 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Gradient Norm-based Fine-Tuning for Backdoor Defense in Automatic Speech Recognition
Feb 03, 2025



Backdoor attacks have posed a significant threat to the security of deep neural networks (DNNs). Despite considerable strides in developing defenses against backdoor attacks in the visual domain, the specialized defenses for the audio domain remain empty. Furthermore, the defenses adapted from the visual to audio domain demonstrate limited effectiveness. To fill this gap, we propose Gradient Norm-based FineTuning (GN-FT), a novel defense strategy against the attacks in the audio domain, based on the observation from the corresponding backdoored models. Specifically, we first empirically find that the backdoored neurons exhibit greater gradient values compared to other neurons, while clean neurons stay the lowest. On this basis, we fine-tune the backdoored model by incorporating the gradient norm regularization, aiming to weaken and reduce the backdoored neurons. We further approximate the loss computation for lower implementation costs. Extensive experiments on two speech recognition datasets across five models demonstrate the superior performance of our proposed method. To the best of our knowledge, this work is the first specialized and effective defense against backdoor attacks in the audio domain.
Fusing Pruned and Backdoored Models: Optimal Transport-based Data-free Backdoor Mitigation
Aug 28, 2024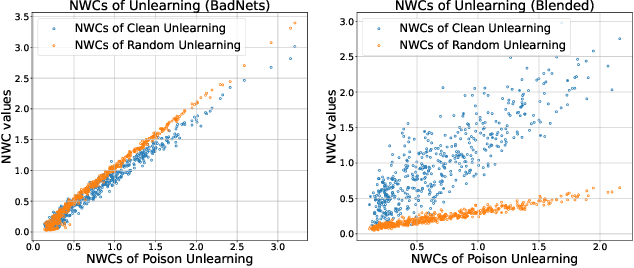
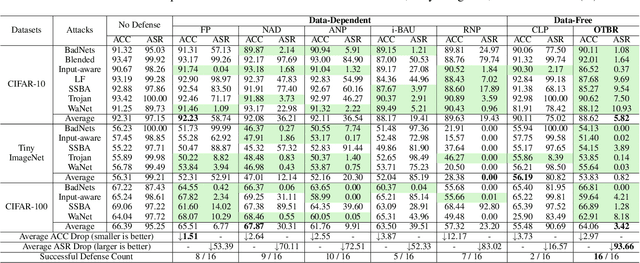
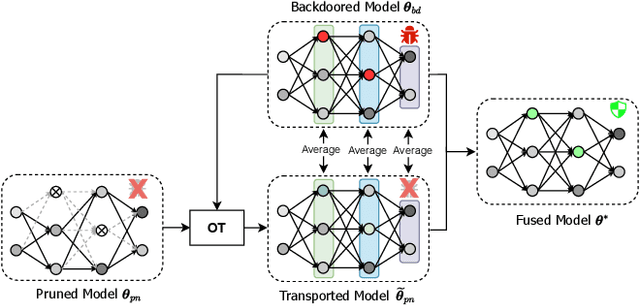
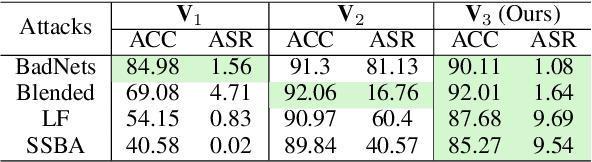
Backdoor attacks present a serious security threat to deep neuron networks (DNNs). Although numerous effective defense techniques have been proposed in recent years, they inevitably rely on the availability of either clean or poisoned data. In contrast, data-free defense techniques have evolved slowly and still lag significantly in performance. To address this issue, different from the traditional approach of pruning followed by fine-tuning, we propose a novel data-free defense method named Optimal Transport-based Backdoor Repairing (OTBR) in this work. This method, based on our findings on neuron weight changes (NWCs) of random unlearning, uses optimal transport (OT)-based model fusion to combine the advantages of both pruned and backdoored models. Specifically, we first demonstrate our findings that the NWCs of random unlearning are positively correlated with those of poison unlearning. Based on this observation, we propose a random-unlearning NWC pruning technique to eliminate the backdoor effect and obtain a backdoor-free pruned model. Then, motivated by the OT-based model fusion, we propose the pruned-to-backdoored OT-based fusion technique, which fuses pruned and backdoored models to combine the advantages of both, resulting in a model that demonstrates high clean accuracy and a low attack success rate. To our knowledge, this is the first work to apply OT and model fusion techniques to backdoor defense. Extensive experiments show that our method successfully defends against all seven backdoor attacks across three benchmark datasets, outperforming both state-of-the-art (SOTA) data-free and data-dependent methods. The code implementation and Appendix are provided in the Supplementary Material.
Unveiling and Mitigating Backdoor Vulnerabilities based on Unlearning Weight Changes and Backdoor Activeness
May 30, 2024



