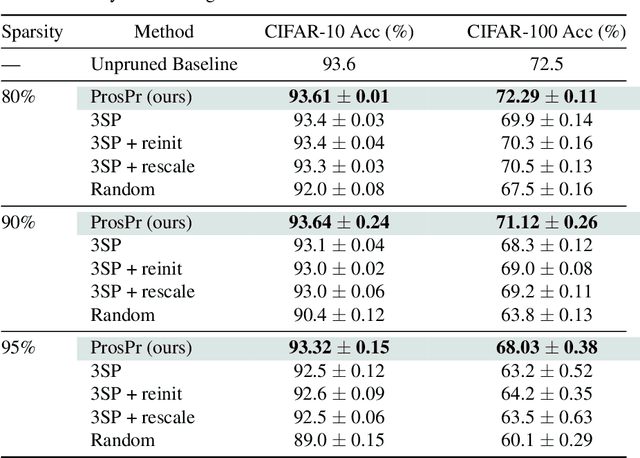
Pruning neural networks at initialization would enable us to find sparse models that retain the accuracy of the original network while consuming fewer computational resources for training and inference. However, current methods are insufficient to enable this optimization and lead to a large degradation in model performance. In this paper, we identify a fundamental limitation in the formulation of current methods, namely that their saliency criteria look at a single step at the start of training without taking into account the trainability of the network. While pruning iteratively and gradually has been shown to improve pruning performance, explicit consideration of the training stage that will immediately follow pruning has so far been absent from the computation of the saliency criterion. To overcome the short-sightedness of existing methods, we propose Prospect Pruning (ProsPr), which uses meta-gradients through the first few steps of optimization to determine which weights to prune. ProsPr combines an estimate of the higher-order effects of pruning on the loss and the optimization trajectory to identify the trainable sub-network. Our method achieves state-of-the-art pruning performance on a variety of vision classification tasks, with less data and in a single shot compared to existing pruning-at-initialization methods.
Towards Efficient Point Cloud Graph Neural Networks Through Architectural Simplification
Aug 13, 2021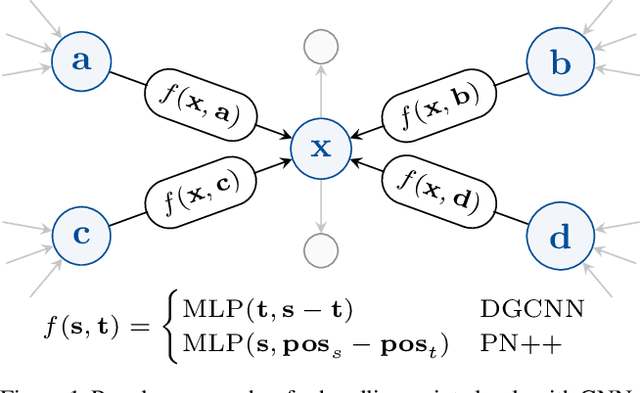
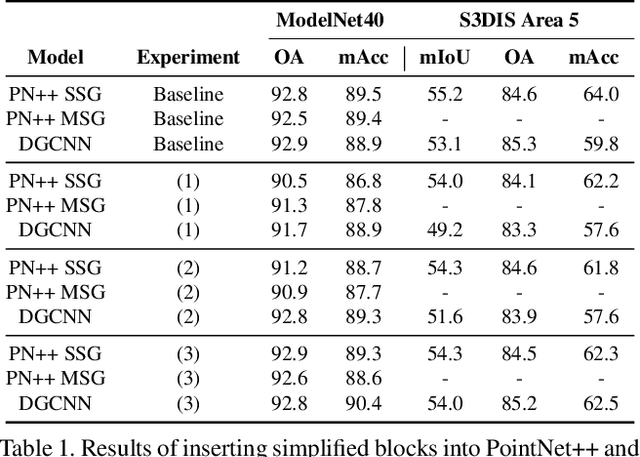

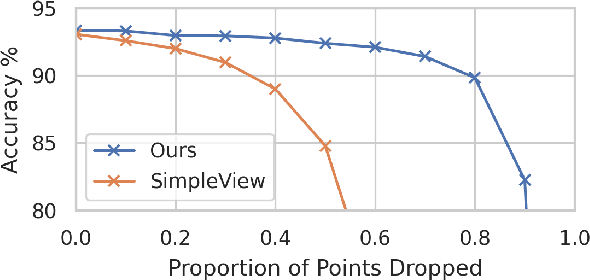
In recent years graph neural network (GNN)-based approaches have become a popular strategy for processing point cloud data, regularly achieving state-of-the-art performance on a variety of tasks. To date, the research community has primarily focused on improving model expressiveness, with secondary thought given to how to design models that can run efficiently on resource constrained mobile devices including smartphones or mixed reality headsets. In this work we make a step towards improving the efficiency of these models by making the observation that these GNN models are heavily limited by the representational power of their first, feature extracting, layer. We find that it is possible to radically simplify these models so long as the feature extraction layer is retained with minimal degradation to model performance; further, we discover that it is possible to improve performance overall on ModelNet40 and S3DIS by improving the design of the feature extractor. Our approach reduces memory consumption by 20$\times$ and latency by up to 9.9$\times$ for graph layers in models such as DGCNN; overall, we achieve speed-ups of up to 4.5$\times$ and peak memory reductions of 72.5%.
