 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifestyle-Informed Personalized Blood Biomarker Prediction via Novel Representation Learning
Jul 09, 2024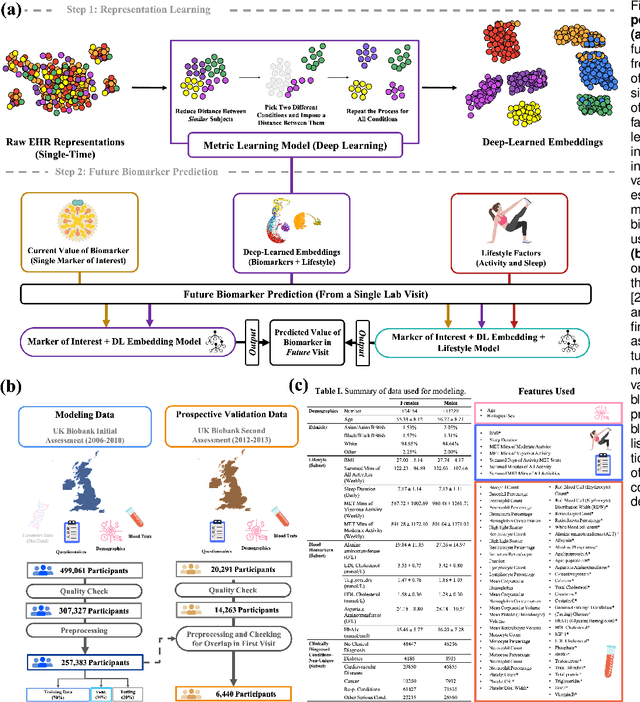
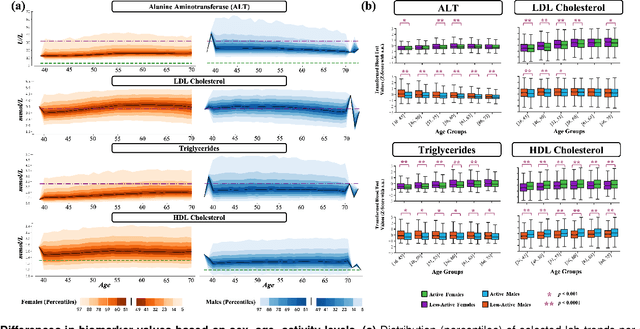

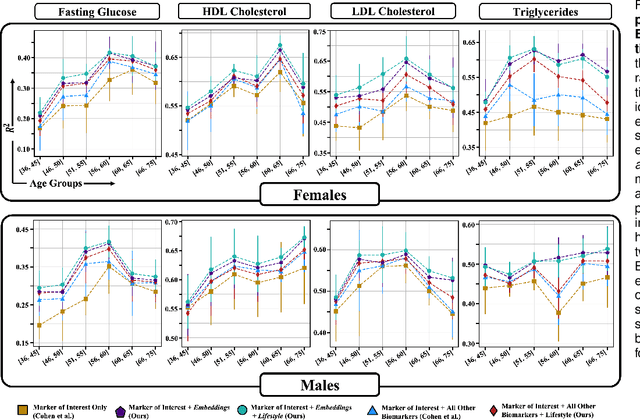
Blood biomarkers are an essential tool for healthcare providers to diagnose, monitor, and treat a wide range of medical conditions. Current reference values and recommended ranges often rely on population-level statistics, which may not adequately account for the influence of inter-individual variability driven by factors such as lifestyle and genetics. In this work, we introduce a novel framework for predicting future blood biomarker values and define personalized references through learned representations from lifestyle data (physical activity and sleep) and blood biomarkers. Our proposed method learns a similarity-based embedding space that captures the complex relationship between biomarkers and lifestyle factors. Using the UK Biobank (257K participants), our results show that our deep-learned embeddings outperform traditional and current state-of-the-art representation learning techniques in predicting clinical diagnosis. Using a subset of UK Biobank of 6440 participants who have follow-up visits, we validate that the inclusion of these embeddings and lifestyle factors directly in blood biomarker models improves the prediction of future lab values from a single lab visit. This personalized modeling approach provides a foundation for developing more accurate risk stratification tools and tailoring preventative care strategies. In clinical settings, this translates to the potential for earlier disease detection, more timely interventions, and ultimately, a shift towards personalized healthcare.
Transforming Wearable Data into Health Insights using Large Language Model Agents
Jun 11, 2024



