 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe opportunities and risks of large language models in mental health
Mar 26, 2024



Global rates of mental health concerns are rising and there is increasing realization that existing models of mental healthcare will not adequately expand to meet the demand. With the emergence of large language models (LLMs) has come great optimism regarding their promise to create novel, large-scale solutions to support mental health. Despite their nascence, LLMs have already been applied to mental health-related tasks. In this review, we summarize the extant literature on efforts to use LLMs to provide mental health education, assessment, and intervention and highlight key opportunities for positive impact in each area. We then highlight risks associated with LLMs application to mental health and encourage adoption of strategies to mitigate these risks. The urgent need for mental health support must be balanced with responsible development, testing, and deployment of mental health LLMs. Especially critical is ensuring that mental health LLMs are fine-tuned for mental health, enhance mental health equity, adhere to ethical standards, and that people, including those with lived experience with mental health concerns, are involved in all stages from development through deployment. Prioritizing these efforts will minimize potential harms to mental health and maximize the likelihood that LLMs will positively impact mental health globally.
No Pairs Left Behind: Improving Metric Learning with Regularized Triplet Objective
Oct 18, 2022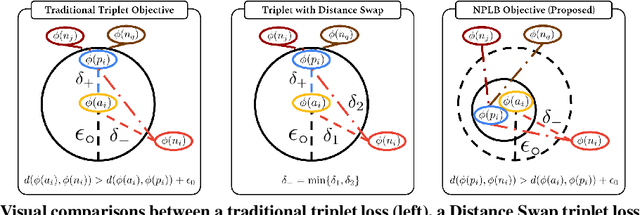

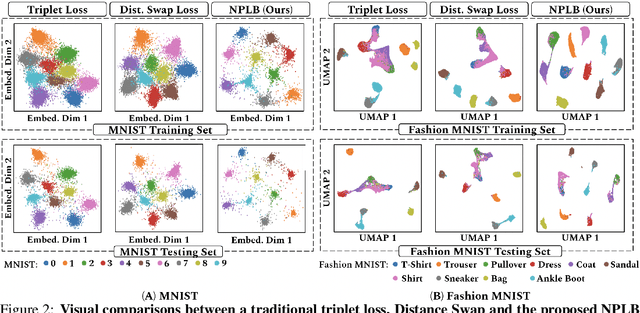
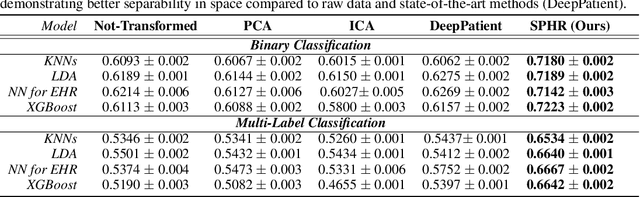
We propose a novel formulation of the triplet objective function that improves metric learning without additional sample mining or overhead costs. Our approach aims to explicitly regularize the distance between the positive and negative samples in a triplet with respect to the anchor-negative distance. As an initial validation, we show that our method (called No Pairs Left Behind [NPLB]) improves upon the traditional and current state-of-the-art triplet objective formulations on standard benchmark datasets. To show the effectiveness and potentials of NPLB on real-world complex data, we evaluate our approach on a large-scale healthcare dataset (UK Biobank), demonstrating that the embeddings learned by our model significantly outperform all other current representations on tested downstream tasks. Additionally, we provide a new model-agnostic single-time health risk definition that, when used in tandem with the learned representations, achieves the most accurate prediction of subjects' future health complications. Our results indicate that NPLB is a simple, yet effective framework for improving existing deep metric learning models, showcasing the potential implications of metric learning in more complex applications, especially in the biological and healthcare domains.