The security threat of backdoor attacks is a central concern for deep neural networks (DNNs). Recently, without poisoned data, unlearning models with clean data and then learning a pruning mask have contributed to backdoor defense. Additionally, vanilla fine-tuning with those clean data can help recover the lost clean accuracy. However, the behavior of clean unlearning is still under-explored, and vanilla fine-tuning unintentionally induces back the backdoor effect. In this work, we first investigate model unlearning from the perspective of weight changes and gradient norms, and find two interesting observations in the backdoored model: 1) the weight changes between poison and clean unlearning are positively correlated, making it possible for us to identify the backdoored-related neurons without using poisoned data; 2) the neurons of the backdoored model are more active (i.e., larger changes in gradient norm) than those in the clean model, suggesting the need to suppress the gradient norm during fine-tuning. Then, we propose an effective two-stage defense method. In the first stage, an efficient Neuron Weight Change (NWC)-based Backdoor Reinitialization is proposed based on observation 1). In the second stage, based on observation 2), we design an Activeness-Aware Fine-Tuning to replace the vanilla fine-tuning. Extensive experiments, involving eight backdoor attacks on three benchmark datasets, demonstrate the superior performance of our proposed method compared to recent state-of-the-art backdoor defense approaches.
A Comprehensive Survey on Segment Anything Model for Vision and Beyond
May 19, 2023



Artificial intelligence (AI) is evolving towards artificial general intelligence, which refers to the ability of an AI system to perform a wide range of tasks and exhibit a level of intelligence similar to that of a human being. This is in contrast to narrow or specialized AI, which is designed to perform specific tasks with a high degree of efficiency. Therefore, it is urgent to design a general class of models, which we term foundation models, trained on broad data that can be adapted to various downstream tasks. The recently proposed segment anything model (SAM) has made significant progress in breaking the boundaries of segmentation, greatly promoting the development of foundation models for computer vision. To fully comprehend SAM, we conduct a survey study. As the first to comprehensively review the progress of segmenting anything task for vision and beyond based on the foundation model of SAM, this work focuses on its applications to various tasks and data types by discussing its historical development, recent progress, and profound impact on broad applications. We first introduce the background and terminology for foundation models including SAM, as well as state-of-the-art methods contemporaneous with SAM that are significant for segmenting anything task. Then, we analyze and summarize the advantages and limitations of SAM across various image processing applications, including software scenes, real-world scenes, and complex scenes. Importantly, many insights are drawn to guide future research to develop more versatile foundation models and improve the architecture of SAM. We also summarize massive other amazing applications of SAM in vision and beyond. Finally, we maintain a continuously updated paper list and an open-source project summary for foundation model SAM at \href{https://github.com/liliu-avril/Awesome-Segment-Anything}{\color{magenta}{here}}.
AutoDenoise: Automatic Data Instance Denoising for Recommendations
Mar 12, 2023



Historical user-item interaction datasets are essential in training modern recommender systems for predicting user preferences. However, the arbitrary user behaviors in most recommendation scenarios lead to a large volume of noisy data instances being recorded, which cannot fully represent their true interests. While a large number of denoising studies are emerging in the recommender system community, all of them suffer from highly dynamic data distributions. In this paper, we propose a Deep Reinforcement Learning (DRL) based framework, AutoDenoise, with an Instance Denoising Policy Network, for denoising data instances with an instance selection manner in deep recommender systems. To be specific, AutoDenoise serves as an agent in DRL to adaptively select noise-free and predictive data instances, which can then be utilized directly in training representative recommendation models. In addition, we design an alternate two-phase optimization strategy to train and validate the AutoDenoise properly. In the searching phase, we aim to train the policy network with the capacity of instance denoising; in the validation phase, we find out and evaluate the denoised subset of data instances selected by the trained policy network, so as to validate its denoising ability. We conduct extensive experiments to validate the effectiveness of AutoDenoise combined with multiple representative recommender system models.