 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Diffusion Step to Real-World Super-Resolution via Flow Trajectory Distillation
Feb 04, 2025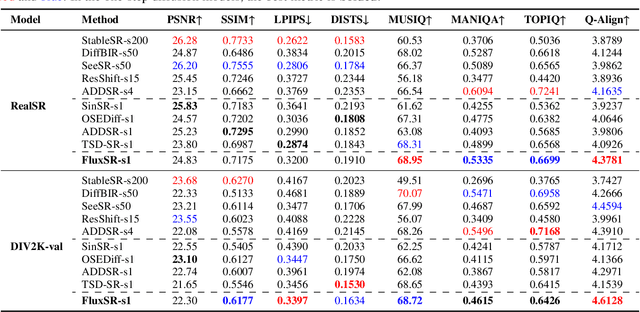
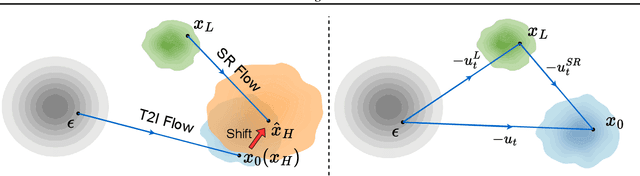
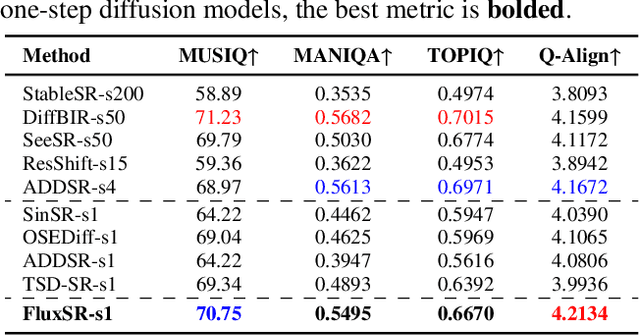
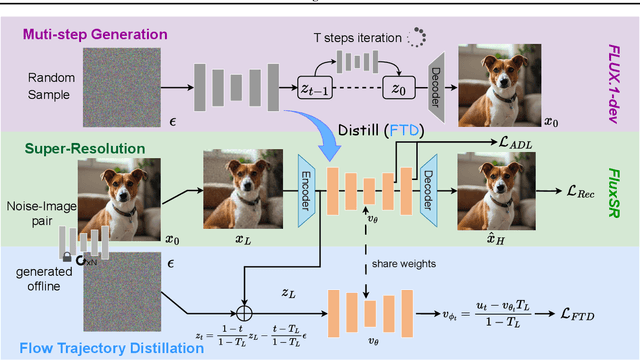
Diffusion models (DMs) have significantly advanced the development of real-world image super-resolution (Real-ISR), but the computational cost of multi-step diffusion models limits their application. One-step diffusion models generate high-quality images in a one sampling step, greatly reducing computational overhead and inference latency. However, most existing one-step diffusion methods are constrained by the performance of the teacher model, where poor teacher performance results in image artifacts. To address this limitation, we propose FluxSR, a novel one-step diffusion Real-ISR technique based on flow matching models. We use the state-of-the-art diffusion model FLUX.1-dev as both the teacher model and the base model. First, we introduce Flow Trajectory Distillation (FTD) to distill a multi-step flow matching model into a one-step Real-ISR. Second, to improve image realism and address high-frequency artifact issues in generated images, we propose TV-LPIPS as a perceptual loss and introduce Attention Diversification Loss (ADL) as a regularization term to reduce token similarity in transformer, thereby eliminating high-frequency artifacts. Comprehensive experiments demonstrate that our method outperforms existing one-step diffusion-based Real-ISR methods. The code and model will be released at https://github.com/JianzeLi-114/FluxSR.
