 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Diagnostic Reasoning Framework for Pathology with Multimodal Large Language Models
Nov 15, 2025AI tools in pathology have improved screening throughput, standardized quantification, and revealed prognostic patterns that inform treatment. However, adoption remains limited because most systems still lack the human-readable reasoning needed to audit decisions and prevent errors. We present RECAP-PATH, an interpretable framework that establishes a self-learning paradigm, shifting off-the-shelf multimodal large language models from passive pattern recognition to evidence-linked diagnostic reasoning. At its core is a two-phase learning process that autonomously derives diagnostic criteria: diversification expands pathology-style explanations, while optimization refines them for accuracy. This self-learning approach requires only small labeled sets and no white-box access or weight updates to generate cancer diagnoses. Evaluated on breast and prostate datasets, RECAP-PATH produced rationales aligned with expert assessment and delivered substantial gains in diagnostic accuracy over baselines. By uniting visual understanding with reasoning, RECAP-PATH provides clinically trustworthy AI and demonstrates a generalizable path toward evidence-linked interpretation.
Uncertainty-Guided Selective Adaptation Enables Cross-Platform Predictive Fluorescence Microscopy
Nov 15, 2025Deep learning is transforming microscopy, yet models often fail when applied to images from new instruments or acquisition settings. Conventional adversarial domain adaptation (ADDA) retrains entire networks, often disrupting learned semantic representations. Here, we overturn this paradigm by showing that adapting only the earliest convolutional layers, while freezing deeper layers, yields reliable transfer. Building on this principle, we introduce Subnetwork Image Translation ADDA with automatic depth selection (SIT-ADDA-Auto), a self-configuring framework that integrates shallow-layer adversarial alignment with predictive uncertainty to automatically select adaptation depth without target labels. We demonstrate robustness via multi-metric evaluation, blinded expert assessment, and uncertainty-depth ablations. Across exposure and illumination shifts, cross-instrument transfer, and multiple stains, SIT-ADDA improves reconstruction and downstream segmentation over full-encoder adaptation and non-adversarial baselines, with reduced drift of semantic features. Our results provide a design rule for label-free adaptation in microscopy and a recipe for field settings; the code is publicly available.
Concept Gradient: Concept-based Interpretation Without Linear Assumption
Aug 31, 2022
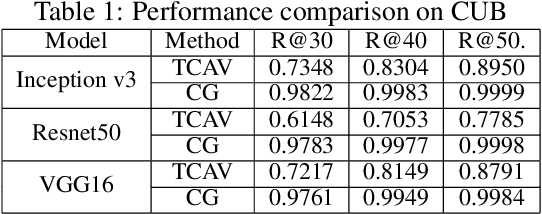
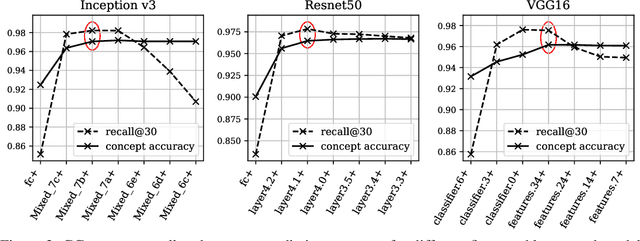
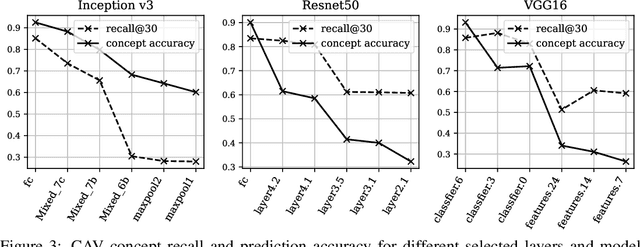
Concept-based interpretations of black-box models are often more intuitive for humans to understand. The most widely adopted approach for concept-based interpretation is Concept Activation Vector (CAV). CAV relies on learning a linear relation between some latent representation of a given model and concepts. The linear separability is usually implicitly assumed but does not hold true in general. In this work, we started from the original intent of concept-based interpretation and proposed Concept Gradient (CG), extending concept-based interpretation beyond linear concept functions. We showed that for a general (potentially non-linear) concept, we can mathematically evaluate how a small change of concept affecting the model's prediction, which leads to an extension of gradient-based interpretation to the concept space. We demonstrated empirically that CG outperforms CAV in both toy examples and real world datasets.