Despite the proliferation of wearable health trackers and the importance of sleep and exercise to health, deriving actionable personalized insights from wearable data remains a challenge because doing so requires non-trivial open-ended analysis of these data. The recent rise of large language model (LLM) agents, which can use tools to reason about and interact with the world, presents a promising opportunity to enable such personalized analysis at scale. Yet, the application of LLM agents in analyzing personal health is still largely untapped. In this paper, we introduce the Personal Health Insights Agent (PHIA), an agent system that leverages state-of-the-art code generation and information retrieval tools to analyze and interpret behavioral health data from wearables. We curate two benchmark question-answering datasets of over 4000 health insights questions. Based on 650 hours of human and expert evaluation we find that PHIA can accurately address over 84% of factual numerical questions and more than 83% of crowd-sourced open-ended questions. This work has implications for advancing behavioral health across the population, potentially enabling individuals to interpret their own wearable data, and paving the way for a new era of accessible, personalized wellness regimens that are informed by data-driven insights.
No Pairs Left Behind: Improving Metric Learning with Regularized Triplet Objective
Oct 18, 2022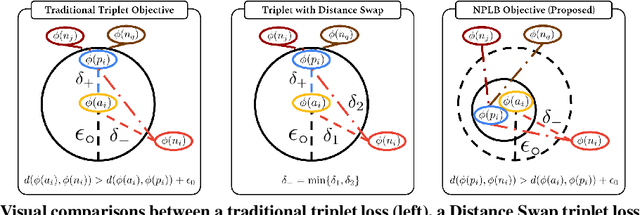

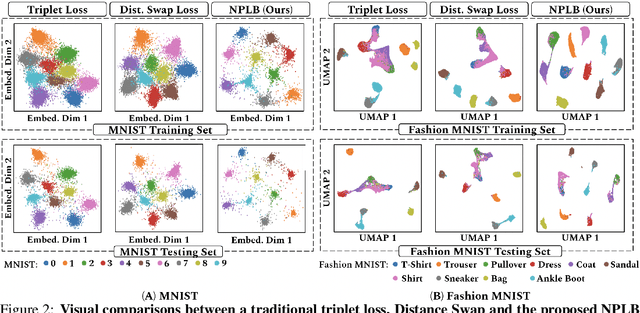
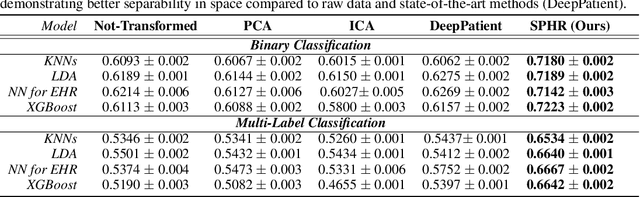
We propose a novel formulation of the triplet objective function that improves metric learning without additional sample mining or overhead costs. Our approach aims to explicitly regularize the distance between the positive and negative samples in a triplet with respect to the anchor-negative distance. As an initial validation, we show that our method (called No Pairs Left Behind [NPLB]) improves upon the traditional and current state-of-the-art triplet objective formulations on standard benchmark datasets. To show the effectiveness and potentials of NPLB on real-world complex data, we evaluate our approach on a large-scale healthcare dataset (UK Biobank), demonstrating that the embeddings learned by our model significantly outperform all other current representations on tested downstream tasks. Additionally, we provide a new model-agnostic single-time health risk definition that, when used in tandem with the learned representations, achieves the most accurate prediction of subjects' future health complications. Our results indicate that NPLB is a simple, yet effective framework for improving existing deep metric learning models, showcasing the potential implications of metric learning in more complex applications, especially in the biological and healthcare domains.