PassionSR: Post-Training Quantization with Adaptive Scale in One-Step Diffusion based Image Super-Resolution
Nov 26, 2024



Diffusion-based image super-resolution (SR) models have shown superior performance at the cost of multiple denoising steps. However, even though the denoising step has been reduced to one, they require high computational costs and storage requirements, making it difficult for deployment on hardware devices. To address these issues, we propose a novel post-training quantization approach with adaptive scale in one-step diffusion (OSD) image SR, PassionSR. First, we simplify OSD model to two core components, UNet and Variational Autoencoder (VAE) by removing the CLIPEncoder. Secondly, we propose Learnable Boundary Quantizer (LBQ) and Learnable Equivalent Transformation (LET) to optimize the quantization process and manipulate activation distributions for better quantization. Finally, we design a Distributed Quantization Calibration (DQC) strategy that stabilizes the training of quantized parameters for rapid convergence. Comprehensive experiments demonstrate that PassionSR with 8-bit and 6-bit obtains comparable visual results with full-precision model. Moreover, our PassionSR achieves significant advantages over recent leading low-bit quantization methods for image SR. Our code will be at https://github.com/libozhu03/PassionSR.
Distillation-Free One-Step Diffusion for Real-World Image Super-Resolution
Oct 05, 2024Diffusion models have been achieving excellent performance for real-world image super-resolution (Real-ISR) with considerable computational costs. Current approaches are trying to derive one-step diffusion models from multi-step counterparts through knowledge distillation. However, these methods incur substantial training costs and may constrain the performance of the student model by the teacher's limitations. To tackle these issues, we propose DFOSD, a Distillation-Free One-Step Diffusion model. Specifically, we propose a noise-aware discriminator (NAD) to participate in adversarial training, further enhancing the authenticity of the generated content. Additionally, we improve the perceptual loss with edge-aware DISTS (EA-DISTS) to enhance the model's ability to generate fine details. Our experiments demonstrate that, compared with previous diffusion-based methods requiring dozens or even hundreds of steps, our DFOSD attains comparable or even superior results in both quantitative metrics and qualitative evaluations. Our DFOSD also abtains higher performance and efficiency compared with other one-step diffusion methods. We will release code and models at \url{https://github.com/JianzeLi-114/DFOSD}.
Fusing Pruned and Backdoored Models: Optimal Transport-based Data-free Backdoor Mitigation
Aug 28, 2024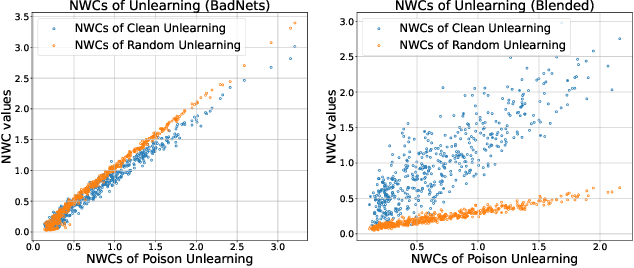
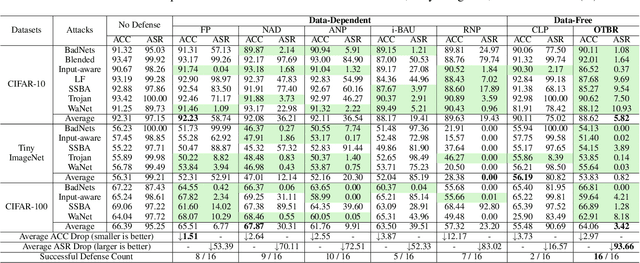
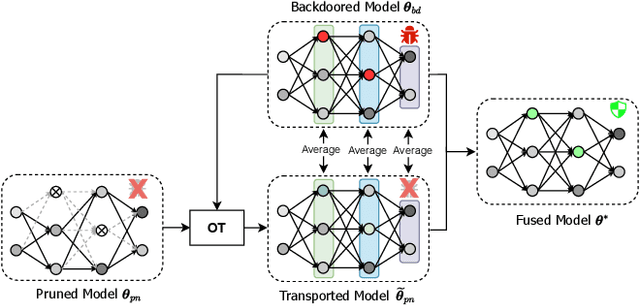
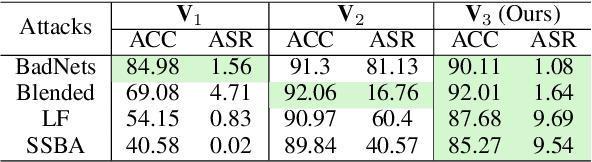
Backdoor attacks present a serious security threat to deep neuron networks (DNNs). Although numerous effective defense techniques have been proposed in recent years, they inevitably rely on the availability of either clean or poisoned data. In contrast, data-free defense techniques have evolved slowly and still lag significantly in performance. To address this issue, different from the traditional approach of pruning followed by fine-tuning, we propose a novel data-free defense method named Optimal Transport-based Backdoor Repairing (OTBR) in this work. This method, based on our findings on neuron weight changes (NWCs) of random unlearning, uses optimal transport (OT)-based model fusion to combine the advantages of both pruned and backdoored models. Specifically, we first demonstrate our findings that the NWCs of random unlearning are positively correlated with those of poison unlearning. Based on this observation, we propose a random-unlearning NWC pruning technique to eliminate the backdoor effect and obtain a backdoor-free pruned model. Then, motivated by the OT-based model fusion, we propose the pruned-to-backdoored OT-based fusion technique, which fuses pruned and backdoored models to combine the advantages of both, resulting in a model that demonstrates high clean accuracy and a low attack success rate. To our knowledge, this is the first work to apply OT and model fusion techniques to backdoor defense. Extensive experiments show that our method successfully defends against all seven backdoor attacks across three benchmark datasets, outperforming both state-of-the-art (SOTA) data-free and data-dependent methods. The code implementation and Appendix are provided in the Supplementary Material.