Adaptive Filters and Aggregator Fusion for Efficient Graph Convolutions
Apr 10, 2021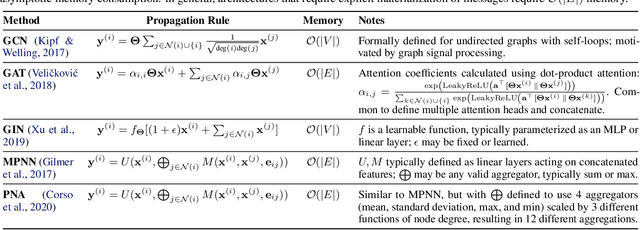
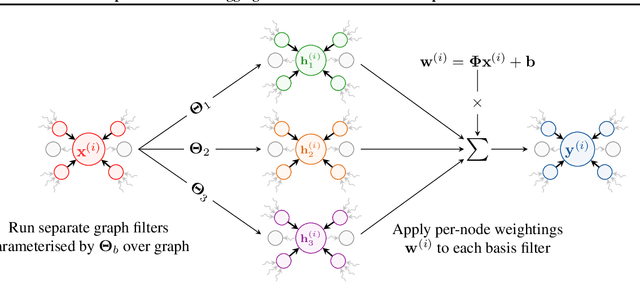
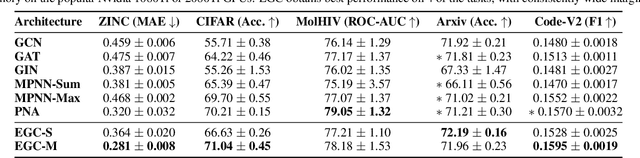

Training and deploying graph neural networks (GNNs) remains difficult due to their high memory consumption and inference latency. In this work we present a new type of GNN architecture that achieves state-of-the-art performance with lower memory consumption and latency, along with characteristics suited to accelerator implementation. Our proposal uses memory proportional to the number of vertices in the graph, in contrast to competing methods which require memory proportional to the number of edges; we find our efficient approach actually achieves higher accuracy than competing approaches across 5 large and varied datasets against strong baselines. We achieve our results by using a novel adaptive filtering approach inspired by signal processing; it can be interpreted as enabling each vertex to have its own weight matrix, and is not related to attention. Following our focus on efficient hardware usage, we propose aggregator fusion, a technique to enable GNNs to significantly boost their representational power, with only a small increase in latency of 19% over standard sparse matrix multiplication. Code and pretrained models can be found at this URL: https://github.com/shyam196/egc.
