 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombined Flicker-banding and Moire Removal for Screen-Captured Images
Feb 02, 2026Capturing display screens with mobile devices has become increasingly common, yet the resulting images often suffer from severe degradations caused by the coexistence of moiré patterns and flicker-banding, leading to significant visual quality degradation. Due to the strong coupling of these two artifacts in real imaging processes, existing methods designed for single degradations fail to generalize to such compound scenarios. In this paper, we present the first systematic study on joint removal of moiré patterns and flicker-banding in screen-captured images, and propose a unified restoration framework, named CLEAR. To support this task, we construct a large-scale dataset containing both moiré patterns and flicker-banding, and introduce an ISP-based flicker simulation pipeline to stabilize model training and expand the degradation distribution. Furthermore, we design a frequency-domain decomposition and re-composition module together with a trajectory alignment loss to enhance the modeling of compound artifacts. Extensive experiments demonstrate that the proposed method consistently. outperforms existing image restoration approaches across multiple evaluation metrics, validating its effectiveness in complex real-world scenarios.
QuantVSR: Low-Bit Post-Training Quantization for Real-World Video Super-Resolution
Aug 06, 2025

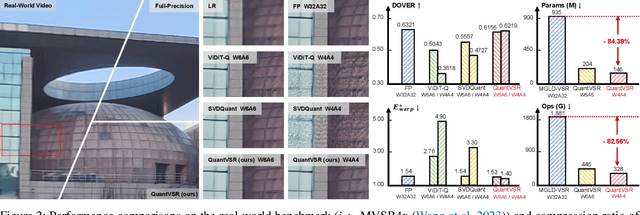
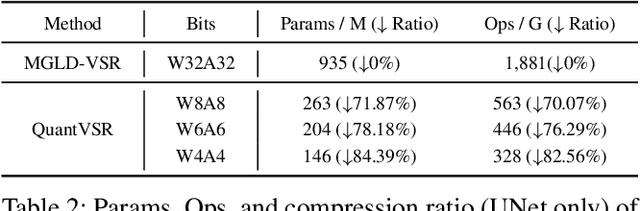
Diffusion models have shown superior performance in real-world video super-resolution (VSR). However, the slow processing speeds and heavy resource consumption of diffusion models hinder their practical application and deployment. Quantization offers a potential solution for compressing the VSR model. Nevertheless, quantizing VSR models is challenging due to their temporal characteristics and high fidelity requirements. To address these issues, we propose QuantVSR, a low-bit quantization model for real-world VSR. We propose a spatio-temporal complexity aware (STCA) mechanism, where we first utilize the calibration dataset to measure both spatial and temporal complexities for each layer. Based on these statistics, we allocate layer-specific ranks to the low-rank full-precision (FP) auxiliary branch. Subsequently, we jointly refine the FP and low-bit branches to achieve simultaneous optimization. In addition, we propose a learnable bias alignment (LBA) module to reduce the biased quantization errors. Extensive experiments on synthetic and real-world datasets demonstrate that our method obtains comparable performance with the FP model and significantly outperforms recent leading low-bit quantization methods. Code is available at: https://github.com/bowenchai/QuantVSR.
QArtSR: Quantization via Reverse-Module and Timestep-Retraining in One-Step Diffusion based Image Super-Resolution
Mar 07, 2025
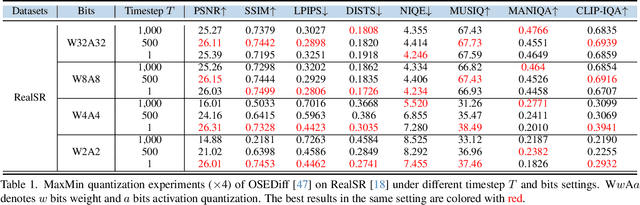
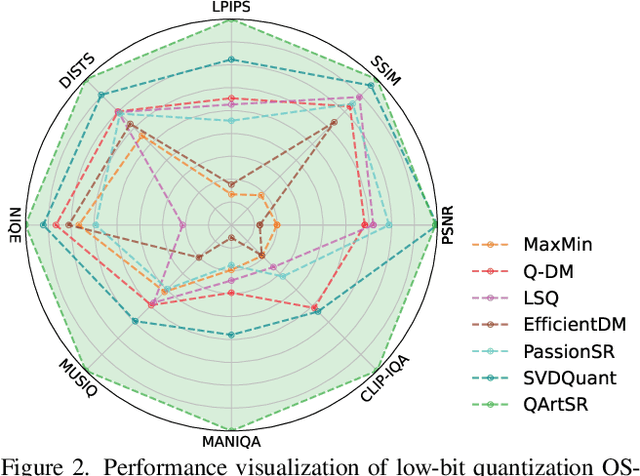
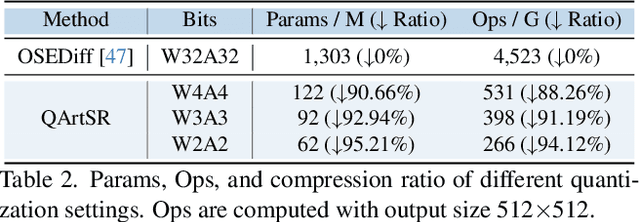
One-step diffusion-based image super-resolution (OSDSR) models are showing increasingly superior performance nowadays. However, although their denoising steps are reduced to one and they can be quantized to 8-bit to reduce the costs further, there is still significant potential for OSDSR to quantize to lower bits. To explore more possibilities of quantized OSDSR, we propose an efficient method, Quantization via reverse-module and timestep-retraining for OSDSR, named QArtSR. Firstly, we investigate the influence of timestep value on the performance of quantized models. Then, we propose Timestep Retraining Quantization (TRQ) and Reversed Per-module Quantization (RPQ) strategies to calibrate the quantized model. Meanwhile, we adopt the module and image losses to update all quantized modules. We only update the parameters in quantization finetuning components, excluding the original weights. To ensure that all modules are fully finetuned, we add extended end-to-end training after per-module stage. Our 4-bit and 2-bit quantization experimental results indicate that QArtSR obtains superior effects against the recent leading comparison methods. The performance of 4-bit QArtSR is close to the full-precision one. Our code will be released at https://github.com/libozhu03/QArtSR.
PassionSR: Post-Training Quantization with Adaptive Scale in One-Step Diffusion based Image Super-Resolution
Nov 26, 2024Diffusion-based image super-resolution (SR) models have shown superior performance at the cost of multiple denoising steps. However, even though the denoising step has been reduced to one, they require high computational costs and storage requirements, making it difficult for deployment on hardware devices. To address these issues, we propose a novel post-training quantization approach with adaptive scale in one-step diffusion (OSD) image SR, PassionSR. First, we simplify OSD model to two core components, UNet and Variational Autoencoder (VAE) by removing the CLIPEncoder. Secondly, we propose Learnable Boundary Quantizer (LBQ) and Learnable Equivalent Transformation (LET) to optimize the quantization process and manipulate activation distributions for better quantization. Finally, we design a Distributed Quantization Calibration (DQC) strategy that stabilizes the training of quantized parameters for rapid convergence. Comprehensive experiments demonstrate that PassionSR with 8-bit and 6-bit obtains comparable visual results with full-precision model. Moreover, our PassionSR achieves significant advantages over recent leading low-bit quantization methods for image SR. Our code will be at https://github.com/libozhu03/PassionSR.