Unveiling and Mitigating Backdoor Vulnerabilities based on Unlearning Weight Changes and Backdoor Activeness
May 30, 2024



The security threat of backdoor attacks is a central concern for deep neural networks (DNNs). Recently, without poisoned data, unlearning models with clean data and then learning a pruning mask have contributed to backdoor defense. Additionally, vanilla fine-tuning with those clean data can help recover the lost clean accuracy. However, the behavior of clean unlearning is still under-explored, and vanilla fine-tuning unintentionally induces back the backdoor effect. In this work, we first investigate model unlearning from the perspective of weight changes and gradient norms, and find two interesting observations in the backdoored model: 1) the weight changes between poison and clean unlearning are positively correlated, making it possible for us to identify the backdoored-related neurons without using poisoned data; 2) the neurons of the backdoored model are more active (i.e., larger changes in gradient norm) than those in the clean model, suggesting the need to suppress the gradient norm during fine-tuning. Then, we propose an effective two-stage defense method. In the first stage, an efficient Neuron Weight Change (NWC)-based Backdoor Reinitialization is proposed based on observation 1). In the second stage, based on observation 2), we design an Activeness-Aware Fine-Tuning to replace the vanilla fine-tuning. Extensive experiments, involving eight backdoor attacks on three benchmark datasets, demonstrate the superior performance of our proposed method compared to recent state-of-the-art backdoor defense approaches.
TAOTF: A Two-stage Approximately Orthogonal Training Framework in Deep Neural Networks
Dec 10, 2022The orthogonality constraints, including the hard and soft ones, have been used to normalize the weight matrices of Deep Neural Network (DNN) models, especially the Convolutional Neural Network (CNN) and Vision Transformer (ViT), to reduce model parameter redundancy and improve training stability. However, the robustness to noisy data of these models with constraints is not always satisfactory. In this work, we propose a novel two-stage approximately orthogonal training framework (TAOTF) to find a trade-off between the orthogonal solution space and the main task solution space to solve this problem in noisy data scenarios. In the first stage, we propose a novel algorithm called polar decomposition-based orthogonal initialization (PDOI) to find a good initialization for the orthogonal optimization. In the second stage, unlike other existing methods, we apply soft orthogonal constraints for all layers of DNN model. We evaluate the proposed model-agnostic framework both on the natural image and medical image datasets, which show that our method achieves stable and superior performances to existing methods.