Degree-Quant: Quantization-Aware Training for Graph Neural Networks
Aug 11, 2020
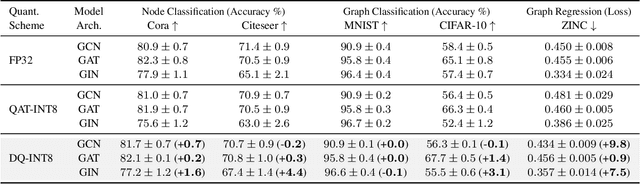
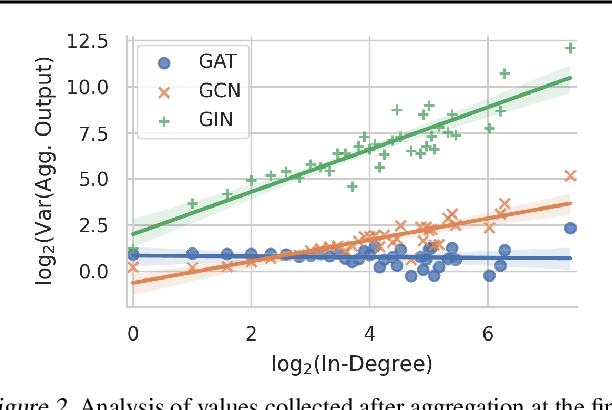
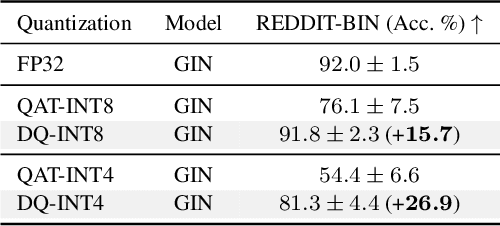
Graph neural networks (GNNs) have demonstrated strong performance on a wide variety of tasks due to their ability to model non-uniform structured data. Despite their promise, there exists little research exploring methods to make these architectures more efficient at inference time. In this work, we explore the viability of training quantized GNNs models, enabling the usage of low precision integer arithmetic during inference. We identify the sources of error that uniquely arise when attempting to quantize GNNs, and propose a method, Degree-Quant, to improve performance over existing quantization-aware training baselines commonly used on other architectures, such as CNNs. Models trained with Degree-Quant for INT8 quantization perform as well as FP32 models in most cases; for INT4 models, we obtain up to 69% gains over the baselines. Our work provides a comprehensive set of experiments across several datasets for node classification, graph classification and graph regression, laying strong foundations for future work in this area.
Are Accelerometers for Activity Recognition a Dead-end?
Jan 30, 2020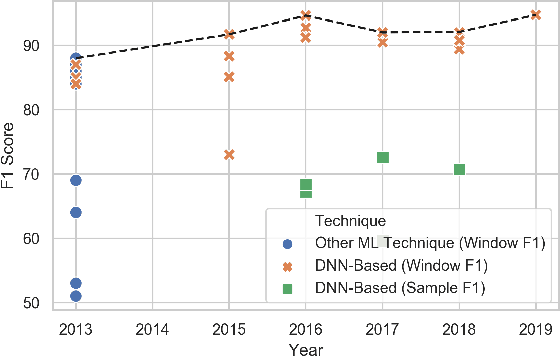

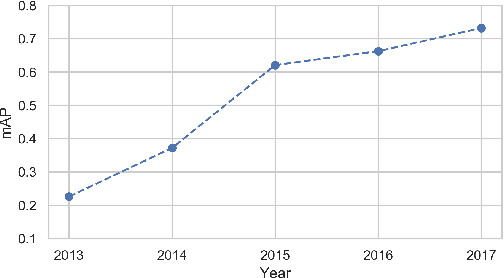
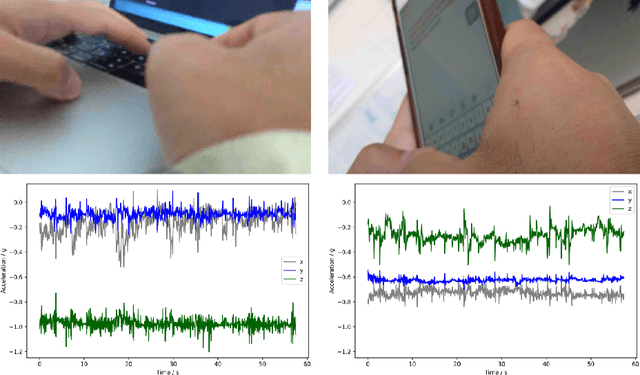
Accelerometer-based (and by extension other inertial sensors) research for Human Activity Recognition (HAR) is a dead-end. This sensor does not offer enough information for us to progress in the core domain of HAR - to recognize everyday activities from sensor data. Despite continued and prolonged efforts in improving feature engineering and machine learning models, the activities that we can recognize reliably have only expanded slightly and many of the same flaws of early models are still present today. Instead of relying on acceleration data, we should instead consider modalities with much richer information - a logical choice are images. With the rapid advance in image sensing hardware and modelling techniques, we believe that a widespread adoption of image sensors will open many opportunities for accurate and robust inference across a wide spectrum of human activities. In this paper, we make the case for imagers in place of accelerometers as the default sensor for human activity recognition. Our review of past works has led to the observation that progress in HAR had stalled, caused by our reliance on accelerometers. We further argue for the suitability of images for activity recognition by illustrating their richness of information and the marked progress in computer vision. Through a feasibility analysis, we find that deploying imagers and CNNs on device poses no substantial burden on modern mobile hardware. Overall, our work highlights the need to move away from accelerometers and calls for further exploration of using imagers for activity recognition.