Data-free Backdoor Removal based on Channel Lipschitzness
Aug 05, 2022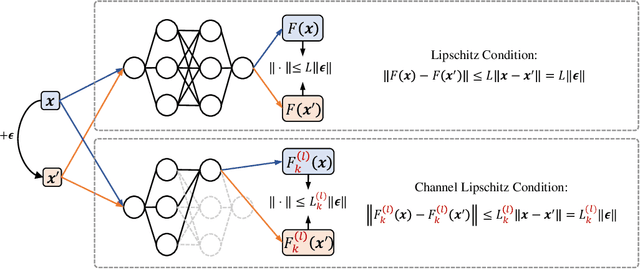
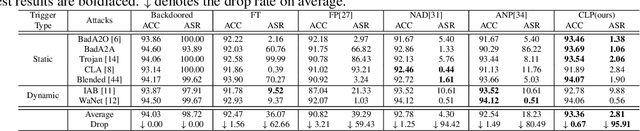
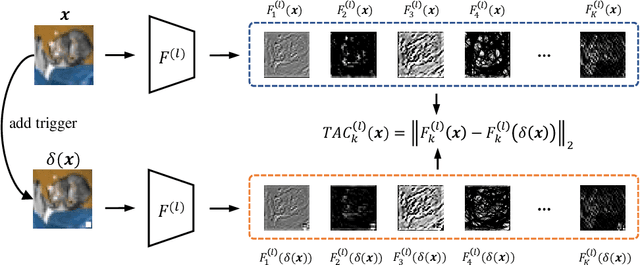
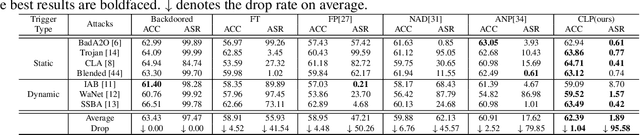
Recent studies have shown that Deep Neural Networks (DNNs) are vulnerable to the backdoor attacks, which leads to malicious behaviors of DNNs when specific triggers are attached to the input images. It was further demonstrated that the infected DNNs possess a collection of channels, which are more sensitive to the backdoor triggers compared with normal channels. Pruning these channels was then shown to be effective in mitigating the backdoor behaviors. To locate those channels, it is natural to consider their Lipschitzness, which measures their sensitivity against worst-case perturbations on the inputs. In this work, we introduce a novel concept called Channel Lipschitz Constant (CLC), which is defined as the Lipschitz constant of the mapping from the input images to the output of each channel. Then we provide empirical evidences to show the strong correlation between an Upper bound of the CLC (UCLC) and the trigger-activated change on the channel activation. Since UCLC can be directly calculated from the weight matrices, we can detect the potential backdoor channels in a data-free manner, and do simple pruning on the infected DNN to repair the model. The proposed Channel Lipschitzness based Pruning (CLP) method is super fast, simple, data-free and robust to the choice of the pruning threshold. Extensive experiments are conducted to evaluate the efficiency and effectiveness of CLP, which achieves state-of-the-art results among the mainstream defense methods even without any data. Source codes are available at https://github.com/rkteddy/channel-Lipschitzness-based-pruning.
Point cloud denoising based on tensor Tucker decomposition
Feb 20, 2019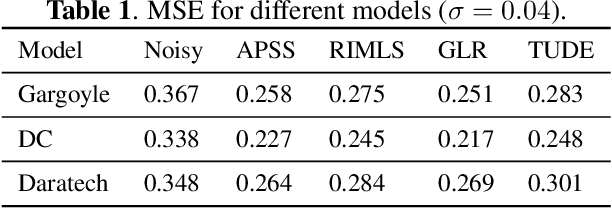

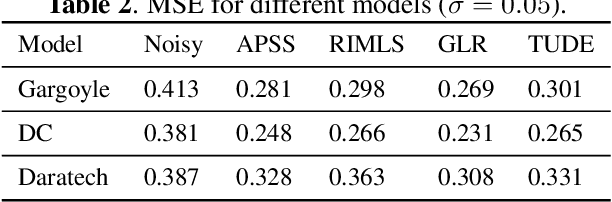
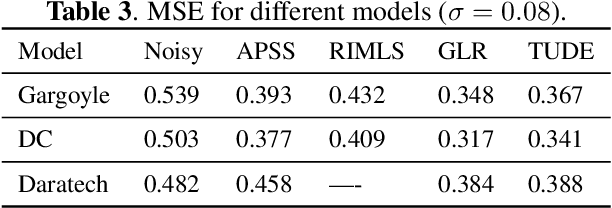
In this paper, we propose an algorithm for point cloud denoising based on the tensor Tucker decomposition. We first represent the local surface patches of a noisy point cloud to be matrices by their distances to a reference point, and stack the similar patch matrices to be a 3rd order tensor. Then we use the Tucker decomposition to compress this patch tensor to be a core tensor of smaller size. We consider this core tensor as the frequency domain and remove the noise by manipulating the hard thresholding. Finally, all the fibers of the denoised patch tensor are placed back, and the average is taken if there are more than one estimators overlapped. The experimental evaluation shows that the proposed algorithm outperforms the state-of-the-art graph Laplacian regularized (GLR) algorithm when the Gaussian noise is high ($\sigma=0.1$), and the GLR algorithm is better in lower noise cases ($\sigma=0.04, 0.05, 0.08$).